|
Клацки Р.
ПАМЯТЬ ЧЕЛОВЕКА
структуры и процессы
СОДЕРЖАНИЕ
Предисловие редактора перевода
Предисловие
Глава 1. Введение
Основные понятия
Глава 2. Общий обзор системы переработки информации у человека
Система и ее составные части
Теория двойственности памяти. Одна память или две?
Глава 3. Сенсорные регистры
Зрительный регистр
Слуховой регистр
Глава 4. Распознавание образов
Коды памяти и распознавание
Процессы, связанные с распознаванием
Внимание
Общая модель распознавания образов
Глава 5. Кратковременная память: хранение и переработка информации
Повторение
Структурирование и емкость кратковременной памяти
Сознание и кратковременная память
Глава 6. Кратковременная память: забывание
Теории забывания
Эксперименты с дистрактором
Другие эксперименты с дистрактором
Влияние познавательных процессов на забывание
Глава 7. Кратковременная память: хранение информации в неакустической форме
Зрительные коды в кратковременной памяти
Семантические коды в кратковременной памяти
Еще несколько слов о теории двойственности
Глава 8. Долговременная память: структура и семантическая переработка информации
Структура долговременной памяти
Сетевые модели долговременной памяти
Данные о семантической памяти
Теоретико-множественная модель ДП
Модель ДП, основанная на семантических признаках
Глава 9. Долговременная память: забывание
Проактивное и ретроактивное торможение
Интерференция и забывание
Забывание и естественный язык
Интерференция: некоторые итоги
Глава 10. Запоминание. Процессы кодирования
Опосредование с помощью естественного языка
Предложения и образы как посредники
Организация при свободном припоминании
Глава 11. Процессы извлечения информации
Узнавание
Извлечение информации и вспоминание
Сравнение процессов узнавания и воспроизведения
Глава 12. Зрительные представления в долговременной памяти
Память на образную информацию
Мысленные образы и память
Возражения против гипотезы образов
Существуют ли все-таки "образы"? Возможный путь к разрешению противоречия
Глава 13. Мнемонисты, шахматная игра и память
Мнемоника и мнемонисты
Список литературы
Предисловие редактора перевода
В настоящее время наметилось два подхода к изучению памяти. Один подход можно
назвать психофизиологическим: начиная с анализа памяти человека на
психофизическом уровне, исследование переходит затем к раскрытию ее ней.ронных механизмов.
Объединение результатов, полученных на
психофизическом и нейронном уровнях, завершается построением модели, к
которой предъявляются весьма жесткие требования. Модель памяти, построенная
из нейроноподобных элементов, должна как целое обладать свойствами, обнаруживаемыми на психофизическом уровне. Вместе с тем каждый
нейроноподобный элемент должен обладать характеристиками того реального
нейрона, функциональную роль которого он имитирует в модели. Такие жесткие
требования, предъявляемые к модели, приводят к отбору среди всех моделей именно тех, которые наиболее близки к реальным структурам, В
общем виде психофизиологический анализ можно представить схемой:
"человек-нейрон-модель".
Другой подход принято называть собственно психологическим. В этом случае исследователь
ставит перед собой задачу установить те закономерности памяти, которые обнаруживаются
на психофизическом уровне. Нейронные механизмы при этом не учитываются. Теоретическое
обобщение в этом случае также завершается построением модели. Однако круг возможных
моделей здесь значительно шире, чем при психофизиологическом подходе, поскольку
от модели требуется воспроизведение процессов памяти в самом общем виде. Именно
такой психологический подход к проблеме памяти и представлен в книге Р. Л. Клацки.
Особенностью книги является то, что память рассматривается в ней с точки зрения
информационных процессов в рамках когнитивной психологии. В отличие от бихевиоризма,
построенного на принципе "стимул-реакция", когнитивная психология подчеркивает
значение иерархически организованной системы познавательных процессов. Эта система
мыслится в виде блоков перекодирования и хранения информации. При этом информационные
преобразования рассматриваются в самом общем виде, без введения строгих мер
их оценки. В последние годы на когнитивную психологию сильное влияние оказало
развитие вычислительной техники. Это отразилось на используемой автором терминологии.
Модели, которые составляют концептуальную структуру книги, такжево многом заимствованы
из области теории ЭВМ.
При сопоставлении психофизиологического подхода к изучению памяти с когнитивно-информационным
прежде всего бросается в глаза то, что модели, рассматриваемые в рамках второго
из этих подходов, достаточно произвольны. Естественным шагом на пути их уточнения
должно быть обращение к тем нейронным механизмам мозга, с помощью которых реализуются
процессы памяти. Другими словами, прогресс когнитивно-информационного подхода
связан с движением в направлении психофизиологического анализа памяти.
В чем же
тогда состоит значение когнитивно-информационного подхода? Дело в том, что
значительная часть процессов памяти, включая смысловые преобразования,
столь сложна, что в настоящее время еще не может быть интерпретирована на основе нейронных закономерностей. Когнитивноинформационный
метод обеспечивает достаточно эффективный подход к анализу этих сложных
форм памяти.
В книге Р. Л. Клацки рассматриваются три уровня памяти: иконическая, кратковременная
и долговременная. Особые трудности возникают при анализе долговременной памяти.
Этот уровень предполагает смысловую переработку данных и их обобщение. Однако
факты говорят о сохранении в долговременной памяти многих деталей восприятия.
Автор по существу так и не дает ответа на вопрос, что же именно хранится в долговременной
памяти и как понятийный аспект памяти связан с наглядным ее аспектом. Следует
подчеркнуть, однако, что это отражает реальные трудности, возникающие при изучении
данной проблемы.
Книга содержит большой экспериментальный материал, подробно описанный и хорошо
систематизированный. Читатель найдет много нового относительно таких еще мало
изученных форм памяти, как иконическая и экоическая память. В книге детально
рассмотрена проблема проактивного и ретроактивного торможения. Значительный
интерес представляет описание опытов с измерением "субъективных расстояний"
между следами, хранимыми в памяти. Этот подход позволяет установить принципы
организации следов памяти, представляя их точками в многомерном пространстве,
образованном ведущими признаками. Значительный прогресс в изучении памяти был
достигнут благодаря использованию здесь тех приемов, которые оказались ранее
эффективными при изучении сенсорных порогов. Это прежде всего относится к статистической
теории принятия решений. Использование рабочей характеристики приемника применительно
к процессу узнавания позволило выделить в акте узнавания две величины: близость
сигнала к одному из следов памяти и критерий, определяющий принятие решения
относительно их соответствия друг другу.
В конце книги рассмотрено участие памяти
в шахматной игре.
В заключение следует подчеркнуть, что в книге Р.
Клацки рассматриваются и вопросы эффективности обучения. Особое внимание
обращается на положительный эффект структурирования данных и организации
материала для удержания его в памяти.
Книга не только знакомит
читателя с современным состоянием проблемы памяти, но и побуждает к
дальнейшему изучению этого вопроса.
Е. Н. Соколов
ПОСВЯЩАЕТСЯ ПАМЯТИ
АРНОЛЬДА КЛАЦКИ
Предисловие
Каждый из нас обладает памятью. Мы пользуемся ею с такой легкостью, что очень
редко сами поражаемся своей способности приобретать знания и использовать их.
Между тем человеческая память — нечто очень сложное, и хотя психологи изучают
ее на протяжении многих лет, они едва только начинают постигать всю ее сложность.
Но все же в последние два десятка лет в результате изучения человеческой памяти
складывается все более ясная картина соответствующей функциональной системы;
вот эту-то постепенно вырисовывающуюся картину мы и попытаемся описать в данной
книге.
Память рассматривается здесь как информационная система, непрерывно
занятая приемом, видоизменением, хранением и извлечением информации. При
таком подходе восприятие и научение относятся к области памяти и поэтому
тоже частично обсуждаются в данной книге. Мы не пытались затронуть все
вопросы, которые могут интересовать тех, кто занимается изучением памяти,
однако отобранные нами темы позволяют довольно широко обрисовать современное
состояние исследований и теоретических представлений в этой области.
Сначала мы рассмотрим восприятие, затем перейдем к вопросам, касающимся
"кратковременной памяти", а в заключение рассмотрим
"долговременную память", куда входят семантическая память, модели
кодирования и извлечения информации и забывание.
Большую помощь в
написании этой книги мне оказали рецензенты. Я приношу благодарность Ричарду
Эткинсону, Роберту Краудеру, Дугласу Хинцману, Эрлу Ханту, Джеймсу
Джуоле, Томасу Ландауэру и Эдуарду Смиту за их критические замечания. Эти
замечания, не всегда лестные, были неизменно полезными, и я убеждена, что
книга выиграла благодаря советам, которые я получила. Я хочу поблагодарить Бака Роджерса за его указания и помощь, а также Джима Гейвица за
внимание, поддержку и дружеское участие, проявлявшиеся им на всем
протяжении работы над этой книгой.
Роберта Л. Клацки
Глава 1
Введение
Что значит вспоминать? Как сказал однажды знаменитый
психолог Уильям Джеймс, вспоминать-это значит думать о чем-нибудь, что
было пережито в прошлом и о чем мы непосредственно перед тем не думали
(James, 1890). Определение Джеймса на первый взгляд кажется удачным, но
все же понятие "память" не так-то просто определить одной фразой.
Эта книга посвящена проблеме памяти. В ней обсуждаются вопросы о том, в какой
форме мы внутренне сохраняем наши знания об окружающем мире; как мы получаем
доступ к этим знаниям, когда в них возникает надобность; почему нам не всегда
удается добраться до них; каким образом мы включаем новую информацию в систему
уже накопленных знаний. Каждый из этих вопросов составляет часть проблемы памяти,
и в книге будут рассмотрены некоторые методы, используемые психологами при изучении
этой проблемы. Попутно будет затронут ряд разнообразных тем и идей, каждая из
которых непосредственно связана с главным интересующим нас вопросом что значит
помнить (запоминать, вспоминать)?
Подход к изучению человеческой памяти, принятый в этой книге, часто называют
когнитивным или информационным подходом. Мы лучше поймем, что это значит, если
сравним принятый нами когнитивный подход с более старым, но все еще не изжившим
себя подходом, основанным на идеях ассоциационизма или на теории "стимул-реакция".
Согласно этой теории, способность вспоминать — это результат образования ассоциаций,
или связей, между стимулами и реакциями, причем от прочности таких связей (называемой
прочностью навыка) зависит легкость припоминания. Если возникла достаточно устойчивая
связь (как, например, связь между "2x2=" и "4"), можно говорить о наличии прочного
следа памяти; тип этого следа зависит от тех стимулов и реакций, которые в нем
участвуют.
Например, большинство из нас почти всегда помнит о том, то следует останавливать
машину на красный свет. Эту привычку можно приписать тому, что у нас имеется
ассоциация между определенным стимулом (красным светом) и определенной реакцией
(нажатием на тормоз). Конечно, мы взяли довольно простой пример-почти всякое
животноеможет научиться останавливаться при виде красного света и в этом смысле
обладает памятью. Но ассоциационисты утверждают, что теория "стимул — реакция"
позволяет объяснить также более тонкие и сложные формы человеческого поведения.
Этого можно достигнуть, в частности, допустив существование внутренних стимулов
и реакций, т. е. таких стимулов и реакций, которые нельзя наблюдать непосредственно
(и которые, следовательно, не похожи на красный свет или нажатие на тормозную
педаль). В сущности многие реакции человека на то, что его окружает, являются,
вероятно внутренними, а если и выражаются внешне, то слишком слабо, чтобы их
можно было заметить. Эти скрытые реакции могут служить стимулами для других
реакций; таким путем могли бы возникать цепи стимулов и реакций, недоступные
наблюдению. Это позволяет распространить теорию на более сложные психические
процессы.
Однако ассоциационистский подход сталкивается с рядомтрудностей.
Во-первых, ассоциационисты концентрируют внимание на самом факте св.язи
между стимулом и реакцией и на законах выработки условных реакций —
стремятся выяснить, как происходит образование ассоциаций и как можно
регулировать прочность навыка. Они почти ничего не могутсказать о
событиях, происходящих в промежутке между стимулом и реакцией. Во-вторых,
ассоциационистский подход не смог сколько-нибудь приблизить нас к пониманию
многих: наиболее интересных явлений, связанных с памятью: попрежнему
остается неясным, как мы строим гипотезы и проверяем их; почему мы так
часто не можем вспомнить какоето слово, хотя оно "вертится на кончике
языка"; каким образом мы вызываем в памяти образы знакомых лиц и так
далее.
При изучении памяти как компонента познавательной деятельности главный акцент
значительно смещается по сравнению с ассоциационистским подходом. Прилагательное
"когнитивный", происходящее от слова cognitio, т. е. знание, подчеркивает, что
речь идет о психических процессах, а не просто о стимулах и реакциях. Именно
этот сдвиг-переход от представления о пассивной системе, воспринимающей стимулы
и автоматически создающей цепи "стимул-реакция", к понятию о психической активности-характеризует
когнитивные теории памяти. Согласно Нейссеру, который своей книгой "Когнитивная
психология" (Neisser, 1967) дал под.линный толчок развитию этого подхода, в
когнитивной теории памяти центральное место занимает проблема знания-способы
приобретения знаний, их видоизменения, обращения с ними, использования, хранения,
т. е" короче говоря-способы их переработки в человеческом организме. Таким образом,
термин "переработка информации" (который те, кто занимается психологией познания,
позаимствовали у специа-листов по вычислительным машинам) охватывает все аспекты
активного взаимодействия человека с информацией об окружающем мире. Центральную
роль в этом процессе переработки играют психические процессы, происходящие в
период между стимулом и реакцией. Эти процессы не рассматриваются просто как
связующие звенья в цепи "стимулреакция" (хотя, как мы увидим в дальнейшем, понятие
ассоциации находит себе место и в когнитивной психологии).
Хабер (Haber, 1969) указал
на ряд основных предположений, с которыми связан информационный подход в
психологии. Слегка видоизменив, их можно сформулировать как
1) предположение о поэтапной переработке информации и 2) предположение об
ограниченной емкости соответствующих систем, из которого вытекает
представление о непрерывности процессов переработки информации.
Рассмотрим сначала первое из этих предположений. Мы "исходим из того, что зучаемыи
процесс — переработку некоторой информации — можно разбить на ряд подпроцессов
или этапов. Иными словами, промежуток между стимулом и реакцией можно разделить
на более короткие интервалы, каждый из которых, соответствует какой-то подгруппе
промежуточных событий. Как мы увидим, информация при переходе от одного этапа
к другому может подвергаться удивительным преобразованиям. Возвращаясь к нашему
примеру с красным светом, мы можем разбить весь процесс на следующие этапы:
во-первых, наша зрительная система регистрирует красный свет; во-вторых, мы
распознаем данное зрительное ощущение как то, что оно представляет собой на
самом деле, — как красный свет светофора (для этого мы должны использовать информацию,
хранящуюся в нашей памяти, т. е. знание того, как выглядит красный сигнал светофора);
в-третьих, мы применяем правило, котрое хранится у нас в памяти: "Увидев красный
сигнал, останови машину". Конечно, весь этот процесс при желании можно подвергнуть
дальнейшему дроблению. Но обратите внимание на то, что на описанных этапах первоначальная
информация (зрительный: сигнал) подверглась последовательным преобразованиям.
Из зрительного ощущения она превратилась в распознаваемую категорию (восприятие
красного света), после чего вновь изменилась, превратившись в условие, требующее
применения определенного правила (останови машину, когда...). Этот пример иллюстрирует,
общее положение: выделение того или иного этапа в процессе переработки информации
не должно бйт произвольным: каждый этап этого процесса (называемый "иногда уровнем
переработки) обычно соответствут тому или иному представлению информации, которую
несет данный стимул. При переходе информации от одного этапа к другому соответственно
изменяется и ее представление.
Пример с красным светом можно рассмотреть и с точки зрения информационной емкости
системы. Цля каждого этапа можно установить "известные пределы способности человека
к переработке информации. Если, например, добавить к красному свету регулировщика
уличного движения, нескольких беспечных пешеходов и машину скорой помощи, то
всех этих стимулов может оказаться слишом много для того, чтобы зрительная система
была способна зарегистрировать их в одно и то же время. В результате возникнет
перегрузка сенсорного регистра, а такого рода перегрузки могут приводить к различным
осложнениям. Прежде всего часть информации может не поступить в систему (может
случиться, что мы вообще не заметим одного из пешеходов или даже красный свет).
Или же мы могли бы перекодировать стимульную ситуацию, т. е. преобразовать ее
в некоторый новый стимул (например, воспринять ее просто как "опасную ситуацию").
Наконец, возможна также более избирательная переработка информации-мы могли
бы направить все свое внимание на регулировщика, не замечая ни сигнала светофора,
ни пешеходов, ни машины скорой помощи.
Из двух только что описанных основных предположений вытекает важное следствие:
подходя к памяти как к процессу переработки информации, мы неизбежно вторгаемся
в такие области психологии, которые обычно отделяли от изучения памяти. Научение,
например, можно рассматривать как: процесс пополнения или изменения системы
человеческой памяти. Восприятие (т. е. первоначальная регистрация стимула) также
неотделимо от памяти и может рассматриваться как первая ступень в непрерывном
процессе переработки информации.
Почему
описываемый здесь подход получил название "когнитивной психологии"?
Познавательный характер этого подхода, как мы уже упоминали, основан на
представлении о человеческом организме как о системе, занятой активными
поисками сведений и переработкой информации, т. е. на представлении о
том, что люди оказывают на информацию разного рода воздействия. Например,
перерабатывая информацию, человек может решать, подлежит ли она
перекодированию в какую-то иную форму, отбирать определенную
информацию для дальнейшей переработки или же исключать некоторую
информацию из системы. Как мы увидим, такое представление о человеке как о
системе, активно перерабатывающей информацию, пронизывает все новейшие
теории памяти. Сторонники когнитивного подхода к изучению памяти
рассматривают восприятие и вспоминание как творческие акты, при помощи
которых человек активно создает мысленные образы окружающего мира.
ОСНОВНЫЕ ПОНЯТИЯ
Прежде чем приступать к изучению памяти, необходимо условиться о нескольких
основных понятиях и определениях. Начнем с разграничения трех главных терминов,
заимствованных из кибернетики и применяемых при рассмотрении человеческой памяти:
кодирование, хранение и извлечение информации. Кодирование означает
способ введения информации в систему. Процесс кодирования может сопровождатся
преобразованием информации в надлежащую форму, соответствующую той системе (будь
то человек или машина), в которую ее собираются ввести (например, для вычислительной
машины информацию можно закодировать, пробивая дырки в стандартных перфокартах).
Способ кодирования сохраняемой информации нередко называют "кодом" памяти. Хранение
в точности соответствует обычному смыслу этого слова, означая хранение информации
в какой-либо системе; конечно, с хранящейся в памяти информацией может что-нибудь
происходить: она может изменяться под влиянием информации, поступающей позднее,
или совсем утрачиваться. Извлечением называют действие, направленное
на то, чтобы получить доступ к хранящейся информации. Любой из этих трех процессов
может по той или иной причине расстроиться — у человека это приводит к невозможности
вспомнить то или иное событие. Отсюда следует, что для успешного припоминания
все три процесса должны быть в порядке: мы должны закодировать информацию, хранить
ее до тех пор, пока она не понадобится, а затем иметь возможность вновь извлечь
ее.
Еще один термин, который будет часто встречаться в книге,- это "модель", в частности "модель памяти". Здесь имеется в виду теоретическая модель. Так, применительно к рассмотренному
выше примеру можно сказать, что мы строим модель психических процессов,
происходящих в то время, когда человек тормозит машину при красном свете.
Иногда теоретическая модель превращается в "математическую", т. е.
в нее вводят математику, для того чтобы описать интересующие нас процессы
более подробно. Одно из преимуществ, которое дает создание модели того или
иного психического процесса, состоит в том, что модель позволяет делать
проведения, йтём эти"предсказания можно сравнить с реальным поведением
людей, и если они окажутся ошибочными, это будет означать, что нужно
строить новую модель.
МЕТОД ЗАУЧИВАНИЯ СПИСКОВ
Рассматривая память человека, мы будем описывать результаты многих экспериментов,
в которых используются обычные экспериментальные методы. В данной книге мы будем
обращаться не только к этим методам, однако их можно считать в известной мере
стандартными, и они используются во многих экспериментах. Все эти методы имеют
общую основу: в каждом из них испытуемый (лицо, на котором проводят эксперимент)
заучивает предъявляемые ему списки элементов. Такими элементами могут
быть отдельные слова, пары слов или "бессмысленные слоги". (Бессмысленные слоги
называют также С-Г-С — "согласная-гласная-согласная", по обычному способу их
построения; таковы, например, сочетания ДАК, БУП или ЛОК.) Заучивание ряда элементов
происходит путем многократных попыток - проб. Каждая проба состоит
из предъявления испытуемому ряда элементов и последующего воспроизведения, при
котором выясняется, что он смог запомнить.
Метод заучивания списков ввел Герман Эббингауз (ЕЬbinghaus, 1885), который
впервые занялся систематическим изучением процессов запоминания и забывания.
Эббингауз произвел многочисленные эксперименты на одном испытуемом-на самом
себе. В своих экспериментах он заучивал ряды бессмысленных слогов. Именно Эббингауз
придумал эти слоги; он это сделал потому, что хотел устранить из эксперимента
нежелательный с его точки зрения фактор — смысл. Эббингауз считал,
что если он будет использовать для составления своих рядов настоящие слова,
то смысл этих слов повлияет на результаты экспериментов. А он хотел изучить
образование и сохранение в памяти новых ассоциаций, независимых от
уже существующих. Чтобы избежать этого нежелательного источника "искажений",
он решил использовать бессмысленные слоги, считая их отностельно свободными
от каких-либо смысловых ассоциаций.
Эббингауз составил ряды бессмысленных слогов, которые nон предъявлял самому
себе с некоторой постоянной скоростью. Он читал эти ряды до тех пор, пока ему
не казалось, что он их заучил, и в некоторых случаях он действительно мог безошибочно
воспроизвести их по памяти. Спустя некоторое время он вновь производил такую
самопроверку. Количественной мерой забывания служило число дополнительных повторений,
необходимых дл того, чтобы вновь заучить те же ряды по прошествии известного
времени. Это позволяло судить, какая часть заученного сохранялась в памяти.
Эббингауз внес многообразный вклад в изучение памяти. Он не только создал экспериментальные
методы, позволяющие устранить источники ошибок; применяя эти методы, он открыл
много нового относительно человеческой памяти и процесса заучивания. Одно из
важных открытий Эббингауза заключалось в том, что если ряд элементов не слишком
велик-скажем, содержит всего семь или меньше элементов,то его удается запомнить
с одного прочтения. Если же увеличить число элементов до восьми и более, то
время, необходимое для заучивания, резко возрастает. На уровне семи элементов
существует какой-то "перелом"-ниже этого уровня для запоминания достаточно одного
прочтения, а выше требуется уже несколько предъявлений, число которых возрастает
с увеличением числа элементов.. Предельное число (семь) элементов, запоминаемых
сразу, называют объемом памяти, и мы рассмотрим его более подробно
в гл. 2.
Другое
важное открытие Эббингауза состояло в том, что количество сохраняющегося в
памяти материала зависит от промежутка времени между первоначальным
заучиванием и последующей проверкой. Оказалось, что оно больше при коротком промежутке и с течением времени неуклонно уменьшается, т. е.
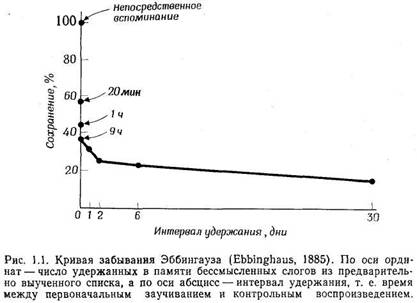
количество забытого материала со временем возрастает. Кривая забывания
представлена на рис. 1.1. Можно видеть, что в первые несколько минут
забывание происходит очень быстро (т. е. количество сохраняющегося
материала быстро убывает), но постепенно скорость забывания снижается.
Первоначальный метод, созданный Эббингаузом, сходен с тем, что сейчас называют
методом заучивания последовательностей. При этом методе испытуемый должен запомнить
ряд элементов, расположенных в определенном порядке. Допустим, например, что
наш ряд очень невелик- КНИГА ТРУБКА, КОНУС, ДОСКА, ПРОСТЫНЯ. Эти пять слов предъявляют
испытуемому, после чего он должен повторить их в той же последовательности.
Если он забыл одно из слов или назвал его не на своем месте, это
засчитывают как ошибку.
Запоминание последовательностей можно проверять двумя способами. Один способ
состоит в том, что испытуемому предъявляют весь ряд, а затем проверяют, насколько
хорошо он его запомнил. Этот метод называется методом заучивания-воспроизведения,
поскольку испытуемый сначала заучивает ряд-элементов, а затем подвергается проверке
по всему ряду в целом. Другой способ называют методом антиципации.
При этом способе испытуемый, вместо того чтобы заучивать сразу весь ряд и затем
пытаться воспроизвести его целиком, воспроизводит и запоминает один элемент
за другим. Для этого ему предлагают попытаться называть каждый элемент до того,
как он его увидит. Вначале ему предъявляют какой-либо маркер (например, звездочку),
обозначающий начало ряда. Увидев маркер, испытуемый пытается назвать первый
элемент ряда (это проверка по первому элементу). Затем испытуемому предъявляют
первый элемент (запоминание), и он пытается назвать второй элемент (проверка
по второму элементу), и так далее по всему ряду. В первый раз испытуемый, конечно,
почти наверное не сумеет назвать ни один из элементов, но в конце концов, после
нескольких проб, он начнет хорошо справляться с задачей.
Установлено, что на запоминание последовательностей влияют многие факторы.
Один из них-это скорость предъявления элементов (Эббингауз, как вы помните,
предъявлял их с постоянной скоростью). Обычно при меньших скоростях предъявления
заучивание происходит быстрее. Другая важная особенность запоминания последовательностей
состоит в том, что легкость запоминания данного элемента зависит от его места
в ряду (т. е. ттросто от того, будет ли это первый элемент, второй и т. д.).
Число ошибок при воспроизведении средних элементов ряда больше, чем для первых
или последних элементов. Этот эффект получил название позиционного эффекта
(serial-position effect), и он имеет место при рядах любой длины, превышающей
объем памяти.
Другой метод, часто используемый в экспериментах по изучению памяти — это
метод парных ассоциаций; характерная черта его состоит в том, что каждый
элемент представляет собой комплекс, состоящий из двух частей. Например, элемент
может состоять из слова и числа (скажем, "КНИГА-7"). После запоминания таких
пар испытуемый должен называть вторую часть элемента, когда ему предъявляют
первую (скажем, на слово "КНИГА" он отвечает "7"). Обычно при методе парных
ассоциаций элементы не заучиваются в определенном порядке. Их последовательность
от одной пробы к другой может изменяться, но сами пары остаются постоянными.
Например, элементы КНИГА-7 и СОБАКА-8 в одной пробе могут идти друг за другом,
а в другой могут быть разделены несколькими другими элементами; однако КНИГА
всегда сочетается с 7, а СОБАКА-с 8.
Так же как и простая последовательность элементов, список парных сочетаний
может заучиваться с помощью либо метода заучивания-воспроизведения, либо метода
антиципации. В первом случае сначала предъявляют все элементы, а затем проверяют
их запоминание. Проверка обычно состоит в предъявлении только первых частей
элементов, а испытуемый пытается в своем ответе назвать вторые их части. Например,
экспериментатор предъявляет "КНИГА-?", а испытуемый отвечает "7". При методе
антиципации (как и при заучивании последовательностей) испытуемому предлагают
назвать один элемент до его предъявления, после чего предъявляют этот элементгптри
пргд лиги ют, "цазвать другой элемент, после чего предъявляют его, и так далее.
Контрольное воспроизведение здесь предшествует заучиванию. Например, испытуемому
предъявляют "КНИГА-?" в качестве проверки элемента КНИГА — 7. После этого ему
предъявляют "КНИГА-7" (возможность заучить элемент). Затем ему могут предложить
в качестве проверки "СОБАКА — ?", после чего предъявят "СОБАКА — 8", и так далее.
Одно из предполагаемых достоинств метода парных ассоциаций-то, что один элемент
можно рассматривать при этом и как стимул (первая часть), и как реакцию (вторая
часть). По мнению некоторых теоретиков, этот метод дает возможность непосредственно
изучать ассоциации между стимулом и реакцией. Мы увидим, однако, что само по
себезапоминание данного элемента еще нельзя расценивать как свидетельство установления
простой связи между стимулом и реакцией. Испытуемые нередко заучивают элемент
в результате опосредования, заключающегося в том, что они изменяют
элементы каким-то им одним свойственным способом. Например, элемент "КОШКА-М"
может быть мысленно превращен в "КОШКА-МЫШКА". В данном случае запоминается
совершенно не то, что содержится в прямой ассоциации "КОШКА-М".
Третий метод — это свободное припоминание. При свободном припоминании
в отличие от воспроизведения последовательностей испытуемый может называть элементы
в любом порядке. Если один и тот же ряд элементов используют в нескольких пробах,
то порядок их предъявления каждый раз изменяют. (Эксперименты на свободное припоминание
обычно проводят методом заучивания-контрольного воспроизведения, так как метод
антиципации неизбежно фиксирует порядок, в котором следует называть элементы
ряда, т. е. вводит именно то, что при свободном припоминании нежелательно.)
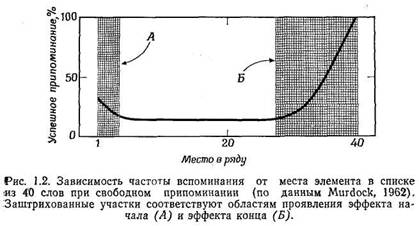
Так же как и при воспроизведении последовательностей, при свободном припоминании
наблюдается позиционный эффект (рис. 1.2), т. е. элементы, расположенные в начале
и конце ряда, вспоминаются относительно чаще, чем элементы, находящиеся в середине
ряда. Как показано на рис. 1.2, разные отрезки кривой зависимости числа успешных
воспроизведении от места данного элемента в ряду имеют особые названия. Отклонение
вверх кривой, соответствующее первым элементам ряда, называют эффектом начала,
а отклонение, соответствующее нескольким последним элементам, называют эффектом
конца.
Еще один метод, связанный с заучиванием рядов, — это тест на узнавание.
Этот метод отличается от других формой проверки. Испытуемому предъявляют различные
слова из тех, которые он запоминал, и просят его сказать, узнаёт ли он их как
элементы первоначального ряда. Таким образом, для метода узнавания характерно
то, что испытуемому при проверке снова предъявляют некоторый ряд элементов,
вместо того чтобы предложить ему вспоминать их. Конечно, если бы ему предъявляли
только те элементы, которые входили в запоминаемый список, то он мог бы всякий
раз говорить "Да, это было" и не делал бы ошибок. Чтобы действительно проверить
его способность узнавать элементы, входившие в список, нужно включить в число
тест-элементов так называемые дистракторы — элементы, которых не было
в первоначальном списке.
Испытуемого можно, например, проверять методом "да-нет". Ему предъявляют один
за другим ряд элементов, и он должен говорить "да", если, по его мнению, данный
элемент уже содержался в списке, или "нет", если ему кажется, что этого элемента
в списке не было. Обычно половину предъявляемых элементов составляют элементы,
входившие в список, а другую половину — дистракторы. Метод "да-нет" аналогичен
методу "верно-неверно", применяемому в школах.
Другой формой теста на узнавание служит метод вынужденного выбора.
При этом методе испытуемому каждый раз предъявляют не один, а одновременно два
или несколько элементов. Один из них входил в первоначальный список, а остальных
там не было. Испытуемый должен выбрать тот элемент, который был в списке. Если
испытуемому предъявляют по два элемента, это будет тест с "двухальтернативным
вынужденным выбором", если по три элемента-то с "трехальтернативным" выбором
и так далее. Как вы могли заметить, метод вынужденного выбора — это один из
вариантов метода множественного выбора.
Наконец, тест на узнавание можно проводить, предъявляя испытуемому всё сразу,
т. е. все слова, входившие в список, и все дистракторы. При этом испытуемый
пытается указать, какие слова входили в первоначальный список. Нередко все элементы,
используемые при такой проверке, печатают на листе бумаги и предлагают испытуемому
подчеркнуть те слова, которые, по его мнению, были в списке.
Важно отметить, что тест на узнавание иногда применяют в сочетании с другими
описанными выше методами. Например, его можно комбинировать с методом парных
ассоциаций, предъявляя испытуемому член каждой пары, служащий стимулом, в сопровождении
нескольких членов, могущих служить реакцией. Скажем, испытуемому, которому раньше
предъявляли элемент ДАК-7, можно предъявить при проверке
ДАК-? 5 8 7 1 (выбрать одно) .
Проверку на узнавание можно также сочетать с запоминанием
последовательности. В этом случае можно попросить испытуемого указать, в
катом из предъявленных ему рядов элементы расположены в том порядке, в
котором они предъявлялись ранее.
Итак, основные процедуры при
заучивании списков можно определить следующим образом:
1. При
запоминании последовательности элементы заучиваются в определенном
порядке.
2. При запоминании парных ассоциаций элементы в списке
расположены парами.
3. При свободном припоминании элементы списка можно
называть в любом порядке.
4. При проверке на узнавание испытуемому
предъявляют некоторую группу элементов.
Что касается метода запоминания последовательностей, то в этой книге мы его
почти не будем касаться, однако все остальные методы играют важную роль в изучении
интересующих нас вопросов. Например, задачи на парные ассоциации имеют большое
значение при иоследовании забывания (гл. 9); метод свободного припоминания широко
используется в экспериментах, связанных с изучением организации памяти (гл.
10), а задачи на узнавание занимают видное место при рассмотрении теорий извлечения
информации (гл. 11).
Глава 2
Общий обзор системы переработки информации у человека
В первой главе человеческая память была охарактеризована как система, перерабатывающая
информацию были отмечены две важные черты подобной системы 1) возможность разбить
переработку информации на ряд этапов, и 2) ограниченность объема информации,
перерабатываемой на каждом этапе. В данной главе мы рассмотрим систему переработки
информации у человека более подробно. Будет предложена возможная теоретическая
модель этой системы. В последующих главах эта первичная модель будет значительно
расширена, однако сейчас нам важно получить общее представление о системе.
СИСТЕМА И ЕЕ СОСТАВНЫЕ ЧАСТИ
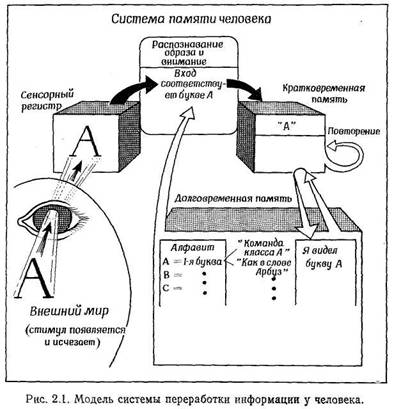
Одна из возможных моделей системы, перерабатывающей информацию у человека,
представлена на рис. 2.1. Приведенная здесь схема отражает в общих чертах то,
что происходит с информацией о каком-либо стимуле, поступившем из "реального
мира", при его прохождении через систему.
На первом этапе, непосредственно после предъявления стимулатттвестное.коглячест
информации относительно этого стимула (который только что возник за пределами
системы) регистрируется, или вводится в систему. Место, где происходит эта регистрация,
мы назовем "сенсорным регистром". Это название отражает тот факт, что информация
поступает в систему через один (или несколько) из пяти имеющихся у человека
органов чувств и в течение короткого временя сохраняется в сенсорной форме (например,
звук — в форме слухового сигнала); таким образом, для каждого из органов чувств
имеется свой сенсорный регистр. Информация может некоторое время оставаться
в таком регистре, но чем дольше она там остается, тем слабее становится след,
пока, наконец, он не исчезнет полностью. Это постепенное ослабление сенсорного
следа называется угасанием, и именно оно ограничивает емкость системы
на этом этапе — ее лимитируют продолжительность времени, в течение которого
след может сохраняться в регистре, не угасая.
В то время, пока информация находится в сенсорном ретистре, вступает в действие
ряд важных процессов. Один из них — это распознавание образов, сложный
процесс, возникающий в результате контакта между информацией, находящейся в
сенсорном регистре, и информацией,накопленной в прошлом. Образ считается распознанным,
если удается тем или иным способом установить соответствие его сенсорных признаков
каким-либо определенным понятиям. В более узком смысле "распознавание образов"
означает называние. Если мы даем стимулу определенное название, например "буква
А", то это значит, что мы восприняли определенную зрительную информацию — (установили,
что стимул — равнобедренный треугольник, две боковые стороны которого продолжены
за его основание) и сопоставили ее с известным нам понятием ("буква А"). Однако
распознавание образа не всегда означает называние (мы можем распознавать некоторые
образы, не умея называть их); поэтому лучше понимать распознавание образов в
более общем смысле — как приписывание данному стимулу определенного значения.
С распознаванием образов тесно связан другой процесс, называемый вниманием.
Слово "внимание" в психологии познавательных процессов имеет несколько значений.
Оно может означать "ожидание" — например, когда вы прислушиваетесь, ожидая телефонного
звонка. Другой смысл этого слова — просто "емкость" (информационных каналов):
"уделить внимание" какому-то стимулу иногда просто означает "выделить для него
часть имеющейся ограниченной емкости системы". Слово "внимание" может также
означать особое выделение некоторой информации, когда мы стремимся сосредоточиться
на чем-то определенном, а не рассеиваться. (Вам, например, следует сосредоточить
свое внимание на том, что говорит преподаватель, если вы не хотите упустить
важную информацию, содержащуюся в его лекции.) Именно этот последний вид внимания,
часто называемый "избирательлым вниманием", представляет для нас наибольший
интерес.
Поступившие в систему входные сигналы, после того как они были распознаны
и стали объектом внимания (мы настроились на них), могут подвергнуться следующему
этапу переработки. На этом этапе информация хранится в течение недолгого срока
в кратковременной памяти (КП) — примерно так же, как она удерживалась
в одном из сенсорных регистров, с той разницей, что теперь она уже не находится
в первоначальной, т. е. сенсорной, форме.Например, буква А представлена в КП
уже не в виде какого-то нераспознанногозрительного стимула, а именно как буква
А. Другое различие между сенсорным регистром и КП — это длительность возможного
хранения информации. В зрительном регистре след угасает довольно быстро, примерно
за секунду, тогда как в КП он может удерживаться неопределенно долго благодаря
процессу, называемому "повторением". Повторениедает возможность снова и снова
пропускать информацию через КП; при этом информация освежается и полного ее
угасания не происходит. Однако без такого повторения содержащаяся в КП информация
теряется, подобно тому как она угасает в сенсорном регистре, и это ограничивает
емкость системы. Фактически для кратковременной памяти существует два ограничения:
ограничено число стимулов, которые могут одновременно удерживаться
в КП при помощи повторения, и время, в течение которого данная единица
может удерживаться в КП без повторения. Потеря информации из КП представляет
собой один из типов "забывания" (термин "забывание" означает утрату информации
из любого участка системы памяти).
Наконец, информация из КП может переводиться на более глубокие уровни системы,
где она может сохраняться практически бесконечно, — в так называемую долговременную
память (Д П). В долговременной памяти хранится огромное количество самой разнообразной
информации: значения всевозможных слов; события, случившиеся позавчера; имена
людей, с которыми мы знакомы; названия обычных предметов; правила грамматики
и так далее. В сущности, она содержит все, что нам известно об окружающем мире.
Из этого краткого опичсания системы памяти становится ясно, что нам лридется
иметь дело с двумя совершенно разными вещами. С одной стороны, имеются хранилища
информации-сенсорные регистры, КП и ДП; это неотъемлемые части самой системы,
ее структурные компоненты. С другой стороны, мы упоминали о таких процессах,
как внимание к стимулу, распознавание стимула и повторение информации. Эти аспекты
системы следует рассматривать не как составные части ее структуры, а как процессы,
которые варьируют от одного стимула к другому. Поскольку эти процессы используются
для регулирования потока информации, их называют процессами управления или регуляторными
процессами (по Atkinson a. Shiffrin, 1968).
Вернемся немножко назад. Мы проследили за перемещением информации, поступающей
из реального мира, в самые дальние закоулки нашей памяти, но мы коснулись при
этом лишь нескольких узловых пунктов чрезвычайно сложной системы. Прежде чем
продолжить изучение этой системы, рассмотрим несколько подробнее каждый из тех
структурных компонентов и процессов, которые были нами упомянуты.
СЕНСОРНЫЕ РЕГИСТРЫ
Займемся прежде всего сенсорными регистрами. Мы уже говорили о зрительном
регистре, воспринимающем стимулы, поступившие через орган зрения. Мы предполагаем,
что существуют также регистры для остальных четырех чувств: слуха, осязания,
обоняния и вкуса. Больше всего внимания психологи уделяли двум регистрам: зрительному,
который Нейссер (Neisser, 1967) назвал "иконической памятью", и слуховому, который
мы будем (опять-таки вслед за Нейссером) называть "экоической памятью".
Как правило, сенсорный регистр служит
для кратковременного удержания информации о стимуле в той индивидуальной, конкретной форме, в какой он был первоначально
предъявлен;
затем эта информация может быть преобразована в какую-то новую форму, в
которой будет передаваться дальше. Как уже говорилось, в сенсорном регистре
информация в любом случае остается очень недолго, так как след здесь
быстро угасает. Кроме того, информация может быть удалена из .сенсорного-
регистра ("стерта") вследствие поступления в него новой информации.
Нетрудно понять, почему это необходимо: если бы, например, иконический
след (в зрительном регистре) не "стирался" таким образом, то мы
постоянно видели бы несколько перекрывающихся зрительных изображений,
а не отдельные картины.
ВНИМАНИЕ И РАСПОЗНАВАНИЕ ОБРАЗОВ
За перенос информации на более глубокие уровни системы ответственны два важных
регуляторных процесса-распознавание образов и внимание, которые мы ранее представили
как некоторый этап между сенсорным регистром и кратковременной памятью (в дальнейшем
мы увидим, что такое представление не совсем верно). В чем заключается функция
избирательного внимания? Ответ на этот вопрос вытекает из сделанного нами предположения
о том, что способность системы к переработке информации ограничена. В каждый
данный момент наши органы чувств получают огромное количество информации. Когда
вы читаете эти строки, вы воспринимаете зрительные стимулы; одновременно чувство
осязания сообщает вам, что вы сидите на чем-то (или, может быть, стоите) и что
ваши пальцы прикасаются к этой книге; кроме того, вы, вероятно, слышите какие-то
звуки, если конечно, не находитесь в звуконепроницаемой камере. Некоторая часть
всей этой информации существенна, а остальная нет. .Избирательность внимания
позволяет нам настроиться на нужную информацию, сосредоточиться на ней и отбрасывать
все остальное. Таким образом, благодаря избирательности внимания в систему с
ограниченной емкостью поступает только важная информация, а не любые устаревшие
сведения (иначе происходила бы потеря важной информации).
Избирательность внимания часто иллюстрируют следующим примером,
известным под названием "феномена вечеринки". Представьте себе, что
вы находитесь на вечеринке и поглощены интересной
беседой. Внезапно вы слышите свое имя, произнесенное кем-то в другой группе
гостей. Вы быстро переключаете внимание на разговор, происходящий между
этими гостями, и можете услышать о себе кое-что очень интересное. Но
тем временем вы упустили нить того разговора, в котором участвовали раньше.
Благодаря избирательному вниманию вы можете настроиться на группу 2, но
только за счет группы 1.
Другой важный вопрос, о котором мы
упоминали,-это распознавание образов, т. е. сравнение поступающих сенсорных данных с информацией, приобретенной ранее, которая
хранится в
долговременной памяти. Цель этого процесса понять нетрудно. Она заключается
в том, чтобы превратить "сырую" информацию (например, какие-то
сочетания зрительных или звуковых стимулов), относительно бесполезную
для системы, во что-то осмысленное. Например, для данного стимула может
быть найдено определенное название, хотя это и не обязательно. Важность
распознавания образов тоже вполне понятна. Представьте себе, что могло бы
произойти, если бы вы по ошибке зарегистрировали поступившую зрительную информацию под рубрикой "лошадь", вместо того чтобы
определить ее понятием "медведь". Подобная ошибка системы
распознавания могла бы оказаться фатальной.
Распознавание образов-не простое дело. Рассмотрим довольно элементарный пример.
В повседневной жизни мы постоянно сталкиваемся с огромным разнообразием написанных
от руки, печатных, а иногда и кое-как нацарапанных букв. Как нам удается распознавать
их при всем множестве возможных начертаний и размеров? Эта задача настолько
сложна, что пока еще никому не удается построить машину, которая могла бы с
ней справиться, например читать адреса на письмах. Тот, кто сумеет сконструировать
такую машину, наживет целое состояние, так как распознаванием образов приходится
сейчас заниматься людям (банковским кассирам, сортировщикам на почте и т. п.).
Распознавать их так трудно потому, что один и тот же образ может быть представлен
множеством различных конфигураций. Например, букву А можно изобразить также
как 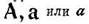 . Кроме того, при одинаковом начерталии буква может
иметь разную величину или располагаться по-разному: . Кроме того, при одинаковом начерталии буква может
иметь разную величину или располагаться по-разному:  .Еще
труднее объяснить, почему человек .распознает даже совсем новые начертания буквы,
которых он никогда прежде не видел, например .Еще
труднее объяснить, почему человек .распознает даже совсем новые начертания буквы,
которых он никогда прежде не видел, например  ! В сущности,
в большинстве случаев налисанные от 1руки буквы не только новы, но и неповторимы
каждая из них, вероятно, отличается от любой другой. Изэтого видно, что число
различных фигур, которые следует распознавать как принадлежащие к одной и той
же категории, почти бесконечно и что именно это опромное разнообразие так затрудняет
задачу машинного распознавания образов. ! В сущности,
в большинстве случаев налисанные от 1руки буквы не только новы, но и неповторимы
каждая из них, вероятно, отличается от любой другой. Изэтого видно, что число
различных фигур, которые следует распознавать как принадлежащие к одной и той
же категории, почти бесконечно и что именно это опромное разнообразие так затрудняет
задачу машинного распознавания образов.
КРАТКОВРЕМЕННАЯ ПАМЯТЬ
Распознавание данного образа, каким бы способом оно ни осуществлялось (к этому
вопросу мы вернемся позднее), означает, что получаемая в результате информация
может быть отправлена в кратковременную память (КП), которуюназывают также первичной,
непосредственной или рабочей памятью. КП изучали главным образом на словесном
материале-буквах, словах и т. п. Поэтому большая часть наших сведений об этом
хранилище информации касается именно словесного материала. Полагают, например,
что вербально закодированный элемент (т. е. элемент, представленный в виде слова,
сочетания букв и т. п.) удерживается в КП без повторения менее 30 с и что КП
может одновременно удерживать примерно 5-6 таких элементов. Повторение-само
по себе чрезвычайно интересный феномен, свойственный КП. Некоторые теоретики
полагают, что процесс повторения подобен многократному беззвучному произнесению
"про себя" названия элемента, который нужно помнить, и что каждое повторение
несет такую же функцию, как и первичное введение того же элемента в КП, т. е.
что элемент при этом возвращается в память в целости и сохранности. Хотя вопрос
о том, имеет ли здесь место внутренняя речь, остается открытым, повторение,
по-видимому, действительно используется для удержания элементов в КП. Другая
функция повторения связана с переносом информации в долговременную память. Высказывалось
мнение (см., например, Atkinson a. Shiffrin, 1968), что чем большее число раз
повторяется информация и чем дольше она удерживается в КП, тем больше вероятность
того, что ее удастся припомнить в дальнейшем. Это, в сущности, означает, что
процесс повторения может способствовать закреплению информации в ДП, так что
впоследствии ее легче бывает вспомнить.
Часто отмечают еще одну особенность кратковременной
памяти-то, что образы слов удерживаются здесь в слуховой форме, а не в
зрительной. Так бывает даже в том случае, если данное слово было введено в
систему через зрительный образ. Об этом заключают из того, что, когда в
ре зультате неадекватного воспроизведения информации,
хранящейся в КП, дается неверный ответ (такой ответ называют
"ошибкой смешения", так как при этом информацию, не находящуюся
в КП, путают с внесенной туда информацией), испытуемый обычно смешивает
элементы, сходные по звучанию, а не по видимой форме (Conrad, 1964).
Например, если он должен вспомнить букву V, которая была ему предъявлена
визуально и поступила в КП, то в случае ошибки он назовет вместо нее
скорее букву В, чем X, так как В и V сходны по звучанию, хотя по виду буква
Х больше похожа на V.
ДОЛГОВРЕМЕННАЯ ПАМЯТЬ
Долговременную память — чрезвычайно сложную систему хранения информации -также
очень широко изучали на вербальном материале, обычно представленном в форме
длинных списков. Как мы увидим, этот подход позволил получить ряд исключительно
важных результатов, но вместе с тем его нельзя считать безупречным. Ведь воспроизведение
списков слов все же чем-то отличается от припоминания какого-нибудь разговора,
кулинарного рецепта или сюжета кинофильма. Недавно стали изучать функцию ДП
в процессе усвоения связного вербального материала, когда запоминаются не просто
отдельные слова, а осмысленные лингвистические структуры. Изучение памяти с
использованием такого материала дает гораздо больше сведений о деятельности
ДП в повседневной жизни.
Относительно ДП было выдвинуто несколько важных гипотез,
заслуживающих упоминания. Одна из них состоит в том. что в отличие от
кратковременной памяти и сенсорных регистров в ДП информация сохраняется
неопределенно долгое время. Но если эта гипотеза верна, то почему же мы
не способны припоминать все, что мы когда-либо знали? Сторонники этой
гипотезы считают, что забывание обусловлено невозможностью извлечь нужную
информацию — она есть, но мы не можем до нее добраться.
Другая
интересная гипотеза, касающаяся ДП,-это гипотеза о том, что информация
может, быть закодирована разными способами — в слуховой, зрительной или
семантической (смысловой) форме. Например, в моей долговременной памяти должна содержаться информация о шуме приближающегося поезда,
потому что я распознаю этот шум, когда слышу его. В ДП хранится также образ
моей сестры, поскольку я ее узнаю при встрече. В ДП должно также храниться название города, в котором я живу, так как я могу назвать его,
если меня спросят.
Чтобы понять, насколько сложна должна быть система ДП, нужно осознать, что
в ней записано все, что нам известно об окружающем мире. Джордж Вашингтон
никогда не лгал; собаки должны есть, чтобы жить; башмаки носят на ногах и так
далее. Это огромное количество информации не только хранится в ДП, но до каждого
ее элемента можно добраться и притом многими путями. Рассмотрим в качестве примера
слово "улыбка". Путь к нему может лежать через его определение: "Назовите слово,
обозначающее очертания рта у человека, когда он счастлив". Мы можем также воспроизвести
его, заполнив пробел в строке "Ведь ...... — это флаг корабля!". Есть еще много
путей, которые приведут нас к этому слову.
Вообще информация в ДП размешена, по-видимому, таким образом, что
извлечь ее относительно легко. Если мы получаем некоторую информацию
(например, слышим слово "улыбка"), то мы без особых затруднений
находим то место в ДП, где хранится связанная с ней другая информация (особенность памяти, называемая "адресацией по содержанию" и
означающая, что мы можем найти местоположение, илп адрес, данной информации,
если у нас имеется ключевая часть ее содержания). Более того, мы находим
такую информацию в ДП очень быстро, и сама эта быстрота свидетельствует, во-первых, о том, что извлечение-не какой-то случайный,
ненаправленный процесс, и, во-вторых, о том, что ДП представляет собой
высокоупорядоченную систему.
На этом мы заканчиваем общий обзор системы переработки информации у человека,
однако мы не можем принять описанную модель без всяких оговорок. В последующих
главах мы увидим, что эта предварительная модель нуждается во многих уточнениях.
На данном этапе, однако, особенно важно уточнить один ее аспект-вопрос о разграничении
между КП и ДП.
ТЕОРИЯ ДВОЙСТВЕННОСТИ ПАМЯТИ.
ОДНА ПАМЯТЬ ИЛИ ДВЕ?
Согласно нашей модели, в системе памяти информация может храниться в сенсорных
регистрах, в КП и в ДП. Для разграничения этих трех типов хранения информации
имеются как логические, так и эмпирические основания. Например, нетрудно найти
доводы в пользу гипотезы о существовании сенсорных регистров, поскольку ясно,
что в системе памяти должны быть какие-то места, где поступившая от органов
чувств информация могла бы удерживаться до тех лор, пока не будет распознан
ее первичный смысл. О существовании таких регистров свидетельствуют также экспериментальные
данные. (Большая часть этих данных получена сравнительно недавно; они будут
рассмотрены в гл. 3.)
Однако теория, согласно которой подсистема, лежащая выше сенсорного регистра,
делится на два хранилища — К.П и ДП ("теория двойственности"), принимается некоторыми
теоретиками с меньшей готовностью. Поэтому мы рассмотрим сначала ряд важных
данных, говорящих в пользу этой теории, а затем обсудим ее недостатки и некоторые
альтернативные теоретические подходы.
Одна группа данных, приводимых в подтверждение теории двойственности, носит
физиологический характер. В 1959 г. Бренда Милнер описала ряд патологических
явлений, наблюдаемых после повреждения гиппокампа. Совокупность этих явлений
стали называть "синдромом Милнер". Больной с синдромом Милнер, по-видимому,
не способен вспоминать недавние события, хотя он помнит события, происходившие
в далеком прошлом — до того, как был поврежден его мозг. У него сохраняются
те знания и навыки, которые он приобрел до повреждения гиппокампа. Он способен
также вспоминать информацию непосредственно после того, как она ему была предъявлена:
он может повторить то, что ему сказали, и способен даже удерживать материал
в памяти несколько минут, если ему дают возможность повторять его вновь и вновь
без перерыва. Но больной, видимо, в состоянии сохранять в памяти новую информацию
только до тех пор, пока он может повторять ее. Все это заставляет предполагать,
что человек с поврежденным гиппокампом обладает как долговременной памятью (где
хранятся события далекого прошлого), так и кратковременной памятью (используемой
для немедленного воспроизведения или внутреннего повторения). Создается впечатление,
что у него нарушена связь между КП и ДП и поэтому утрачена способность "переводить
новую информацию в ДП. Таким образом, синдром Милнер вполне соответствует теории
двойственности; эта теория помогает понять, каким образом могли бы возникать
подобные расстройства памяти.
Другие данные в пользу теории двойственности получены в результате экспериментальных
исследований. Интересные сведения дает изучение ошибок, совершаемых при вспоминании.
Одна из ситуаций, в которых возникают такие ошибки, создается в задачах, связанных
с "объемом памяти" или "непосредственной памятью" (напомним, что непосредственная
память — это всего лишь другое название для КП). В таких задачах испытуемому
предъявляют краткий ряд элементов, например букв, и просят его тут же повторить
их. Теоретически при выполнении этой задачи используется информация, находящаяся
в КП, поскольку буквы были предъявлены совсем недавно. Когда испытуемый называет
букву, которой не было в ряду, вместо той, которая в нем была, говорят об "ошибках
смешения". Как уже упоминалось, при таких ошибках чаще путают буквы вроде В
и V, сходные по звучанию, чем буквы, звучащие по-разному, причем это наблюдается
и в случае зрительного предъявления букв.
Рассмотрим теперь аналогичный эксперимент с долговременной памятью. Испытуемому
предъявляют ряд слов и по прошествии часа просят его припомнить их. Ошибки,
которые он при этом сделает, будут, как правило, не акустическими, а семантическими.
Так, например, если в предъявленном списке было слово ТРУД, то испытуемый назовет
вместо него скорее слово РАБОТА, чем ТРУП. Таким образом, он называет слово,
сходное по значению, но не путает слова на основе их звучания. Короче говоря,
ошибки, совершаемые привспоминании из ДП, носят обычно семантический характер
(Baddeley a. Dale, 1966), а ошибки при вспоминании из КП — в большинстве случаев
слуховые. Это указывает на то, что информация, хранящаяся в КП, возможно, закодирована
в "слуховой форме, а информация, хранящаяся в ДП,в "смысловой", семантической
форме.
В пользу теории двойственности говорят также результаты экспериментов со свободным
припоминанием. Мы уже отмечали, что по этим результатам можно построить кривую
зависимости частоты вспоминания от места в ряду и что в этой кривой можно выделить
начальный участок, среднее плато и концевой участок (рис. 2.2, А). Теория двойственности
памяти объясняет эту кривую следующим образом. Эффект начала-это результат припоминания
из ДП. Он возникает потому, что первые слова ряда приходятся на "пустую" КП:
испытуемому больше не на чем сосредоточиться и поэтому он может многократно
повторять несколько первых слов. Но в конце концов-скажем, после первых шести
слов-ему приходится усваивать больше слов, чем он может одновременно удержать
в КП (ввиду ее ограниченного объема). Каждое последующее слово может быть повторено
лишь несколько раз, прежде чем оно исчезнет из КП. Таким образом, первые слова
ряда повторяются большее число раз и поэтому более эффективно переводятся в
ДП. В отличие от этого слова из середины ряда поступают в КП, когда она уже
наполнена; все они могут быть повторены примерно одинаковое (небольшое) число
раз, и поэтому частота вспоминания всех этих слов находится на одном и том же
относительно низком уровне.
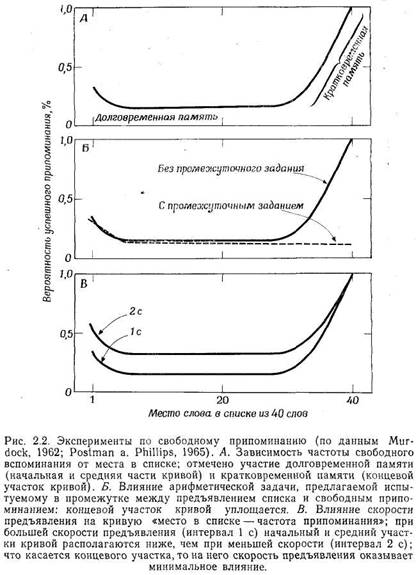
Эффект конца объясняется следующим образом: элементы, стоящие в конце ряда,
еще находятся в КП, когда начинается вспоминание; поэтому испытуемый воспроизводит
их непосредственно из КП и частота вспоминания для них очень высока. В пользу
такого объяснения говорит и то, что испытуемые обычно называют слова, стоящие
в конце ряда, сразу же, как только начинают воспроизведение.
Эти объяснения, основанные на теории двойственности, получают подкрепление
в экспериментах, которые показывают, что на начальный и концевой участки кривой
можно оказывать влияние по отдельности. Очевидно, при этом затрагиваются ДП
и КП соответственно (рис. 2.2). Допустим, например, что мы предъявляем испытуемому
ряд слов и предлагаем ему начать воспроизведение лишь спустя 30 с. В промежутке
мы задаем ему несколько арифметических примеров, считая, что тем самым он лишается
возможности повторять слова, поступившие в КП. Следует ожидать, что такая процедура
как-то затронет концевой участок кривой, поскольку испытуемый не сможет теперь
воспроизвести последние слова прямо из КП. Так оно и происходит на самом деле:
в таких экспериментах эффект конца отсутствует (см., например, Postman a. Phillips,
1965; рис. 2.2, Б).
Можно попытаться также воздействовать на ДП, изменяя скорость предъявления
слов. При высокой скорости — одно слово в секунду — у испытуемого очень мало
времени на повторение, и в ДП может попадать гораздо меньше слов, чем в том
случае, если предъявление производят вдвое медленнее-одно слово каждые две секунды.
(Однако на хранение в КП это не повлияет: испытуемый сможет удержать несколько
последних слов в КП как при той, так и при другой скорости предъявления.) Эта
гипотеза также подтвердилась. Начальный и средний участки кривой свободного
вспоминания при низкой скорости предъявления располагаются выше, так как при
такой скорости возможно большее число повторений, обеспечивающее более эффективное
хранение в ДП. В то же время на концевой участок кривой скорость предъявления
практически не влияет (Murdock, 1962; рис. 2.2, В).
В последние десять лет теория двойственности получила широкое признание, однако
она не столь безупречна, как это может показаться. Прежде всего большую часть
данных, приводимых в пользу этой теории, можно объяснить, не постулируя существования
КП, обособленной от ДП. Уиклгрен (Wickelgren, 1973) изучил девять основных групп
данных в пользу теории двойственности памяти и отбросил шесть из них по этой
причине. Рассмотрим, например, описанный выше эксперимент с введением промежуточного
задания (т. е. задания, которое предлагают в промежутке между предъявлением
ряда элементов и свободным припоминанием). Мы знаем, что при выполнении такого
задания концевой участок кривой уплощается, начальная же часть ее остается почти
неизмененной; это различие во влиянии промежуточного задания и приводят в качестве
довода в пользу теории двойственности. Однако этот довод потеряет свою убедительность,
если мы осознаем то, что элементы в начале ряда в любом опыте подвергаются влиянию
промежуточного материала. Ведь за ними следуют все дальнейшие члены ряда, и
только после этого начинается их воспроизведение. Таким образом, последние элементы
ряда, вклинивающиеся между предъявлением первых элементов и их припоминанием,
тоже играют, в сущности, роль промежуточного материала. Кроме того, как мы увидим
в гл. 9, хотя промежуточное задание и может сильно повлиять на вспоминание информации,
которая непосредственно ему предшествовала, но по мере дальнейшего добавления
промежуточного материала эффект каждого нового, элемента будет все более и более
слабым. Не удивительно поэтому, что влияние задания, предлагаемого по окончании
предъявления списка, на воспроизведение элементов из первой части списка невелико:
к тому времени, когда выполняется такое задание, эта первая часть уже испытала
воздействие элементов, составляющих вторую часть списка. Иными словами, влияние
задания, предлагаемого по окончании списка, на вспоминание его концевых элементов
можно сравнить с влиянием средней и концевой частей на припоминание начальной
части. Но если это так, то нельзя утверждать, что выполнение промежуточных заданий
сказывается на разных участках кривой по-разному, а значит, и доводы в пользу
теории двойственности, основанные на эффекте заданий, предлагаемых после списка,
нельзя считать решающими.
Есть и другие экспериментальные
данные, вызывающие сомнения в справедливости теории двойственности. В доследующих главах — при более подробном рассмотрении кратковременной и
долговременной памяти-нам придется столкнуться с целым рядом таких данных,
однако о некоторых из них мы упомянем сейчас.
Одна группа доводов в пользу теории двойственности связана с различной формой
представления информации (различным кодом памяти) в КП и в. ДП. Как
мы уже говорили, в КП информация кодируется в слуховой форме, а в ДП — в семантической
форме. Однако мы очень скоро познакомимся с экспериментальными данными, свидетельствующими
также о зрительном и семантическом (а не только слуховом) кодировании в КП.
О том, что ДП должна содержать слуховую и зрительную информацию (равно как информацию
о запахах, вкусе и осязательных ощущениях), уже говорилось; иначе как мы могли
бы узнавать лица или звуки, которых мы долго не видели или. не слышали? Итак,
разграничение двух видов памяти по типу кода (слуховой или семантический код)
не столь бесспорно, как может показаться по результатам некоторых экспериментов.
Мы отмечали также, что без повторения запоминаемые элементы удерживаются в
КП всего лишь несколько секунд, тогда как в ДП они могут храниться неопределенно
долго. Это могло бы служить критерием для разграничения этих; двух хранилищ
информации, однако дело осложняется тем, что оценки длительности удержания информации
в КП сильно варьируют. То же самое можно сказать об объеме КП; т. е. о числе
элементов, которые могут храниться в ней одновременно; здесь тоже оценки весьма
различны. Одна из причин этих расхождений состоит в том, что КП и ДП — если,
это и в самом деле две разные системы — в очень большой степени взаимозависимы.
Связь между ними заключается не только в том, что повторение информации, содержащейся
в КП, ведет к образованию следов в ДП: в свою очередь и ДП принимает большое
участие в кодировании информации в КП. Допустим, например, что в КП поступает
какая-то буква, предъявленная человеку зрительно. Откуда он мог бы узнать, что
это действительно буква, не обратившись к ДП в поисках ее зрительного образа
и названия? Поскольку ДП: участвует в распознавании образов, она тем самым участвует
и в кодировании информации в КП. Кроме того, ДП может оказывать влияние на представление
элементов в КП после того, как они были распознаны. Например, бессмысленный
слог ВПС может храниться в КП как сокращение слова "Висконсин". Процесс опосредования,
происходящий при записи в памяти слога ВИС в форме слова "Висконсин", связан
с тем, что для перевода этого слога в более осмысленную единицу используется
информация из ДП.
Пытаясь втиснуть эти сложные операции и коды памяти в рамки теории двойственности,
некоторые психологи иногда проделывали с КП и ДП всевозможные манипуляции, искажая
эти понятия до полной неузнаваемости. В результате v других психологов возник
вопрос: "А стоит ли вообще возиться с теорией двойственности?"
Одной из альтернатив теории двойственности памяти служит так называемая теория
"уровней переработки" (Graik а. Lockhart, 1972; Posner, 1969). Это одна из разновидностей
теории переработки информации, поскольку в ней процесс переработки делится на
ряд этапов (называемых уровнями), но здесь отсутствуют структурные компоненты,
подобные КП или ДП. То, что в теории двойственности было структурными компонентами
системы памяти, в теории уровней рассматривается как процессы, сходные, скажем,
с распознаванием образов или вниманием.
Предположим, например, что мы
интерпретируем хранилище КП как процесс. Тогда вместо того, чтобы
представлять себе элемент, удерживаемый в памяти короткое время, как
находящийся в особом хранилище, мы будем считать, что он подвергается
некоторому процессу-в данном случае процессу репрезентации в слуховой форме
вскоре после предъявления. Одно из преимуществ такого подхода состоит в
следующем: если окажется, что какой-то элемент может быть представлен
зрительно в той подсистеме, которую мы считаем кратковременной памятью, нам
не придется видеть в этом факте нарушение какого-то важного принципа (состоящего в том, что в КП информация кодируется в слуховой форме). Мы
можем просто рассматривать это как еще один возможный процесс-процесс
зрительного кодирования элемента вскоре после его предъявления.
Рассуждая обо всех этих вещах, полезно помнить, что независимо от того, какую
теорию вы примете (и независимо от всех дискуссий о КП и ДП), это будет всего
лишь теория. Приведенные здесь данные в пользу теории двойственности
— изменения концевого участка кривой свободного припоминания, различия в ошибках,
допускаемых после коротких и длинных интервалов, а также результаты физиологических
наблюдений — все это указывает на то, что деление памяти на кратковременную
и долговременную по меньшей мере полезно. Это деление может заставить нас постулировать
два хранилища информации, КП и ДП, но оно допускает также предположения о двух
уровнях переработки информации, о двух кодах памяти или каких-либо других двойственных
процессах или механизмах. Какое из этих подразделений мы примем — не имеет решающего
значения. Важно помнить, что теория может служить полезным средством для описания
наблюдаемых явлений и их объяснения, не будучи при этом точным и доскональным
отчетом о них.
Глава 3
Сенсорные регистры
Модель памяти, описанная в гл. 2, включает сенсорные регистры, в которых
поступающая извне информация может удерживаться в течение короткого времени
в своей исходной форме (т. е. как точное воспроизведение первоначального стимула),
прежде чем она будет распознана и передана дальше. Предполагается, что подобный
регистр существует для каждого чувства. Сенсорные регистры психологи называли
по-разному: хранилищами сенсорной информации, иконической памятью или прекатегориальной
памятью (последнее название — "прекатегориальная" — указывает на то, что входной
сенсорный сигнал еще не распознан, не отнесен к какой-либо категории).
ЗРИТЕЛЬНЫЙ РЕГИСТР
Наиболее изучены сенсорные регистры, соответствующие зрению и слуху. Они были
названы иконическим и экоическим регистрами (Neisser, 1967). Большая часть имеющихся
данных об иконической памяти, т. е. о хранении информации в виде иконичеоких
следов, получена Джорджем Сперлингом (Sperling, 1960; Averbach a. Sperling,
1961). Исследования Сперлинга начались с экспериментов на непосредственное вспоминание.
В таких экспериментах испытуемым предъявляют на очень короткое время ряд букв,
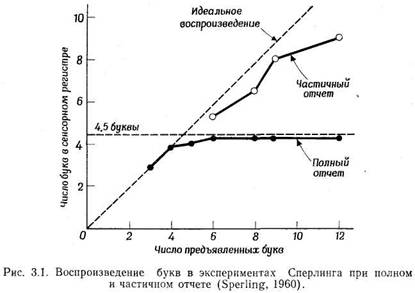
а затем просят вспомнить их. Полученные Сперлингом результаты с полной определенностью
указывали на то, что эффективность воспроизведения зависит от числа предъявляемых
букв. Если испытуемому предъявляют не больше четырех букв, он их воспроизводит
вполне точно. Если же число букв увеличивают до пяти или более, воспроизведение
ухудшается — испытуемые уже не могут припомнить все предъявленные буквы, а воспроизводят
в среднем 4-5 букв. Этот верхний предел (т. е. то число элементов, при котором
точность выполнения задачи на непосредственное припоминание становится ниже
100%) называют объемом памяти. На основании только что описанных опытов мы можем
сказать, например, что объем непосредственной памяти для букв равен примерно
пяти. (Оговорка "для букв" существенна, так ка.к объем памяти несколько варьирует
в зависимости от характера материала, подлежащего запоминанию.)
В подобных экспериментах расположение предъявляемых букв не имеет большого
значения. Например, шесть букв можно расположить в один ряд или же в два ряда
по три буквы в каждом, и это не повлияет на эффективность воспроизведения. Рассмотрим
один конкретный эксперимент, проведенный Сперлингом. Допустим, испытуемому предъявляют
девять букв, расположенных в виде таблицы 3X3 (т. е. в три ряда по три буквы
в каждом). Предъявление продолжается очень недолго — всего 50 мс. Одна миллисекунда
равна 0,001 с, так что 50 мс составляют 0,05 с; за это время испытуемый не успевает
перевести взгляд. После предъявления такой таблички он воспроизводит все, что
может вспомнить; результаты теперь уже можно предсказать заранее: в среднем
испытуемый сможет воспроизвести только четыре или пять букв.
Можно было бы предположить, что испытуемый нс способен воспроизвести все девять
букв потому, что он не увидел их все; ведь 0,05 с — это очень короткое время.
Однако причина неудачи — не в кратковременности предъявления букв; результаты
не изменятся, если увеличить продолжительность предъявления до 0,5 с (время,
совершенно достаточное для того, чтобы разглядеть все буквы). Но это и недолжно
удивлять нас: в описанном опыте определяется объем памяти, так же как это было
и в экспериментах Эббингауза, и результаты сходны с теми, которые мы уже отмечали
для подобных задач: при самых разнообразных условиях предъявления испытуемые
непосредственно после этого весьма успешно воспроизводят короткие списки элементов,
но с увеличением длины списка способность к припоминаниюухудшается.
Только что описанный метод, при котором испытуемому предъявляют таблицу букв,
а затем просят припомнить их все или как можно больше, именно поэтому называется
методом полного отчета. Сперлинг изучал способность к запоминанию не
только этим методом; он разработал еще новый метод, который назвал методом частичного
отчета. Испытуемому на короткое время предъявляют набор букв, расположенных
в три ряда. Сразу же после окончание предъявления испытуемый слышит высокий,
средний или низкий тон, который служит сигналом, указывающим какой ряд букв
следует воспроизвести. В ответ на высокий тон нужно воспроизвести верхний ряд,
в ответ на средний — средний, а в ответ на низкий — нижний ряд. После подачи
звукового сигнала испытуемый тотчас же пытается воспроизвести соответствующий ряд букв. Эту последовательность событий
(предъявление букв-звук-воспроизведение) называют пробой, а
эксперимент состоит из ряда таких проб.
В другом варианте задачи с частичным отчетом испытуемого просят воспроизвести
одну определенную букву из предъявленной таблицы. В этом случае (Averbach a.
Coriell, 1961) соответствующая инструкция дается не звуковым, а зрительным сигналом:
вслед за буквами появляется белое поле с черной полоской, расположенной над
тем местом, где находилась одна из букв, и именно эту букву испытуемый должен
воспроизвести. Вообще главная особенность экспериментов с частичным отчетом
состоит в том, что за предъявлением букв следует какой-либо сигнал, сообщающий
испытуемому, какую часть всего набора букв следует вспомнить.
Мы уже знаем результаты экспериментов с полным отчетом: независимо от общего
числа предъявленных букв испытуемый может воспроизвести не более пяти из них.
Как можно видеть из данных Сперлинга (рис. 3.1), эксперименты с частичным отчетом
дают совершенно иные результаты. Рассмотрим случай с предъявлением девяти букв.
В опытах с частичным отчетом ответы испытуемых оказываются почти на 100% верными
независимо от того, какой ряд нужно было воспроизвести. Но это означает, что
в тот момент, когда раздается звуковой сигнал, у испытуемого в памяти еще находятся
все девять букв, иначе он, несомненно, сделал бы ошибку при воспроизведении
какого-либо ряда в одной из проб.
Степень
точности воспроизведения можно использовать для оценки числа букв,
хранящихся в памяти испытуемого в момент подачи звукового сигнала. Для этого
достаточно умножить степень точности (т. е. процент правильных воспроизведений) на число предъявленных букв. Например, точность
воспроизведения таблиц из 12 букв (три ряда по четыре буквы в каждом)
составляла около 76%; это указывает на то, что в момент отчета 9 из этих 12
букв содержались в памяти, что почти идеально совпадает с результатами, полученными в опытах с девятью буквами.
Результаты экспериментов Стерлинга, представленные на рис. 3.1, показывают,
что непосредственно после предъявления стимула память содержит гораздо больше
материала, чем испытуемый может воспроизвести в полном отчете. Возникает вопрос:
в чем причина такого несоответствия между частичным и полным отчетом? Почему
получается так, что объем памяти испытуемого будто бы составляет всего 5 букв,
когда на самом деле в памяти может сохраняться 9 букв?
Прежде чем ответить на этот вопрос, рассмотрим одну модификацию эксперимента
с частичным отчетом. В описанном выше варианте опыта звуковой сигнал подавался
сразу же после предъявления букв. Можно, однако, задержать сигнал. Результаты
экспериментов, в которых сигнал подавался с задержкой различной длительности,
представлены на рис. 3.2 (для таблицы из 12 букв). При подаче сигнала без задержки
в памяти, судя по эффективности воспроизведения, находилось примерно 9 букв.
Но по мере увеличения задержки испытуемые делали все больше и больше ошибок,
а при задержке в 1 с эффективность воспроизведения примерно соответствовала
тому, что было бы при полном отчете, т. е. составляла 5 букв.
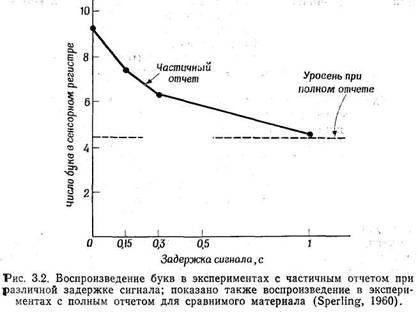
Вернемся к поставленному нами вопросу. Эксперименты Сперлинга показывают, что
в памяти непосредственно после зрительного предъявления содержится больше информации,
чем спустя 1 с после этого. Результаты экспериментов с частичным отчетом без
задержки инструктивного сигнала позволяют измерить информацию, содержащуюся
в памяти в первый момент после предъявления стимула. В отличие от этого эксперименты
с полным отчетом позволяют установить, что остается по прошествии некоторого
времени; оказывается, память содержит теперь гораздо меньше информации, чем
было вначале. А результаты экспериментов с частичным отчетом и задержкой сигнала
показывают, что происходит в промежутке между этими двумя моментами: по-видимому,
первоначальный иконический след постепенно угасает, так что с течением времени
от содержавшейся в стимуле информации остается все меньшая и меньшая доля. Короче
говоря, полученные Сперлингом результаты говорят о существовании некоторой формы
непосредственной зрительной памяти, следы в которой отличаются высокой точностью,
но очень быстро угасают.
Непосредственная память, функцию которой Сперлинг продемонстрировал в экспериментах,
соответствует тому, что мыв: своей модели называем сенсорным регистром. Эксперименты
Сперлинга касаются регистра для зрения, для иконических образов. В нашей модели
(гл. 2) роль этого регистра состоит в том, что он в течение короткого времени
сохраняет зрительную информацию в ее первоначальной форме и это позволяет посылать
в систему дальнейшую информацию о данном стимуле. Поскольку иконическая память
— довольно примитивный род памяти, в которой стимулы представлены практически
в своей исходной форме, большое влияние на нее оказывают условия предъявления.
В этом отношении иконическая память непохожа на более глубокие уровни памяти.
К важным переменным, влияющим на иконическую память, относятся: освещение, предшествующее
зрительному стимулу (в экспериментах Сперлинга 0 -предъявлению букв) и следующее
за ним, зрительная стимуляция, следующая за данным стимулом, и длительность
предъявления.
Влияние освещения можно изучить, сравнивая результаты двух опытов, в одном
из которых до и после предъявления букв испытуемый видел темное поле, а в другом
— светлое поле. Создается впечатление, что в случае темного поляиконический
образ сохраняется дольше. На это указывает то, что период угасания образа (экспериментально
определяемый как наибольшая задержка сигнала в опытах с частичным отчетом, при
которой испытуемые еще воспроизводят буквы лучше, чем при полном отчете) при
темном поле более длителен. Очевидно, при светлом поле системе труднее "разглядеть"
содержащуюся в иконическом образе информацию; зрительная стимуляция, создаваемая
светлым полем, видимо, как-то нарушает восприятие образа. Ведь в сущности светлое
поле-это тоже некое явление, воспринимаемое зрительной системой.
Это предположение становится еще более правдоподобным в свете экспериментов,
в которых за предъявлением букв следовали не звуковой сигнал и не черная полоска,
а чтонибудь иное (Averbach a. Coriell, 1961). Допустим, что вслед за таблицей
букв появляется кружок, внутри которого находилась бы одна из букв, если бы
она оставалась на месте (рис. 3.3). Испытуемый должен воспроизвести эту "окруженную"
букву. Результаты такого эксперимента оказались несколько неожиданными. Как
можно видеть на рис. 3.4, в тех: случаях, когда сигнальная метка предъявляется
либо со значительной задержкой (0,5 с или около того), либо без всякой задержки,
воспроизведение примерно одинаково успешно как с полоской, так и с кружком.
Однако в случаях, промежуточных между отсутствием задержки и длительной задержкой,
эффективность воспроизведения в опытах с кружком была гораздо ниже, чем в опытах
с полоской.
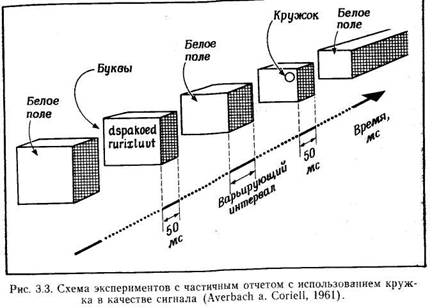
Приведенные на рис. 3.4 данные были истолкованы следующим образом. Когда кружок
тотчас же следует за буквами, ой эффективно накладывается на одну из них; испытуемый
при этом "видит", что одна буква помещена в кружок, и называет эту букву. (Это
сходно с те, что происходит при использовании полоски: при небольшой задержке
испытуемый видит букву с расположенной над нею полоской.) При очень длительных
задержках как кружок, так и полоска появляются тогда, когда образ буквы уже
стерся. Однако при промежуточных задержках все обстоит иначе. Кружок стирает
образ буквы, которую он должен был бы выделить, и замещает его; вместо того
чтобы видеть букву и кружок, испытуемый видит только кружок. Это явление называют
обратной маскировкой, поскольку кружок действует в обратном направлении во времени,
маскируя или стирая букву которая ему предшествовала. (Полоска же, которая сильнее
смещена относительно, буквы, не вызывает стирания.)
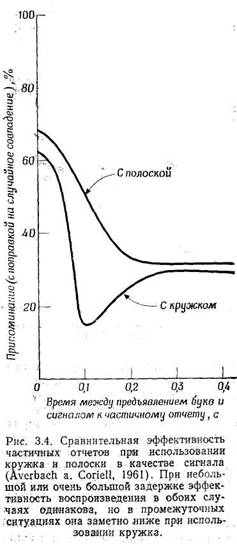
С явлением стирания связано и отмеченное выше различие в эффекте светлого
и темного полей. Мы высказали предположение, что светлое поле интерферируете
иконическим образом, так как оно само представляет собой зрительный стимул.
А теперь оказывается, что стимул, непосредственно следующий за набором букв
и располагающийся на месте одной из них, может действовать примерно таким же
образом. Сопоставляя эффект стирания образа с нашей концепцией сенсорного регистра,
мы убеждаемся, что стирание выполняет важную функцию: оно не позволяет иконическим
образам слишком долго сохраняться в сенсорном регистре Если бы не было стирания,
то каждый новый иконический образ сложился бы поверх предыдущего, что приводило
бы к нагромождению и перемешиванию зрительной информации. Функция стирания заключается
именно в том, чтобы недопускать этого. По мере поступления новой информации
этот процесс расчищает для нее место, удаляя остатки предшествующих иконических
образов.
СЛУХОВОЙ РЕГИСТР
Если бы не было иконических образов, мы могли бы "видеть" зрительные стимулы
лишь до тех пор, пока они остаются унас перед глазами. Нам часто не удавалось
бы распознавать быстро исчезающие стимулы, так как распознавание требует известного
времени, иногда более длительного, чем то, в течение которого мы можем видеть
стимул. Посмотрим теперь, что случилось бы, если бы не было экоической памяти-сенсорного
регистра для слуха. Путем аналогичных рассуждений мы приходим к выводу, что
мы могли бы тогда "слышать" звуки лишь до тех пор, пока они звучат. Но такое
ограничение привело бык весьма серьезным последствиям: у нас возникли бы большие
трудности с пониманием устной речи. Для иллюстрации этого Нейссер (Neisser,
1967, стр. 201) приводит следующий пример: иностранцу говорят "Np, not
zeal, seal!" ("Нет, не усердие, а тюлень!"). Нейссер отмечает,
что иностранец ничего не мог бы понять, если бы он не смог удержать в памяти
"z" из слова zeal достаточно долгое время, чтобы сравнить его с "s"в
слове seal. Нетрудно найти и другие примеры пользы экоической памяти. Мьь не
смогли бы уловить вопросительной интонации в фразе"Вы пришли?", если бы первая
ее часть не была доступна для сравнения в момент звучания второй. Вообще, поскольку
звуки имеют известную длительность, должно существовать какое-то место, где
бы ихкомпоненты могли удерживаться в течение какого-то времени. Таким местом
служит сенсорный регистр для слуха.
Существование экоического образа было продемонстрировано в эксперименте, аналогичном
демонстрации иконического образа в опытах Сперлинга. Испытуемые в этом эксперименте
(Moray а. о., 1965) выступали в роли "четырехухих" людей, т. е. они прослушивали
одновременно целых четыре сообщения, поступавших по отдельным каналам. Отклонившись
несколько в сторвну, поясним, что канал означает источник информации,
в данном случае-звука. Это понятие, может быть, знакомо вам, если у вас есть
стереофонический проигрыватель. В нем обычно имеется два динамика, которые несколько
по-разному воспроизводят исполняемую музыку. Аналогичным образом можно сконструировать
четырехканальную систему для проведения упомянутого выше эксперимента. Один
способ состоит в том, чтобы установить четыре громкоговорителя и поместить испытуемого
посередине между ними. Другой способ — использовать наушники, разделив каждый
наушник так, чтобы к нему было подключено два источника звука. Морэй и его сотрудники
нашли, что обе системы-четыре репродуктора или "разделенные" наушники — примерно
одинаково эффективны. Для наших целей главное то, что испытуемые могут различать
отдельныеканалы: когда их просят слушать один определенный канал, они в состоянии
это сделать. Они слышат не просто сумбурзвуков, а нечто такое, в чем можно различить
сообщения, поступающие из разных источников.
Вернемся к "четырехухим людям". В экспериментах Морэя и его сотрудников каждый
испытуемый участвовал в серии проб. В каждой пробе он прослушивал сообщения,
поступавшие одновременно по двум, трем или четырем каналам (через репродукторы).
Каждое сообщение состояло из 1 — 4 букв алфавита. Задача испытуемого заключалась
в том, чтобы вспомнить эти буквы после того, как он их услышал.
В одном варианте опыта он старался припомнить все буквы; это был вариант с
полным отчетом. В другом варианте требовался частичный отчет — вроде того, как
это было в экспериментах Сперлинга. Сигналом к началу воспроизведения служил
не звук, а свет. Испытуемый во время прослушивания держал в руках доску, на
которой находились две, три или четыре лампочки, расположенные в соответствии
с размещением репродукторов. Спустя 1 с после окончания передачи сообщений одна
из лампочек вспыхивала; это служило сигналом, после которого испытуемый начинал
воспроизводить буквы, переданные по соответствующему каналу, т. е. давал частичный
отчет. Морэй и его сотрудники нашли, что пря частичном отчете процент припоминания
был выше, чем при полном, независимо от числа используемых каналов и числа букв,
передаваемых по одному каналу. Из этого, как и из экспериментов Сперлинга, можно
сделать вывод, что непосредственно после предъявления букв (спустя 1 с) память
содержала о них больше информации, чем в последующий период. По-видимому, эта
информация была представлена в форме, являющейся слуховым аналогом иконического
образа, т. е. в форме экоического образа.
Зная о существовании экоической памяти или по крайней мере предполагая его,
мы можем задать вопрос: как долго сохраняется в ней след звукового стимула?
Ответ на этот вопрос неясен: оценки продолжительности удержания информации в
экоической форме сильно варьируют. Одна из этих оценок основана на результатах
исследований Дарвина, Терви и Кроудера (Darwin а. о., 1972), которые, подобно
Морэю и его сотрудникам, пользовались методом частичного отчета. Дарвин и его
коллеги давали испытуемым прослушивать списки, состоявшие из трех элементов
(букв или цифр); три таких списка передавались одновременно по трем каналам.
Испытуемый воспроизводил либо все элементы, которые он смог запомнить (вариант
с полным отчетом), либо, подчиняясь зрительному сигналу, называл элементы, поступавшие
по одному определенному каналу (вариант с частичным отчетом). Этот сигнал подавался
спустя 0, 1, 2 или 4 с после окончания передачи сообщения. Результаты этого
эксперимента представлены на рис. 3.5; из приведенного графика видно, что при
небольших задержках (до 2 с) точность воспроизведения в варианте с частичным
отчетом намного выше, чем при полном отчете, но при задержке сигнала до 4 с
эффективность при частичном отчете снижалась. Это указывает на то, что в экоической
памяти, которая, как мы предполагаем, обусловливает высокую эффективность частичного
отчета (точно так же, как и в аналогичном опыте со зрительными стимулами), информация
сохраняется примерно в течение 2 с.
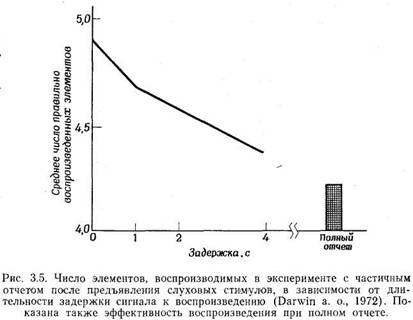
В других экспериментах, проведенных с целью определить длительность удержания
экоического образа, испытуемым предъявляли звуки, которые нельзя было идентифицировать
без предъявляемого вслед за ними "ключа". При этом исходили из предположения,
что ключ может помочь испытуемому идентифицировать звук только в том случае,
если в момент предъявления ключа в экоической памяти еще сохраняется след этого
звука. Постепенно увеличивая интервал между звуком и ключом и определяя максимальную
задержку, при которой ключ все еще облегчает идентификацию звука, можно оценить
длительность сохранения информации в экоической памяти. Если ключ помогает идентифицировать
звуки, то информация, значит, еще хранится, а если он перестает помогать — экоическая
информация, по-видимому, исчезла (или по крайней мере исчезла настолько значительная
ее доля, что даже ключ оказывается бесполезным). Как и следовало ожидать, по
мере увеличения интервала между первоначальным звуком и ключом последний обычно
становится все менее и менее эффективным: очевидно, след звука в экоической
памяти постепенно угасает.
Рассмотрим, например, что происходит с испытуемым, когда он прислушивается
к определенному слову на фоне заглушающего шума, который действует примерно
так же, как атмосферные помехи при приеме радиопередачи (Pollack, 1959). Испытуемый
не может сразу разобрать это слово изшума. Спустя некоторое время после предъявления
слова испытуемому предлагают пробу с двухальтернативным вынужденным выбором.
Проба состоит в зрительном предъявлении ему двух слов — того, которое он слышал,
и какого-нибудь другого (дистрактора) — с просьбой указать, какое из них он
слышит вторично. Одно из этих слов выполняет роль ключа, о котором говорилось
выше. Оно должно помочь испытуемому понять предъявленное ранее слово — в той
мере, в какой испытуемый еще помнит услышанный им звук.
В этом и в других сходных по форме экспериментах (см., например, Crossman,
1958; Guttman a. Julesz, 1963) максимальная задержка, при которой ключ помогает
идентификации, а тем самым и оценка длительности сохранения информации в экоической
памяти варьируют от 1 с до 15 мин диапазон весьма широкий. Ввиду таких расхождений
в оценках трудно определить, сколько же времени звуки удерживаются в слуховом
регистре. Что касается таких высоких оценок, как 15 мин, то здесь возникают
некоторые сомнения в их достоверности. Эти оценки основаны на предположении,
что испытуемый все еще удерживает в памяти первичный, неидентифицированный след
звука, когда ему предъявляют ключ, и что он использует этот ключ для идентификации
звука. Возможно, однако, что испытуемый на самом деле уже произвел частичную
идентификацию. Например, он размышляет: "Слово начиналось со звука с
и состояло, кажется, из двух слогов". Теперь он помнит уже не просто звук, а
свое словесное описание этого звука и может легко удержать это описание в памяти
на протяжении 15 мин. Тогда не удивительно, что и после значительного перерыва
испытуемый, получив ключ "Это либо "сурок", либо "понять"", идентифицирует услышанное
слово. По всей вероятности, 15-минутное сохранение экоических следов можно объяснить
именно такой частичной идентификацией. Вместе с тем упомянутое расхождение в
оценках, может быть, отчасти отражает действительные различия во времени подлинного
экоического хранения, зависящие от различий в характере предъявляемых стимулов
и в условиях эксперимента.
На сенсорном уровне следы звуков обычно сохраняются дольше, чем зрительные
образы. Этот факт был использован для объяснения так называемых эффектов модальности
(Crowder a. Morton, 1969; Morton, 1970; Murdock a. Walker, 1969). Один из примеров
эффекта модальности можно видеть на кривых зависимости частоты свободного припоминания
от места в ряду. При зрительном предъявлении списка слов (когда испытуемый видит
слова) получаются несколько иные результаты, чем при слуховом предъявлении слов
(когда он их слышит). Различие касается концевого участка кривой. При слуховом
предъявлении процент припоминания для слов, стоящих в конце списка, выше, чем
при зрительном, тогда как в начальном участке кривой такого различия нет. Иными
словами, несколько последних элементов списка запоминаются лучше, когда испытуемый
слышит их, чем когда он их видит. Это и есть эффект модальности.
Влияние модальности на вспоминание объясняют различной длительностью сохранения
следов в экоической и иконической памяти. При этом указывают на то, что если
список был предъявлен в слуховой форме, то информацию о самых последних элементах
списка можно извлечь из экоической памяти (это возможно благодаря тому, что
информация относительно звучания этих элементов сохраняется в течение нескольких
секунд, т. е. на протяжении всего интервала между их предъявлением и вспоминанием),
а иконическая информация о тех же самых элементах при их зрительном предъявлении
удерживается недостаточно долго, чтобы создать какую-либо основу для их воспроизведения.
Таким образом, слуховое предъявление обладает, явным преимуществом.
Такое объяснение эффектов модальности подкрепляется данными, полученными при
разной скорости предъявления элементов (Murdock a. Walker, 1969): различия между
воспроизведением после слухового и зрительного предъявления при больших скоростях
выражены сильнее, чем при малых. Именно таких результатов следовало ожидать,
если объяснять эффекты модальности особенностями сенсорных регистров. Ведь при
большой скорости интервал между предъявлением элемента и его припоминанием короче,
чем при малой; таким образом, времени для угасания следов меньше, и поэтому
в момент начала припоминания списка, предъявленного в слуховой форме, в экоической
памяти находится больше элементов, что создает преимущество для их припоминания.
В отличие от этого на удержание иконического образа скорость предъявления не
оказывает существенного влияния (отчасти из-за быстрого стирания иконических
следов, а отчасти потому, что при высоких скоростях последующие зрительные стимулы
могут стирать те, которые им предшествовали); поэтому при больших скоростях
число элементов, удерживаемых виконической памяти после зрительного предъявления,
не возрастает и не создается преимущества для их припоминания. Таким образом,
слуховая модальность выигрывает от быстрого предъявления больше, чем зрительная.
Из всех этих рассуждений относительно эффектов модальности вытекает, что в
экоической памяти может одновременно сохраняться несколько слов из списка, предъявленного
в эксперименте со свободным припоминанием. А это означает, что каждое новое
слово не стирает слова, которые ему предшествовали. Возникает вопрос: происходит
ли вообще стирание экоического образа? Ответ на этот вопрос зависит оттого,
что мы будем понимать под стиранием. Если под стиранием иметь в виду нечто эквивалентное
стиранию зрительного образа, т. е. подлинную замену одного стимула другим, который
за ним следует, то ответ, пожалуй, будет отрицательным. Вряд ли можно думать,
что звук, непосредственно следующий за предъявлением какого-либо другого звука,
эффективно элиминирует его. Мы уже отмечали, что, поскольку звуки следуют друг
за другом во времени, должен существовать какой-то механизм для их удержания.
Наша способность распознавать последовательности звуков должна означать, что
новые звуки не стирают другие, только что им предшествовавшие. Если бы они их
стирали, мы не могли бы понять фразу "seal, not zeal" (стр. 45). Мы
вообще не могли бы воспринимать речь, поскольку произнесение даже одного слога
требует некоторого времени и нельзя, чтобы вторая его часть стирала первую.
Однако и в экоической памяти все же, видимо, существует какое-то явление, подобное
стиранию. Новые звуки могут в некоторой степени маскировать или уменьшать длительность
хранения звуков, предъявленных ранее (Massaro, 1972). Это явление лучше называть
интерференцией, чтобы отличать его от быстрого и полного стирания, более четко
выраженного в иконической памяти. Эта экоическая интерференция сходна с эффектом
светлого поля, предъявлявшегося в экспериментах Сперлинга после набора букв,-она
уменьшает время сохранения следов, но не уничтожает их сразу.
Один из
способов, позволяющих продемонстрировать экоическую интерференцию,- это
"эффект приставки". Из двух кривых, представленных на рис. 3.6, одна
отражает число ошибок при воспроизведении различных элементов в зависимости от их положения в небольшом ряду, предъявляемом на
слух. Другая
кривая отражает результаты, полученные при добавлении к этому ряду цифры
"нуль" в качестве приставки. Хотя
испытуемые никак не должны были реагировать на нуль и знали о том, что он
появится, припоминание в этом случае было гораздо менее эффективным, чем в
контрольном опыте, когда за элементами не следовал нуль.
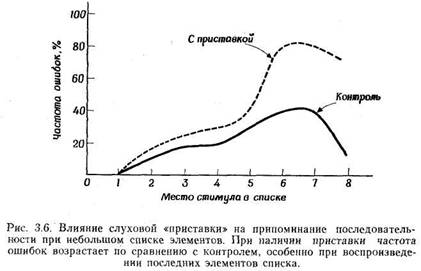
Эффект
приставки объясняли тем, что добавление приставки мешает сохранению
экоических следов (Morton,
1970): звук, который
испытуемый слышит при произнесении слова "нуль", разрушает информацию,
которая уже находилась в экоической памяти и могла бы помочь припоминанию
элементов ряда. В самом деле, при наличии приставки частота верного
воспроизведения снижается до уровня, соответствующего вспоминанию при
зрительном предъявлении ряда: это говорит в пользу того, что утрачивается
именно информация, находившаяся в экоической памяти, т. е. та, которая создает эффект модальности.
Степень интерференции, создаваемой
приставкой, варьирует в зависимости от соотношения последней с
предшествующими звуками (Morton а. о., 1971). Если, например, список
элементов зачитывает мужской голос, а приставку-женский, то эффект
приставки бывает выражен слабее, нежели в тех случаях, когда и список и
приставка произносятся одним и тем же голосом. Если приставка произносится
гораздо громче, чем элементы списка, то эффект ее опять-таки снижается. Эти примеры позволяют предполагать, что в тех
случаях, когда приставка отличается по звучанию от элементов списка,
создаваемая ею интерференция выражена слабее.
Приведенные объяснения различий, зависящих от модальности, и эффекта приставки
вызвали ряд возражений. В случае эффектов, создаваемых приставкой, одна трудность
связана с тем, что такие эффекты возникают и в зрительной сфере. Нейссер
и Канеман (см. Kahneman, 1973) просили испытуемых вспоминать короткие ряды цифр,
предъявлявшиеся им зрительно в течение 0,5 с. Иногда в конце списка ставился
нуль, который испытуемые не должны были вспоминать (ряд цифр при этом
имел вид "1375260" в отличие от ряда "137526", без приставки). В этом случае
приставка оказывала такое же действие — воспроизведение ухудшалось, хотя ряды
были хорошо видны и испытуемые знали, что они не должны обращать внимания на
приставку.
В отличие от эффектов
слуховых приставок эффекты зрительных приставок трудно объяснить
свойствами сенсорной памяти. Канеман (Kahneman, 1973, стр. 133) высказал
предположение, что все эффекты приставок обусловлены процессами,
следующими за сенсорной регистрацией, которые организуют
зарегистрированные входные сигналы в группы. Поскольку при такой
группировке "нуль", т. е. приставка, не может быть отделен от
остальных цифр, особенно если его произносит тот же голос, его приходится
включать в какуюнибудь группу, а это включение затрудняет вспоминание элементов ряда. Таким образом, Канеман относит эффект слуховой приставки
к явлениям, независимым от механизмов стирания информации в экоической
памяти.
Истолкование эффектов модальности, наблюдаемых в экспериментах с припоминанием,
на основе различий в длитель"ности сохранения экоических и иконических следов
также вызывает ряд возражений. Например, Мэрдок и Уокер (Murdock a. Walker,
1969) указывают, что при слуховом предъявлении запоминание последних элементов
списка улучшается даже в тех случаях, когда период, в течение которого предъявляются
эти элементы, превышает предполагаемое время сохранения экоических образов.
Но если это так, то эффект модальности нельзя полностью отнести на счет экоической
памяти.
Еще одна проблема (Watkins a. Watkins, 1973) возникает в связи с тем, что эффект
модальности проявляется для нескольких последних слов списка независимо от того,
состоят ли эти слова из одного или четырех слогов. Таким образом, те места в
ряду, где обнаруживается преимущество слухового предъявления (каждому месту
соответствует одно слово), всегда одни и те же, независимо от длины отдельных
элементов. Это, конечно, означает, что на длительность эффекта модальности,
измеряемую числом мест в ряду, не влияет то, сколько времени займет слуховое
предъявление соответствующих элементов (ведь для произнесения четырехсложных
слов нужно больше времени, чем для слов, состоящих вceгo лишь из одного слога).
Эти данные наводят на мысль, что этот эффект не связан с особенностями экоической
памяти, поскольку длительность предъявления слов, несомненно, должна сказываться
на сохранении экоических образов.
Как показывают только что рассмотренные критические замечания, теории экоической
памяти не дают полного объяснения природы экоических образов. В связи с изучением
сенсорных регистров возникает также ряд более общих проблем. В качестве иллюстрации
отметим, что сенсорный регистр, который мы называем экоической памятью, называюттакже
прекатегориальным акустическим хранилищем (Crowder a. Morton, 1969). Термин
"прекатегориальный" очень важен-он указывает на то, что находящаяся в сенсорных
регистрах информация содержится в них не в виде распознанных, отнесенных к определенным
категориям элементов, а в "необработанной" сенсорной форме. Стимулы, предъявленные
зрительно, содержатся в них в форме зрительных образов, предъявленные на слух-в
виде звуков и т. д. Когда произойдет распознавание образов, зарегистрированная
информация будет находиться уже не только в сенсорных регистрах; после распознавания
сенсорные следы быстро угасают.
Здесь необходимо подчеркнуть прекатегориальную природу сенсорных регистров,
поскольку центральная проблема исследований, касающихся регистров,- это отделение
эффектов, обусловленных самими сенсорными регистрами, от возможных влияний распознанной
информации. В экспериментах Сперлинга, например, это отделение достигалось путем
сравнения количества информации, которая может удерживаться сразу после предъявления
стимула, с тем ее количеством, которое сохраняется в течение нескольких секунд.
В экспериментах с экоическими образами иногда пытались провести такое разделение,
предъявляя испытуемым информацию, которую они не могли распознать, например
слова на фонешума, и мы отмечали, что, быть может, при этом не удалось полностью
исключить переработку первичных сенсорных данных. К числу возможных последствий
этого, вероятно, относятся завышенные оценки продолжительности сохранения экоических
образов и неверные интерпретации эффекта приставки.
В более общем плане
можно сказать, что при изучении памяти нередко бывает важно определить
форму, в которой хранится информация, способ ее кодирования. Одно и то же
слово может содержаться в памяти в форме звука, в графической форме, в
качестве метки или в виде сложного комплекса значений. Очень часто
психолоти хотели бы отделить хранение информации в форме вербальных меток
от какоголибо иного кода. Мы увидим, например, что некоторые ис"седователи пытались отличать хранение в вербальной форме от такого
хранения в зрительной форме, которое не является ни сенсорным, ни
вербальным. Этот последний вид хранения информации был назван "образной
памятью". По.добные проблемы особенно важны при изучении человеческой памяти, так как только человек способен описывать словами то, что
он видит и слышит. Эта присущая ему одному способность использовать для
хранения информации язык дает .возможность кодиров,ать запоминаемый материал
несколькими различными способами: поэтому различение разных кодов
становится важной проблемой теоретического изучения памяти.
Глава 4
Распознавание образов
Распознавая тот или иной образ, мы извлекаем смысл из некоторых сенсорных данных.
Процесс распознавания образов имеет фундаментальное значение для нашего поведения,
поскольку он составляет часть взаимодействия между реальным миром и сознанием
субъекта. Для распознания данного образа информация, находящаяся в одном хранилище
памяти, сенсорном регистре, должна быть сопоставлена с информацией, находящейся
в другом хранилище-долговременной памяти. Информация первого рода только что
поступила в виде некоторого стимула, информацию второго рода составляют приобретенные
ранее сведения об этом стимуле. Если, например, нам предъявлен стимул, состоящий
из трехлиний (/,\ и -), то мы распознаем в нем букву А. В таком случае мы можем
дать этому стимулу название-из одного или нескольких слов (например, "это буква
А"). Распознание образа не всегда означает словесную формулировку; нередко мы
распознаем образы, не называя их (мы можем, например, распознать некое лицо
как знакомое; какой-то запах может напомнить нам о месте, где мы его раньше
ощущали). Так или иначе, информация, поступающая от органов чувств (о контурах,
лицах, запахах и т. п.), сопоставляется и соотносится со всем тем, что нам известно
об окружающем мире.
Нетрудно понять, что изучение распознавание образов составляет важную часть
исследования памяти/Во-первых, оно связано с изучением таких хранилищ информации,
как сенсорные регистры и долговременная память (ДП). Во-вторых, обсуждая процесс
распознавания образов, мы столкнемся с необходимостью выяснять характер представления
хранимого материала в памяти — информационного кода памяти. (Вообще "кодом"
памяти называют способ представления в ней информации.) И наконец, мы рассмотрим
некоторые процессы, связанные с кодом памяти. Все это станет яснее, если мы
обсудим вначале, какими общими чертами должна обладать любая модель или теория
распознавания образов.
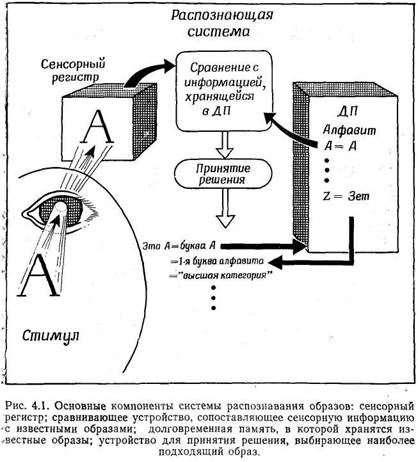
Упрощенная схема распознавания образов представлена на рис. 4.1. Можно видеть,
что этот процесс слагается из нескольких этапов. Прежде всего подлежащий распознаванию
стимул поступает, в сенсорный регистр. Поскольку след сохраняется здесь очень
недолго, процесс распознавания должен быстро завершиться, пока в регистре еще
есть информация о стимуле. Сам процесс распознавания заключается в сопоставлении
входного стимула с закодированной информацией, находящейся в ДП, а это означает,
что информация в ДП должна быть представлена в такой форме, чтобы стимул можно
было с ней сравнивать. Иначе говоря, хранящееся в ДП закодированное представление
о стимуле должно быть в некотором смысле похожим на этот стимул или как-то описывать
его внешний вид или форму. После сравнения входного стимула с содержащимися
в ДП кодами принимается решение о том, какой из этих внутренних кодов наилучшим
образом соответствует данному стимулу. От этого решения зависит выходной сигнал
распознающей системы — сообщение о результате принятого решенияонечно, после
того как образ распознан, из ДП может быть извлечена дополнительная информация
о нем. Например, распознав в предъявленном стимуле букву А, мы можем затем припоминать
все, что нам о ней известно: это первая буква алфавита; с этой буквы начинается
слово "арбуз"; это обозначение футбольных команд высшего класса и так далее.
Итак, мы видим, что процесс распознавания образов состоит из нескольких сложных
субпроцессов. Это прежде всего сенсорная регистрация, рассмотренная в предыдущей
главе. Затем идут процессы сравнения и принятия решения. Здесь возникают вопросы,
связанные с представлением информации. В какой форме закодирована та хранящаяся
в ДП информация, с которой сравнивается входной стимул? Насколько закодированный
стимул сходен с первоначальным? В остальных разделах этой главы мы рассмотрим
кодй памяти и некоторые процессы сравнения и принятия решения, которые можно
постулировать для системы распознавания образов.
КОДЫ ПАМЯТИ И РАСПОЗНАВАНИЕ
ЭТАЛОНЫ
Мы начнем рассмотрение кодов памяти с тех кодов ДП, которые используются при
сопоставлении прошлого опыта с вновь поступающими стимулами. Что это за коды?
Код должен либо соответствовать данному стимулу, либо описывать его, иначе он
не сможет быть образцом для сравнения. Одна из возможных гипотез состоит в том,
что хранящийся в ДП код представляет собой миниатюрную копию (или "эталон")
данного стимула; для каждого распознаваемого нами стимула в ДП имеется его внутренний
дубликат, который и используется при распознавании. Согласно этой гипотезе,
для распознавания образа приходится сравнивать данный стимул с длинным рядом
эталонов, хранящихся в ДП. Распознание совершится в тот момент, когда будет
выбран наиболее подходящий для данного стимула, эталон и тем самым
определится, что же представляет собой этот стимул.
Однако гипотеза эталонов слишком проста; она чересчур наивна, чтобы служить
основой для теории распознавания образов. Ее главный недостаток-огромное количество
необходимых эталонов. Рассмотрим, например, распознавание одного не очень сложного
стимула — буквы А. Согласно гипотезе эталонов, в ДП имеется копия этой буквы,
с которой сравнивается любой стимул, похожий на А, когда бы он ни появился,
и которая соответствует ему лучше, чем любой другой эталон. Отсюда, однако,
следует, что нам понадобится отдельный эталон для каждой разновидности буквы
А. Изменилась величина стимула? Нужен другой эталон. Если слегка повернуть букву,
нужен будет еще один эталон. Для какого-нибудь своеобразного начертания, например 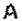 , опять-таки потребуется свой особый эталон. Если у нас не будет эталонов для
всех этих разновидностей буквы А, то при распознавании неизбежно возникнут ошибки.
Например, может оказаться, что наклонное А лучше соответствует эталону для R,
чем для А, и тогда, встретившись с А, мы распознаем его как R. Чтобы исключить
возможность таких ошибок, понадобится бесчисленное множество эталонов,
несомненно гораздо большее, чем может вместить ДП. , опять-таки потребуется свой особый эталон. Если у нас не будет эталонов для
всех этих разновидностей буквы А, то при распознавании неизбежно возникнут ошибки.
Например, может оказаться, что наклонное А лучше соответствует эталону для R,
чем для А, и тогда, встретившись с А, мы распознаем его как R. Чтобы исключить
возможность таких ошибок, понадобится бесчисленное множество эталонов,
несомненно гораздо большее, чем может вместить ДП.
Гипотезу эталонов можно видоизменить, сделав ее гораздо более приемлемой. Одна
модификация состоит в том, чтобы добавить к модели процесс, который предшествует
сопоставлению и служит для "очистки" входного стимула. Такая предварительная
обработка могла бы придавать стимулу стандартное положение и стандартные размеры.
Этот процесс называют "нормализацией", так как он устраняет различные неправильности
в форме стимула и приводит его к более обычному виду. Например, если стимул
имел вид 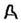 , то в результате нормализации он уменьшился
бы, искривленная правая часть была бы выпрямлена, и все это произошло бы еще
до сравнения стимула с эталоном. Подобный процесс сильно сократил бы число эталонов,
необходимых для распознавания буквы А. , то в результате нормализации он уменьшился
бы, искривленная правая часть была бы выпрямлена, и все это произошло бы еще
до сравнения стимула с эталоном. Подобный процесс сильно сократил бы число эталонов,
необходимых для распознавания буквы А.
Однако нормализация, предшествующая сравнению, не позволяет снять все трудности,
связанные с эталонной гипотезой. Логически возникает следующее возражение: для
того чтобы знать правильную ориентацию и величину стимула, нужно заранее
знать, какой образ представляет данный стимул. Например, какую ориентацию должен
иметь стимул, имеющий вид наклоненного Q? В одном случае он будет выглядеть
как Р, а в другом как Q. Чтобы знать, какой из этих двух поворотов будет правильным,
необходимо сначала решить, какая это буква. Но эта задача возлагается именно
на систему распознавания, а не на
предшествующий ей преобразователь. С этой логической проблемой, однако,
нетруд но справиться. Во-первых, при резких отклонениях стимула от
стандартной ориентации он, по всей вероятности, окажется: нераспознаваемым.
Иными словами, нет нужды постулировать, что этот предварительный процесс
сможет переработать сильно наклоненную букву Q, если в действительности
распознающая система не способна иметь дело с такого рода стимулами.
Во-вторых, подлежащие распознаванию стимулы обычно включены в какой-то более
обширный контекст, и этот контекст может помогать процессу нормализации, подсказывая, как нужно изменить положение или величину данного
стимула.
В более общем плане контекст сильно помогает процессу распознавания, сокращая
число образов, которым мог бы соответствовать данный стимул. Кроме того, контекст
облегчает решение таких проблем, как распознавание совершенно новых стимулов.
Как нам удается распознать такой стимул, как , если мы
его никогда раньше не видели? Совершенно очевидно, что в ДП не может быть соответствующих
эталонов. В каком качестве будет распознан подобный стимул, зависит от того,
когда и где мы с ним встретимся. Если он появится при обсуждении распознавания
букв алфавита, то он, возможно, будет воспринят как буква А, если же мы встретим
его в такой карикатуре:

то вряд ли он нам покажется похожим на А.
ПРОТОТИПЫ
Контекст может помочь нам справиться с некоторыми трудностями, присущими гипотезе
эталонов, но он не позволяет решить проблему полностью. Дело в том, что многие
стимулы, которые мы умеем распознавать, предстают перед нами вне специального
контекста, и тем не менее мы распознаём их, несмотря на различия в размерах и
ориентации.
В связи с этим нужно, по-видимому,
иметь такую эталонную систему, которая допускает некоторые вариации или
"расплывчатость" входящих в нее образов. Иными словами, распознающее устройство должно хорошо работать и при наличии мелких
вариаций, которые могут оставаться после "очистки" стимула. После
введения в распознающее устройство эталонов, допускающих вариации, система
становится более сходной с так называемой системой прототипов, или системой, основанной на схемах.
Схема-это просто набор правил для создания или описания прототипа, под которым
мы здесь имеем в виду некую .абстрактную фигуру, отображающую основные элементы
какого-то множества стимулов. Например, прототип самолета можно представлять
себе в виде длинной трубы, к которой прикреплены два крыла; все самолеты окажутся
различными вариантами этого прототипа. Иными словами, прототип-это некая сущносгь,
некая главная или средняя тенденция, даже если хотите, платонова "идея". Согласно
прототипной гипотезе распознавания образов, в ДП хранятся прототипы обобщенные,
идеализированные образцы известного множества стимулов. Теоретически любой стимул
можно закодировать в виде Трототипа в сочетании с перечнем вариаций, после чего
все поступающие стимулы можно сопоставлять с прототипами, а не с эталонами.
(Таким образом, концепция эталонов заменяется здесь концепцией прототипов).
Предполагается, что наша долговременная память содержит прототипы всех распознаваемых
нами категорий-собак, человеческих лиц, букв А и т. д.,- что и позволяет нам
узнавать отдельных представителей этих категорий.
Существуют ли прототипы на самом деле? Судя по некоторым экспериментальным
данным, на этот вопрос можно ответить утвердительно: известны случаи формирования
прототипов для множеств стимулов. Например, Познер и Кил (Posner a. Keele, 1968)
провели эксперимент, в котором испытуемые вели себя так, как если бы у них вырабатывались
прототипы. Прежде всего Познер и Кил построили прототипические образы, состоявшие
из 9 точек каждый. В некоторых случаях эти точки располагались в виде геометрической
фигуры, например треугольника, в других-в виде буквы, в третьих-случайным образом.
Затем, несколько сдвигая некоторые точки, экспериментаторы создавали новые фигуры-искаженные
формы тех же прототипов (рис. 4.2, А). Иногда точки сдвигались в одном направлении,
иногда — в другом, так что исходный прототип соответствовал фигуре, которая
бы получилась, если бы мы поместили каждую точку в среднее положение по отношению
ко всем отклонениям. Создав прототипы и по нескольку искажений каждого из них,
Познер и Кил приступили к экспериментам на нескольких группах испытуемых. Рассмотрим
пример, когда прототипы представляли собой случайные группировки точек; отклонения
от прототипов при этом тоже, конечно, были случайными наборами. Испытуемым показывали
сначала (одно за другим) четыре отклонения от каждого из трех случайных прототипов.
Им предлагалось классифицировать каждое отклонение, т. е. указать, к какой из
трех категорий оно принадлежит. Все отклонения, соответствующие одному прототипу,
следовало относить к одной и той же категории, однако испытуемым не показывали
ни один из прототипов. В конце концов испытуемые научились правильно классифицировать
фигуры, т. е. относить все отклонения от одного прототипа в одну категорию,
все отклонения от другого — в другую и т. д. Затем испытуемым дали новую задачу
на классификацию. Им предъявили ряд фигур и попросили отнести каждую из них
к одной из установленных ранее трех категорий. Некоторые из этих фигур испытуемые
уже видели прежде (известные отклонения), другие представляли собой новые искажения
того же прототипа, а третьи были сами прототипы, которых испытуемые раньше не
видели. Известные отклонения, как и следовало ожидать, классифицировались довольно
удачно-частота правильных ответов составляла 87%. Неожиданным оказалось то,
что примерно так же хорошо классифицировались прототипы, хотя испытуемые никогда
их прежде не видели. Однако новые отклонения, которые испытуемые увидели впервые,
классифицировались менее точно-частота правильных ответов составляла здесь уже
только 75%. Ввиду высокой точности классификации прототипов авторы высказали
мнение, что испытуемые, обучаясь классифицировать первую группу отклонений,
на самом деле усвоили и прототипы. Иными словами, испытуемые абстрагировали
некую среднюю тенденцию — представление о прототипе-из ряда стимулов, которые
были вариациями этого прототипа.
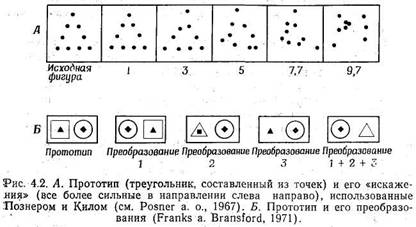
В других экспериментах сходного рода были получены еще более веские доводы
в пользу теории прототипов. Фрэнке и Брэнсфорд (Franks a. Bransford, 1971) создали
прототипы, составляя структурные группы из нескольких геометрических фигур (треугольник,
круг, квадрат и т. п.; рис. 4.2, Б). Затем путем одного или нескольких преобразований
прототипа получали отклонения от него. Преобразование могло состоять, например,
в удалении одной фигуры из данной группы, в замене ее другой фигурой и т. п.
Испытуемым сначала показывали несколько отклоняющихся образов, а затем проводили
тест на распознавание. При этом им предъявляли ряд образов-несколько искажений,
которые они видели ранее, несколько таких, которых они прежде не видели, и прототипы
— и просили сказать относительно каждого, узнают они его или нет. В каждой пробе
испытуемые должны были также указать, насколько они уверены в том, видели они
данный образ в первоначальном наборе или нет. Как показывают эти оцеяки кажущейся
достоверности, испытуемые были больше всего "уверены" в том, что они видели
раньше прототипы, хотя в первой части эксперимента прототипов им не показывали.
Более того, на основании степени близости того или иного варианта к прототипу
можно было предсказывать степень уверенности испытуемых. Наибольшей она была
при "узнавании" прототипов; за ними шли структурные группы, подвергшиеся только
одному преобразованию, затем двум и так далее. Варианты, виденные раньше, распознавались
ничуть не лучше, чем новые варианты, отличавшиеся от прототипа тем же числом
преобразований.
Судя по результатам этих экспериментов, ознакомление с группой близких фигур
приводит к выработке прототипического представления об этой группе. В таких
случаях говорят, что испытуемые абстрагируют из виденных ими фигур некий образ-прототип.
Эксперимент Фрэнкса и Брэнсфорда позволяет также предполагать, что испытуемые
могут использовать такие прототипы при идентификации новых образов. Удача или
неудача при распознавании данного образа определялась степенью искажения или
преобразования прототипа, а предъявлялась данная фигура раньше или нет, не имело
значения.
Итак, согласно прототипной теории распознавания образов в ДП чeловекa хранятcя
прототипы образов для каждого рода информации, например прототипы букв, лиц
или фигур, составлeнныx из точек. Встречаясь с новым образом, распознающая система
сопоставляет его с этими прототипами, проверяя не точное (эталонное), а скорее
приблизительное соответствие допускающее некоторую изменчивость стимула. Какой
прототип будет лучше всего соответствовать данному стимулу, такой образ и будет
распознан в этом стимуле. Подобная модель, включающая также механизм предварительной
обработки стимула, представляет значительный шаг вперед по сравнению с наивной
эталонной гипотезой.
ЭЛЕМЕНТЫ ОБРАЗА
До сих пор мы рассматривали распознавание образов, не давая определения слову
"образ" (pattern); это, конечно, серьезное упущение. Согласно одному из определений
(Lusnе, 1970), образ — это конфигурация из нескольких элементов, составляющих
некое целое. Подобное определение подразумевает, что любой образ можно разбить
на более простые элементы и что при воссоединении этих элементов вновь возникает
образ. Например, можно представить буквы алфавита состоящими из таких элементов,
как вертикальные линии, горизонтальные линии, линии с наклоном в 45 градусов
и кривые. С этой точки зрения букву А можно представить как / плюс \ плюс —
. Эти элементы в надлежащем сочетании дают образ буквы А. В общем концепция
элементов, или элементарных признаков, сводится к тому, что из относительно
небольшого множества более простых частей, взятых в различных сочетаниях, можно
создать все образы, входящие в некое более мощное множество (например, множество
печатных букв алфавита).
Другой пример множества образов, которые можно создать из более простых элементов
("признаков"), — это устная речь. Речь состоит из основных звуковых единиц,
называемых фонемами и аналогичных буквам, из которых слагаются слова, предъявляемые
зрительно. Фонему можно определить как такой звук, который, изменяясь как отдельный
элемент, может изменить смысл слова. Например, звуки, соответствующие буквам
л, в или б в словах лес, вес, и бес, представляют собой разные фонемы, потому
что каждый из этих звуков изменяет смысл произносимого слова. Одна фонема может
быть представлена множеством акустических вариантов, так как каждый человек
произносит ее немножко иначе, чем другие, но тем не менее мы узнаем одну и ту
же фонему, произносимую разными людьми. Все это означает, что мы можем считать
фонему единицей речи, некой абстракцией, объединяющей множество сходных звуков.
В этом смысле ее можно сравнить с рукописной буквой, которую каждый человек
выводит немножко по-своему, но которую тем не менее всегда удается распознать.
Выявление набора признаков, которые можно использовать в различных сочетаниях
для получения фонем (подобно тому как можно использовать прямые и кривые линии
и углы в качестве основы для получения печатных букв), — очень трудная проблема,
но все же было сделано несколько попыток решить ее. Один из методов основан
на том, чтобы исследовать механизм артикуляции звуков и попытаться описать каждый
звук речи в соответствии с тем, как человек использует при его произнесении
свой речевой аппарат. В речевой аппарат входят язык, нос, зубы и губы, голосовые
связки и мышцы диафрагмы.
Рассмотрим, например, звуки с и з. Попробуйте произнести
каждый из них, и вы сможете заметить, что при произнесении з звук кажется
исходящим из горла, тогда как в произнесении с участвует только рот.
По этому признаку звуки делят на глухие и звонкие: с — глухой звук,
при его произнесении голосовые связки неподвижны; з — звонкий звук,
при его произнесении голосовые связки вибрируют. Поэтому говорят, что эти два
звука различаются по одному признаку — звонкости. Конечно, звуки речи обладают
и многими другими признаками. К ним относятся положение языка в ротовой полости
(переднее, среднее или заднее), прохождение воздуха через нос или только через
рот и многие другие. Предполагается, что каждой фонеме соответствует единственное
в своем роде сочетание таких признаков — какая-то специфическая для нее конфигурация
речевого аппарата. Исследуя речевую артикуляцию, пытаются выявить набор элементов,
характеризующий каждую отдельную фонему.
Несмотря на все старания установить отличительные
признаки звуков речи или печатных букв, полного успеха достигнуть не
удалось, хотя некоторые результаты можно считать удовлетворительными. Тем не
менее идея о возможности описывать образы при помощи набора элементарных
признаков кажется весьма привлекательной. Выработана довольно подробная
спецификация фонем английского языка, основанная на их отличительных
признаках (Jakobson а. о., 1961); возможно также установить элементарные
признаки различных печатных букв для
шрифтов определенного типа (Rumelhart, 1971). Например, буквы алфавита можно
описать при помощи одних только вертикальных и горизонтальных линий,
если принять такие начертания, как  ... ...
Итак, мы рассмотрели сначала наивную эталонную гипотезу и установили ее полную
непригодность. Однако мы нашли, что если добавить к ней процесс предварительной
обработки (небольшое видоизменение входного стимула, придающее ему стандартные
размеры и положение) и концепцию прототипа, то можно создать модель гораздо
лучшую, чем эталонная система. Другая альтернатива эталонной гипотезы, к рассмотрению
которой мы сейчас переходим, — это гипотеза признаков. Согласно этой гипотезе,
подлежащий распознаванию стимул сначала анализируется по отдельным признакам.
В результате составляется перечень признаков, при объединении которых получился
бы данный стимул. Затем этот перечень сравнивается с перечнями, хранящимися
в ДП. Таким образом, код ДП для данного стимула представляет собой перечень
признаков, а не эталон или прототип Выбирается-наиболее подходящий перечень,
что и приводит к распознанию образа.
Одной из теоретических моделей, основанных на анализе признаков, является система
"Пандемониум" (Selfridge, 1959). Эта система представлена на рис. 4.3. Как и
в нашей общей модели (рис. 4.1), здесь предполагается, что процесс распознавания
образов состоит из нескольких этапов или уровней.
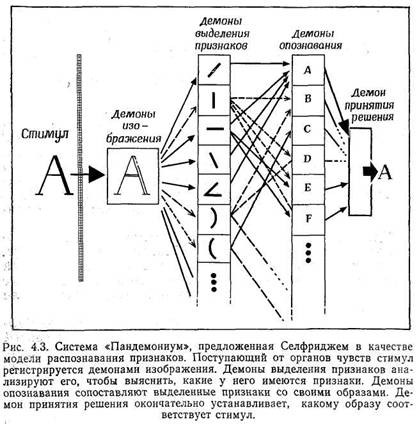
На каждом уровне имеется отряд "демонов", которые выполняют ту или иную работу,
связанную с распознаванием предъявленного образа. На первом уровне действуют
демоны изображения, которые заняты тем, что мы назвали сенсорной регистрацией,
т. е. регистрируют стимул как некое событие на сенсорном уровне. Затем это событие
анализируется демонами выделения признаков, которые разбивают первичное изображение
на составляющие элементы. Каждый такой демон ищет в изображении лишь один признак
— определенную прямую, расположенную под определенным углом, или кривую — и
регистрирует его, если находит. За демонами выделения признаков следят демоны
опознавания, соответствующие перечням признаков. Перечень, имеющийся у каждого
из таких демонов, относится к одному определенному образу, и работа этого демона
состоит в том, чтобы "кричать", или сигнализировать, тем громче, чем больше
"своих" признаков он найдет среди тех, которые были выделены в результате анализа
признаков. Наконец, на самом верхнем уровне восседает демон принятия решения
(процесс принятия решения); он должен установить, какой из демонов опознавания
кричит громче всех, и в результате распознать образ.
Не удивителько, если все эти рассуждения покажутся знакомыми, так как гипотеза
признаков очень сходна с гипотезой эталонов. Ведь в сущности всякий признак
является неким эталоном; только в данном случае эталон соответствует не стимулу
в целом, а лишь некоторой его части. Преимущество гипотезы признаков состоит
в том, что если можно выделить набор признаков, позволяющих описывать гораздо
более широкий круг образов (например, описать речь при помощи нескольких элементарных
признаков), то число эталонов, с которыми нужно иметь дело, резко сокращается.
Однако сходство гипотезы признаков с гипотезой эталонов влечет за собой множество
проблем, общих для них обеих.
Как, например, система, основанная
на анализе признаков, будет справляться с вариациями в величине того или
иного зрительного элемента? Как она будет распознавать новые признаки,
никогда прежде не виденные? Что произойдет, если два стимула будут
различаться только присутствием или отсутствием какого-либо элемента?
Примером может служить нижняя горизонтальная линия, которая есть у буквы
Е, но отсутствует у F. В этом случае в ДП могут найтись два перечня
признаков, подходящих для опознания стимула F, так как все элементы буквы F
соответствуют признакам, содержащимся в перечнях как для Е, так и для F. В
случае распознавания элементов речи возникают еще большие сложности.
Прежде всего далеко не всегда ясно, где именно начинается или кончается
данная речевая единица, что сильно затрудняет разбиение образа на отдельные
признаки. Послушайте речь на незнакомом языке: вам будет казаться, что
человек говорит невероятно быстро, и почти невозможно будет решить, где
кончается одно слово и начинается другое. Если мы внимательно прислушаемся
к людям, говорящим по-английски, то мы обнаружим, что они нередко делают более длительные паузы в середине слова, чем между
двумя словами.
Пока у нас нет возможности окончательно разрешить все эти проблемы,
связанные с распознаванием образов. Это не значит, однако, что гипотезу,
основанную на анализе признаков, следует отбросить. В конце концов все
другие гипотезы также имеют свои недостатки. Кроме того, есть ряд
экспериментальных результатов, говорящих о том, что при распознавании
действительно используется метод сопоставления признаков.
Некоторые данные о роли анализа признаков в распознавании образов носят физиологический
характер. Показано, например, что в зрительной системе имеются специализированные
клетки, функции которых состоят в распознавании определенных признаков. За последние
10 -15 лет физиологи (Hubel a. Wiesel, 1962; Lettvin а. о., 1959) обнаружили
в зрительной системе кошек, лягушек и других животных нервные клетки, реагирующие
только на зрительные стимулы определенного типа. Это могут быть, например, горизонтальные,
вертикальные или движущиеся линии. Установлено, что в мозгу ля.гушки некоторые
клетки реагируют на появление в зрительном поле движущихся черных точек; было
высказано предположение, что эти клетки представляют собой "детекторы мух":
их реакция помогает лягушке добывать пищу! Существует явная аналогия между стимулами,
приводящими в действие специализированные нейроны, и тем, что мы называем здесь
признаками. Можно допустить, что у человека тоже есть клетки, которые разряжаются
при появлении тех или иных элементов сенсорного материала и выполняют в зрительной
системе роль анализаторов признаков. По-видимому, некоторые клетки реагируют
независимо от таких специфических характеристик стимула, как длина. Они могли
бы служить детекторами более абстрактных признаков (например, выявлять наличие
линии любой длины, расположенной под определенным углом); возможно, это помогло
бы понять, почему нам удается распознавать образы независимо от их величины
и т. п.
Есть и другие данные, свидетельствующие о важной роли признаков в
распознавании зрительных образов. Маленькие дети, например, часто путают
буквы b и d. Возможно, что это результат их неспособности различать два
элемента (например, с и э ), сходных во всем, кроме своей ориентации. У взрослых аналогичный эффект можно получить, предъявляя им
зрительные стимулы с такой быстротой, при которой восприятие может
оказаться неполным. В подобных экспериментах испытуемые делают ошибки такого
же рода, как и в экспериментах с определением объема памяти. Когда,
например, какая-нибудь буква предъявляется на очень короткое время, после
чего испытуемого просят назвать ее, он часто называет вместо предъявленной
буквы какую-нибудь другую. В отличие от ошибок, допускаемых при определении объема памяти, которые, по-видимому, вызываются
сходством по
слуховым признакам, ошибки в таких экспериментах обусловлены зрительным
сходством (Kinney а. о., 1966). В них D гораздо чаще называют вместо Q, чем
вместо В. Буквы Q и D имеют общие зрительные признаки, тогда как D и В
сходны на слух, но очень несходны по виду. Характер таких ошибок позволяет
думать, что зрительное восприятие букв основано на анализе признаков.
Из всего сказанного видно, что имеются данные как в пользу формирования прототипов,
так и в пользу анализа признаков. Мы убедились также в том, что многое в распознавании
образов поддается объяснению с помощью обеих гипотез, но в то же время многие
проблемы (причем одни и те же) ни та ни другая гипотеза разрешить не может.
Какая же из двух гипотез лучше? На
данном этапе ответ на этот вопрос остается неясным. Возможно, что обе гипотезы в каких-то случаях верны, так как ввиду большого разнообразия
распознаваемых нами стимулов механизмы их ра.епознавания могут быть разными.
Кроме того, возможно, что различия между тем, что мы называем прототипами и
признаками, не столь велики, как это
кажется. Во-первых, .эти две концепции можно объединить: можно рассматривать
лрототип как состоящий из признаков, общих для всех реа.лизаций
данного образа; тем самым идея прототипов становится столь же совместимой
с признаками, как она совместима с эталонами. Во-вторых, важно понять, что
на некотором уровне гипотеза, основанная на анализе признаков, очень
сходна с гипотезой эталонов. Одна из проблем, возникающих при формулировке
гипотезы признаков, касается того, каким образом происходит распознавание
отдельных признаков, например линий, образующих данный угол. Возможяо, что здесь придется постулировать процесс сравнения,
сопоставляющий
признак с внутренним эталоном. В результате получится эталонная теория
распознавания признаков! Эти соображения иллюстрируют ряд трудностей,
возникающих при попытке точно определить тип кодирования в ДП,
используемый при распознавании образов. Хотя нам, может быть, и не
удастся точно определить этот код, в наших рассуждениях о нем мы
значительно продвинулись вперед по "сравнению с наивной гипотезой
эталонов; при этом мы уяснили себе ряд важных моментов, касающихся
процесса расаюзнавания.
ПРОЦЕССЫ, СВЯЗАННЫЕ С РАСПОЗНАВАНИЕМ
В распознавании образов есть один этап, который мы пока еще подробно не обсуждали
,- это процесс сравнения и принятия решения. Рассмотрим в связи с этим гипотезу
эталонов. Каждый образ необходимо сравнивать с многочисленными эталонами, после
чего можно выбрать тот эталон, который лучше всего соответствует данному стимулу.
Понятно, что ввиду огромного количества хранящихся в памяти эталонов подобное
сравнение было бы очень громоздкой и трудоёмкой процедурой. Пришлось бы перебирать
многие тысячи эталонов, прежде чем удавалось бы принять решение. Как все это
могло бы осуществляться? Если бы распознающий механизм должен был сравнивать
входной стимул поочередно с каждым эталоном, то для узнавания некоторых стимулов
требовалось бы очень много времени; те же самые соображения относятся к "прототипам"
или "перечням признаков", если заменить ими "эталоны". А между тем мы знаем,
что образы распознаются очень быстро.
ПОСЛЕДОВАТЕЛЬНАЯ ИЛИ ПАРАЛЛЕЛЬНАЯ ПЕРЕРАБОТКА?
Один из ответов на этот вопрос может состоять в том, что распознающий механизм
не сравнивает новые стимулы со всеми хранящимися в ДП кодами поочередно, или,
как говорят, последовательно. Существует другая возможность — параллельное сравнение,
при котором одновременно производится множество отдельных сравнений, идущих
бок о бок. В этом случае подлежащий распознаванию стимул может одновременно
сопоставляться со многими внутренними кодами и весь процесс займет не больше
времени, чем одно такое сопоставление. Это означало бы, что сравнения могут
производиться очень быстро.
По-видимому, параллельная процедура могла бы в принципе
разрешить проблему экономии времени на этапе сравнения. Нам известны
примеры подобных параллельных процессов из области физики. Один пример
(Neisser, 1967) связан с использованием камертонов. Если взять камертон с
неизвестной собственной частотой и ударить по нему (так что он начнет
звенеть), держа его вблизи группы камертонов, обладающих известными
частотами, то один из них тоже начнет звенеть. Этот второй камертон
соответствует по частоте первому; ни один из остальных камертонов при этом
не зазвенит. Таким способом можно определить частоту исследуемого
камертона. Это процесс параллельного сравнения, так как камертон с
неизвестной частотой одновременно сопоставляется со всеми камертонами,
настроенными на известные частоты.
Имеются также данные о параллельном осуществлении психических операций. Один
такой пример обнаружен Нейссером (Neisser,. 1964) в экспериментах со зрительным
поиском. В этих экспериментах испытуемым предъявляли ряды букв, разбитые на
50 строк. В каждой строке было по нескольку букв, например U, F, С, J. Испытуемый
должен был, просматривая строки в направлении сверху вниз, как можно быстрее
найти определенную букву, заданную экспериментатором. Заданную букву помещали
на случайно выбранное место, и когда испытуемый находил ее, он должен был нажать
на кнопку. Регистрировалась общая продолжительность поиска, т. е. время от момента
предъявления испытуемому списка до момента нахождения им заданной буквы. Оказалось,
что если хорошо натренированному испытуемому задавали десять букв и просили
нажать на кнопку после нахождения одной из них, имевшейся в списке, то он делал
это так же быстро, как и в том случае, если ему задавали только одну букву (Neisser,
Novik a. Lazar, 1963). Этот результат говорит против процесса последовательного
поиска: если бы испытуемый искал десять заданных букв последовательно, просматривая
весь список в поисках сначала одной буквы, затем другой и так далее, то это
заняло бы (в среднем) гораздо больше времени, чем поиск всего лишь одной буквы.
Судя по полученным результатам, испытуемые могут искать все десять букв одновременно,
т. е. вести параллельный поиск.
Результаты
выполнения заданий на зрительный поиск показали также, что скорость
нахождения испытуемыми заданной буквы зависела в некоторой степени от
того, насколько эта буква отличалась по виду от остальных букв, имевшихся
в списке. Например, испытуемые находили букву Z среди букв О, D, U, G, Q
и R гораздо быстрее, чем среди букв 1, V, М, X, Е и W. В первый список
входили буквы с округленным контуром, гораздо менее сходные с буквой Z, чем
буквы из второго списка, имеющие угловатый контур. На основании этих
результатов Нейссер утверждает, что испытуемые, вместо того чтобы
сравнивать с содержащимися в списке буквами эталон заданной буквы, ищут в
этом списке ее наиболее характерные признаки. Угловатые очертания,
образующие букву Z, гораздо легче обнаружить среди округлых букв, чем
среди угловатых, так что время, затрачиваемое на поиск, будет зависеть
от общего вида букв, содержащихся в списке.
В своих теоретических
построениях, основанных на этих результатах, Нейссер использовал модель
"Пандемониум" Селфриджа, о которой говорилось выше. В этой модели
предполагается, что процесс распознавания образов происходит в
известном смысле последовательно, поскольку один его этап следует за
другим (сначала вступают в действие демоны выделения признаков, затем
демоны опознавания и т. д.). Однако на каждом этапе модели происходят и
параллельные процессы: например, все демоны опознавания следят за демонами выделения признаков и "кричат" одновременно.
РОЛЬ КОНТЕКСТА
Параллельные процессы — это лишь один, хотя и достаточно
эффективный, способ разрешения поставленной нами проблемы. Проблема эта
состоит в том, чтобы выяснить, каким образом достигается такая скорость
процессов сравнения и принятия решения, которая нужна для быстрого распознавания образов при огромном числе потенциальных возможностей выбора.
При параллельных процессах распознавание может происходить быстро потому,
что одновременно идет много операций, и это экономит время по сравнению с
последовательным процессом. Другой способ экономии временисокращение
масштабов процесса сравнения, уменьшение числа образов, которым мог бы
соответствовать данный стимул, а тем самым и числа эталонов или перечней
признаков, с которыми этот стимул нужно сравнивать. Такой подход к решению
проблемы может даже показаться логически невозможным. Как мы можем сократить число необходимых сравнений, не зная
заранее, что представляет собой стимул? Ответ на этот вопрос можно найти,
если рассмотреть роль контекста, в котором данный стимул появляется.
Вообще контекст, в который включен стимул, чрезвычайно важен для определения
того, как его следует в конечном счете классифицировать. Если известно, какие
стимулы могут встретиться в данной ситуации, то это позволяет исключить из рассмотрения
огромное количество образов. Например, если мы пытаемся распознать неясно произнесенное
слово в конце фразы "Быть или не быть, вот в чем..." и если мы слышим что-то
похожее на "допрос", то нам, вероятно, легко будет распознать здесь слово "вопрос".
Это может произойти даже в том случае, если сам стимул звучит скорее как "допрос",
чем как "вопрос". Таким образом, контекст — в данном случае хорошо известная
цитата — ограничивает число образов, которые будут иметь смысл, если поставить
их на место неясных звуков, и распознавание становится возможным, несмотря на
двусмысленность входного сообщения. Контекст уменьшает число образов, которым
мог бы соответствовать стимул, и позволяет уменьшить требования, предъявляемыек
системе.
С влиянием контекста мы нередко встречаемся в психологических исследованиях.
Примером могут служить эксперименты, показывающие, что при зрительном восприятии
букву легче идентифицировать, когда она предъявляется не сама по себе, а входит
в состав слова (Reicher, 1969; Wheeler, 1970). Было высказано мнение (Wheeler,
1970), что слово создает для буквы контекст, а одно из свойств контекста заключается
в том, что он направляет процесс анализа признаков. Идентификация одной буквы
в данном слове уже в силу того, что она входит в состав слова, ограничивает
возвозможные значения остальных букв. Поэтому можно ограничиться проверкой лишь
некоторых признаков, а другие просто отбросить, не проверяя.
Сходные эффекты наблюдаются и при слуховом восприятии слов. Это показано в
экспериментах, в которых иcпытуемые должны были идентифицировать слова, предъявлявшиеся
им на фоне шума (Miller а. о., 1951). Когда слова составляли осмысленные фразы,
их было гораздо легче понять, чем когда они располагались в случайной последовательности:
контекст создаваемый фразой, облегчал распознавание отдельных слов. Было также
высказано мнение (Miller, 1962), что при восприятии речи мы обычно сразу распознаем
целые группы фонем — целые слова или даже фразы. Это означает, что принимаемые
решения могут быть взаимозависимы и что решение, принятое относительно одной
фонемы, может создать контекст, облегчающий распознавание других звуков. Аналогичные
эффекты возможны при идентификации букв напечатанного слова во время чтения.
Распознавание может производиться не буква за буквой, а на уровне нескольких
букв
яли слов (Smith a. Spoehr, 1974), так что даже контекст, возникающий в результате
частичного распознавания одной буквы, облегчает распознавание других букв.
Дополнение гипотезы о механизме распознавания образов соображениями относительно
роли контекста значительно укрепляет ее позиции. Мы начинаем понимать, что дает
нам возможность распознавать образы с такой легкостью. Все сказанное до сих
пор позволило нам выявить некоторые черты адекватной теории распознавания образов.
Теперь, после рассмотрения кодирования информации в памяти и процессов сравнения,
мы рассмотрим еще один аспект распознавания — взаимоотношения между этим процессом
и вниманием.
ВНИМАНИЕ
В одной из предыдущих глав было отмечено, что термин — "внимание" имеет несколько
значений. Один из аспектов внимания, называемый обычно "избирательностью", особенно
тесно связан с обсуждаемой здесь темой. Избирательность внимания была уже проиллюстрирована
на примере с шумлей вечеринкой (стр. 25-26): человек способен настраиваться
на восприятие определенных источников информации, выбирать определенные ее каналы
для переработки и "отстраиваться", или отключаться от всех остальных.
ЭКСПЕРИМЕНТЫ СО "СЛЕЖЕНИЕМ"
Избирательность внимания широко изучалась в экспериментах с дихотическим прослушиванием
и слежением. Дихотическим прослушиванием называют эксперименты, в которых испытуемому
предъявляют звук одновременно по двум каналам. Как уже говорилось в гл. 3, под
каналом имеется в виду отдельный источник звуков. В типичном эксперименте "с
дихотическим прослушиванием и слежением испытуемый -слышит одновременно два
сообщения, которые поступают по двум каналам — по одному на каждое ухо — через
наушники. Испытуемого просят слушать одно из сообщений и "следовать за ним по
пятам" (т. е. повторять его слово за словом). Как это ни удивительно, испытуемые
без особого труда следят за одним сообщением, прослушивая два. Они отключаются
от второго сообщения, направляя свое внимание на то, за которым они следят.
Эффекты дихотического прослушивания и слежения усиленно
изучал Черри (Cherry, 1953). Его интересовало, в частности, что происходит
со вторым сообщением, которому испытуемый не уделяет внимания. Хотя
испытуемый и отключался от второго канала, некоторые вещи все-таки доходили до него. Например, испытуемый знал, что второй канал
действует (он
слышал какие-то звуки), и мог сказать, была ли это человеческая речь или
какой-то неречевой звук, вроде жужжания. Испытуемые замечали также, когда
второе сообщение вместо мужского голоса начинал читать женский голос.
Однако они не могли ничего сказать о специфическом содержании читаемого
текста, о том, была ли это подлинная речь или какая-то лишенная смысла
последовательность речевых звуков, на каком языке шло сообщение и
изменялся ли язык в процессе эксперимента. Он не мог узнать ни одного
из услышанных слов даже тогда, когда одно слово повторялось много раз
(Moray, 1959).
Дихотическое прослушивание и слежение — это экспериментальный вариант "феномена вечеринки". Такая процедура служит
полезным методом изучения внимания, поскольку при этом испытуемый, чтобы
выполнить задание, должен избирательно направить свое внимание на один
канал-тот, за которым он следит, и отключиться от другого. Результаты
таких экспериментов привели к созданию нескольких моделей феномена
внимания, так как именно в этих исследованиях был получен ряд важных
данных, требующих объяснения.
В частности, теория внимания должна объяснить,
каким образом человек концентрирует все свое внимание на одном канале,
пренебрегая другими. Она должна объяснить также, что происходит с
информацией, поступающей по этим другим каналам.
МОДЕЛИ ВНИМАНИЯ
Одна из наиболее известных теоретических моделей внимания — это модель фильтра
(Broadbent, 1958), согласно которой избирательное внимание действует подобно
фильтру, пропуская информацию только по одному каналу и блокируя остальные.
Процесс блокирования становится возможным благодаря анализу физических характеристик
сообщений, поступающих по всем каналам; на основе такого анализа определенный
канал может быть затем выделен для приема. Так, например, при дихотическом прослушивании
(рис. 4.4) различение двух сообщений возможно благодаря разному положению в
пространстве их источников (один слева, другой справа). Это различие создает
основу для действия фильтра, который отбирает и пропускает только одно из этих
сообщений, например поступающее слева. Мужской или женский голос может быть
выбран на основе различия в высоте звука. Все это позволяет понять, почему испытуемым
известны некоторые физические характеристики того сообщения, за которым они
не следят: они известны им потому, что физический анализ предшествует отфильтровыванию.
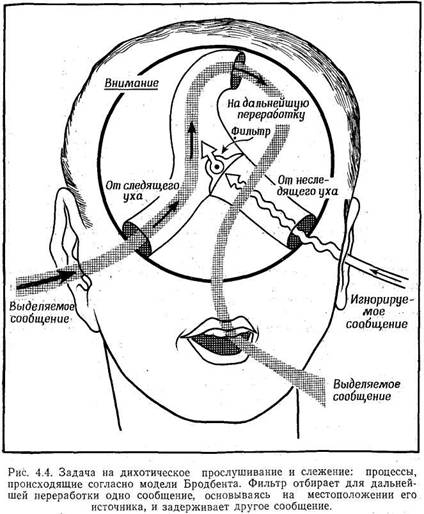
Неадекватность модели Бродбента выявилась в экспериментах, показавших, что
внимание может переключаться с одного канала на другой и обратно в зависимости
от смысла сообщения. Это можно наблюдать, если разорвать входное сообщение и
подавать одну его часть на одно ухо, а другую на другое. Например, можно разорвать
сообщение "мыши едят сыр" и подать первое и третье слова на правое ухо, а слово
"едят" — на левое. Можно одновременно с этим подавать на то и другое ухо части
еще одного разорванного сообщения. Например, подавая на правое ухо слово "мыши",
на левое подают слово "три", затем на левое-"едят", на правое-"пять"; на правое-"сыр",
на левое-"девять"В этих условиях (Gray a. Wedderburn, 1960) иопытуемыеобычно
следят за осмысленной фразой "мыши едят сыр", несмотря на то что она подается
то на правое, то на левое ухо, а не воспроизводят то, что слышат одним ухом,
вроде "мыши: пять сыр". Это свидетельствует о том, что внимание следит неза
физическии знаками входного синала, а зачем другим — за осмысленными последовательностями
слов.
Трисмен (Trisman, 1960) также показала, что при дихотическом прослушивании
испытуемые иногда повторяют слова, следуя за смыслом сообщения независимо от
того, по какому каналу оно передается (рис. 4.5). Например, если испытуемый
следит за сообщением, поступающим на правое ухо, и если вдруг это сообщение
начинают подавать на левое ухо, переключив на правое то, за которым он не следит,
то реакция испытуемого может тоже переключиться на левое ухо. Испытуемый может
продолжать следить за сообщением, когда оно перескакивает с одного уха на другое,
хотя по инструкции он должен непрерывно следить за информацией, поступающей
на правое ухо. Таким образом, при слежении испытуемый руководствуется смыслом,
а не тем, откуда приходят звуки.

Как показывают эти данные, было бы неверно объяснятьфеномен внимания на основе
одних лишь физических особенностей стимула. Учитывая обнаруженное несоответствие,
Трисмен (Trisman, 1969) видоизменила модель Бродбента; по ее мнению, внимание
действует скорее как аттенюаторуменьшает количество информации, проходящей по
невыделяемым каналам, но не отключает их полностью. Трисмен: считает, что все
поступающие извне сигналы подвергаются ряду предварительных испытаний. Сначала
анализируются: общие физические признаки входных сигналов, а затем эти сигналы
подвергаются более тонкому анализу — с точки зрения их содержания. После таких
испытаний внимание может быть направлено на один из каналов. Эти испытания устанавливают,
на чем следует сосредоточить внимание, т. е. выбор канала определяется результатами
предварительного анализа. Таким образом, если я слушаю сообщение относительно
мышей, поступающее по одному каналу, и если это сообщение внезапно переключается
и начинает поступать но другому каналу, то предварительные испытания выявят
это, что даст мне возможность переключить внимание на второй канал, с тем чтобы
продолжать следить за тем же сообщением.
Гипотеза Трисмен о предварительном испытании ведет, однако, к следующему затруднению:
если потребуется достаточно тонкий предварительный анализ, может оказаться,
что мы постулируем выяснение смысла сообщения, которое еще не было выделено
вниманием. Возникает вопрос: можем ли мы распознавать образы (а это мы должны
делать, чтобы определить смысл сообщения) до того, как мы уделили им внимание?
Отношение между распознаванием образов и вниманием ясно сформулировал Норман
(Norman, 1969), использовав идею, высказанную Дейчем и Дейч (Deutsch a. Deutsch,
1963). Согласно модели Нормана, все входные каналы перерабатывающей системы
подвергаются анализу в той или иной степени, достаточной для того, чтобы активировать
определенные следы в долговременной памяти. (В терминах системы "Пандемониум"
мы могли бы сказать, что все стимулы анализируются демонами выделения признаков,
и это побуждает к активности некоторых из соответствующих демонов опознавания).
В этот момент начинает действовать избирательное внимание, соответствующее полному
распознанию образов, на которые оно направлено. (В системе "Пандемониум" это
означало бы, что пробуждаются все те демоны опознавания, которые, вероятно,
могли бы соответствовать входным образам, но распознаются лишь некоторые из
этих образов.) Согласно Норману, распознать образ-это и значит обратить на него
внимание. Важную роль во всем этом играет контекст, ибо то, какие образы распознаются,
зависит от того, какие образы с наибольшей вероятностью могут встретиться в
данной ситуации.
Нейссер (Neisser, 1967) тоже связывает
распознавание образов с вниманием. Согласно его теории, вся входная информация подвергается предварительному анализу на уровне,
предшествующем
вниманию. Окончательное же распознание того или иного стимула может
произойти только тогда, когда внимание обращено на этот стимул. Таким
образом, внимание-это и есть полное распознание.
Теория Нейссера представляет особый интерес: в ней постулируется такой тип
кодирования информации в ДП, какой мы еще не рассматривали. Его идея о коде
ДП вытекает из концепции "анализ путем синтеза" — модели восприятия речи, выдвинутой
Халле и Стивенсом (Halle a. Stevens, 1959, 1964). Эта модель основана на довольно
необычном представлении: предполагается, что распознавание речевого образа по
сути дела равносильно его построению. Концепцию авторов можно резюмировать следующим
образом: 1) в ДП хранится и используется для сравнения с входным стимулом не
копия этого стимула и не признаки, которыми он обладает, а набор правил для
его построения; 2) эти правила используются для синтеза, или построения, внутреннего
образа, который надлежит сравнить со стимулом; 3) важную роль в процессе этого
синтеза играет контекст, так как он используется при отборе небольшой группы
образов для синтеза. Это те образы, которые предположительно вероятнее всего
могут встретиться в данном контексте. Короче говоря, распознавание образов включает
в себя процесс активного воспроизведения стимулов. Это воспроизведение, несомненно,
не носит случайного характера; оно направляется той ситуацией, в которой появился
стимул. При таком направленном построении используется набор правил, хранящихся
в ДП. (Таким образом, согласно этой теории, код ДП использемый при распознавании,
представляет собой набор правил для создания внутренней копии стимула.) Воспроизведенный
или синтезированный таким путем внутренний стимул сопоставляется со стимулом,
поступающим извне, и результаты этого сопоставления определяют распознавание.
Итак, по теории Нейссера, процесс синтеза внутреннего образа — это то же самое,
что и внимание.
ОБЩАЯ МОДЕЛЬ РАСПОЗНАВАНИЯ ОБРАЗОВ
Рассмотрев процесс распознавания образов, мы смогли выявить некоторые из его
основных компонентов. Попытаемся теперь обрисовать эти основные компоненты и
объединить их в общую модель распознавания образов. Что нам потребуется для
такой модели? Прежде всего нужны все компоненты, изображенные на рис. 4.1: первичная
репрезентация, или регистрация, стимула; несколько внутренних (ДП) кодов, с
которыми его можно было бы сравнить; процессы сравнения и принятия решения.
Необходимы также механизмы, реализующие в процессе распознавания образов учет
контекста; эта особенно важно, так как контекст позволяет значительно сократить
число образов, с которыми нужно будет сравнивать стимул. Затем перед нами встанет
вопрос о природе кода ДП, используемого при таком сравнении. У нас нет данных,
которые ясно указывали бы на характер этого кода; поэтому мы не можем выбрать
тот или иной из рассмотренных нами кодов (прототипы, перечни признаков или перечни
правил).
Далее мы включим в нашу модель механизм для предва-рительного анализа стимулов.
Этот анализ должен направляться контекстом. Он мог бы соответствовать предварительной
стандартизации стимула, с помощью которой пытались улучшить наивную эталонную
гипотезу, или же анализу признаков в моделях вроде системы "Пандемониум". И
наконец, займемся самим контекстом. Для того чтобы ввести в модель влияния контекста,
нам понадобится механизм "обратной связи", обеспечивающий информацию о результатах
прежних распознаваний, которую можно было бы использовать при опознании данного
стимула. Кроме того, придадим распознающей системе способность иметь дело одновременно
с несколькими стимулами; это означает, что распознавание речи должно происходить
не на уровне отдельной фонемы, а чтение-не по буквам.
Модель процесса распознавания, которую мы могли бы в результате получить, изображена
на рис. 4.6. Здесь представлена входная информация о стимуле (помните, что это
может быть набор фонем, букв или чего угодно другого), поступающая в сенсорный
регистр. Пока информация находится в этом регистре, она подвергается предварительному
анализу. Отмечаются признаки, которыми обладает стимул, и его представление
может быть приведено к какой-либо стандартной форме (нормализовано). На этот
предварительный анализ влияет информация об общем контексте распознавания, обеспечиваемая
обратной связью от только что завершенных актов распознавания. Затем имеется
набор образовкодов ДП, — с которыми сравнивается представление стимула. Мы не
можем точно указать, являются ли эти образы перечнями признаков, эталонами,
прототипами, создаваемыми с помощью ряда правил, или чем-то еще, однако ясно,
что в эти наборы входят не все хранящиеся в ДП коды. Число кодов, используемых
для сравнения, зависит от имеющейся контекстной информации (вряд ли мы будем,
например, пытаться распознать букву еврейского алфавита при чтении списка английских
слов). Затем эти коды сравниваются с анализируемым стимулом (по всей вероятности,
происходит параллельное сравнение с несколькими кодами одновременно). И наконец,
принимаетсярешение о том, какой код ДП лучше.. всего соответствует данному стимулу,
что и означает распознание образа. Принятое решение по обратной связи поступает
в механизм, реализующий учет контекста, с тем чтобы содержащуюся в нем контекстную
информацию можно было лучше использовать для дальнейших актов распознавания.
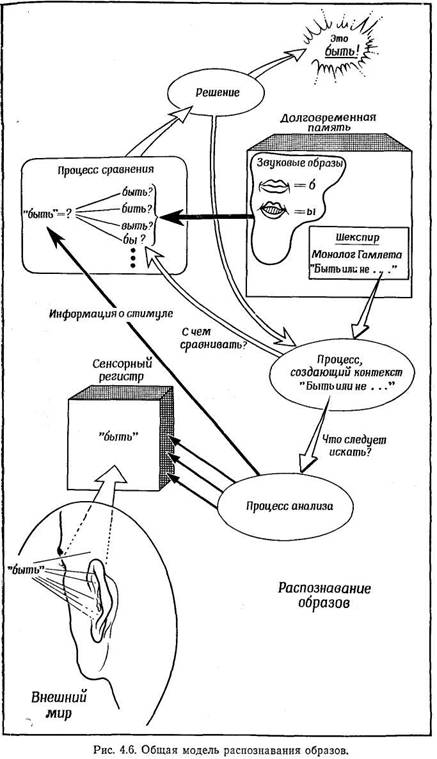
Модель, представленная на рис. 4.6, по-видимому, содержит в себе почти все,
что мы извлекли из нашего обсуждения процесса распознавания образов. Она позволяет
также выявить некоторые недостатки распознающей системы такого типа. Когда эта
система допускает ошибки, то это такие ошибки, которые не являются ни случайными,
ни полностью предсказуемыми на основе сходства признаков. Наша модель распознает
образы не только по тем признакам, которые у них имеются, но и по тем, которые
хорошо вписывались бы в имеющийся контекст. И действительно, человек может иногда
"увидеть" или "услышать" то, чего на самом деле не было, только потому, что
он этого ожидал. Это может привести к так называемому феномену "Я согласен",
когда на собрании человек, провалившийся на выборах, вскакивает с места, чтобы
согласиться занять некий пост, хотя называют имя другого-того, кто был избран
на самом деле!
Эта система может также не распознать того, что есть на самом деле, если этого
нельзя ожидать в данном контексте. И, конечно, она может специфически смешивать
сходные вещи, например зрительные сигналы, которые возникают при предъявлении
букв на очень короткое время. Следовало бы ожидать, что такие ошибки будут особенно
частыми в тех случаях, когда контекстная информация минимальна, как это нередко
бывает в психологических экспериментах. Построенная нами модель распознавания
образов, очевидно, предсказывает ошибки тех типов, которые люди допускают постоянно.
Для системы, моделирующей процесс распознавания образов человеком, это можно
считать совершенно естественным.
Подводя итоги, можно сказать, что
рассмотрение процесса распознавания образов позволило нам осознать ряд
интересных вещей, касающихся не только распознавания внешних стимулов,
ной общей природы человеческой памяти.
Глава 5.
Кратковременная память: хранение и переработка
информации
В предыдущих главах
рассматривалось хранение прекатегориальных кодов памяти (кодов,
предшествующих распознаванию образов), а также механизмы распознавания
соответствующих стимулов — процес-са, в котором участвуют коды,
хранящиеся в долговременной памяти. Мы проследили за тем, как стимул,
поступающий из "реального мира", подвергается сйсорной регистрации,
становится объектом внимания и распознается.)Теперь мы займемся дальнейшей
судьбой этих кодов катеГориальной памяти, огласно общи модели,
описанной в гл. 2, по крайней мере некоторые изних переносятся в
кратковременную память (КП), и в настоящей главе мы рассмотрим роль этой
памяти в системе переработки информации.
Следует помнить, что большая часть исследований КП проводится на вербальном
материале. Поэтому о КП как о хранилище слов известно гораздо больше, чем о
других ее аспектах. В результате всех этих работ создается впечатление, что
слова хранятся в КП в акустической форме, т. е. в форме звуков. В этой главе
и в гл. 6 главное внимание сосредоточено на вербально-акустических аспектах
КП. В гл. 7 проблема будет охвачена несколько шире, с тем чтобы учесть возможность
хранения в КП зрительной и семантической (смысловой) информации.
Важно
также отметить, что при рассмотрении КП мы будем исходить из описанной в
гл. 2 теоретической модели, согласно которой КП и ДП представляют собой
обособленные хранилища памяти. В гл. 2 мы указали по крайней мере на
три группы данных, говорящих в пользу самостоятельности КП, но при этом
отметили, что не все психологи согласны с теорией двойственности памяти. В
дальнейшем изложении мы будем пользоваться понятием "кратковременная память" как общепринятым термином, поскольку концепция кратковременного хранения очень полезна для объяснения
некоторых важных явлений памяти у человека.
Представим себе КП как верстак в
мастерской, где столяр изготовляет шкафчик (рис. 5.1). Все необходимые
материалы аккуратно разложены на полках, тянущихся вдоль стен
мастерской. То, что будет нужно на данном этапе, КП: хранение и
переработка информации инструменты, оструганные доски и тому
подобное-столярберет с полки и кладет на верстак, оставляя на нем достаточно свободного места для работы. Когда на верстаке возникает
беспорядок, столяр может разложить все предметы отдельными кутками или
стопками, что позволит ему поместить на верстаке больше разных материалов.
Если числотаких кучек становится слишком велико, кое-что может начать сваливаться с верстака или же столяр кладет некоторые предметы
обратно на полку.
В чем же заключается аналогия с нашей концепцией двойственной системы? Мы можем
представить себе полки в столярной мастерской как ДП — место хранения большого
количества разных материалов, необходимых для работы. Верстак, разделенный на
рабочее место столяра и хранилище ограниченного объема,-это КП. Когда столяр
собирает предметы в кучки, чтобы на верстаке стало больше свободного места,
он осуществляет процесс, который может происходить и в КП, а именно структурирование.
(Как мы увидим, при запоминании короткого списка элементов структурирование
часто используется для того, чтобы объединить несколько элементов в один, который
в КП занимает место одного элемента.) Предметы, свалившиеся с верстака, соответствуюттем
находившимся в КП элементам, которые были забыты, а перенос предметов с полок
на верстак и с верстака на полку аналогичен переносу информации из ДП в КП и
обратно. Для того чтобы отразить представление о постоянстве следов долговременной
памяти и о том, что при переносе материала в КП он, в сущности, не изымается
из ДП, придется сделать некоторую натяжку и допустить, что на полках имеются
неограниченные запасы каждого данного материала, так что всякий раз, когда набор
каких-то материалов переносится на верстак, на полке остается другой такой же
набор.
Аналогия с верстаком полезна, если ее не слишком углублять. Она позволяет представить
себе кратковременную память как легко реорганизуемый отдел памяти, где можно
хранить разнообразные вещи и где можно с ними работать. Кроме того, как мы видим,
между местом для работы и местом для хранения происходит "обмен", так что с
расширением одного уменьшается другое. Однако сложность КП неограничивается
раскладыванием содержимого по кучкам или по полкам.
ПОВТОРЕНИЕ
Один из связанных с КП процессов — это повторение, т. е. многократное пропускание
информации через хранилище памяти. Как мы уже говорили, предполагается, что
повторение несет в основном две функции: освежает хранящуюся в КП информацию,
чтобы предотвратить ее забывание, и переводит информацию о повторяемых элементах
в ДП, повышая тем самым прочность долговременных следов. (Вопрос о том, в чем
именно состоит прочность следов ДП, обсуждается в последующих главах.) Таким
образом, повторение можно рассматривать как одну из "рабочих" функций КП: это
работа, существенная и для освежения информации, и для ее переноса в ДП. Однако
пока еще не ясно, каким образом повторение выполняет эти функции, как оно действует
и что именно повторяется.
ПОВТОРЕНИЕ КАК ВНУТРЕННЯЯ РЕЧЬ
Процесс повторения можно представить себе как своего рода речь — внутреннюю,
или беззвучную. Подобное представление подтверждается наблюдениями Сперлинга
(Sperling, 1967), который заметил, что испытуемый, записывая буквы в задачах
на непосредственное вспоминание, часто произносит их про себя. По мнению Сперлинга,
в этом, возможно, проявляется природа более общего процесса, происходящего в
К.П, — процесса повторения. Он полагает, что при повторении элемента испытуемый
произносит его про себя, слышит, что он говорит, а затем помещает
на хранение в КП то, что он услышал, тем самым восстанавливая первоначальную
прочность следа. Первый этап, т. е. произнесение "про себя", — это так называемая
"внутренняя", или "беззвучная", речь. Подлинные звуки при этом могут отсутствовать,
но при повторении вместо них используются мысленные образы звуков,
которые не произносятся.
Концепция повторения как внутренней речи
подтверждается рядом различных данных. Одна группа данных связана с
оценками скорости, с которой происходит повторение. Испытуемого просят,
например, повторить про себя ряд букв 10 раз и отмечают затраченное на это
время; отсюда можно определить скорость повторения и выразить ее числом букв
в секунду. Если сравнить полученную таким образом скорость со скоростью
внешней, звуковой, речи, то окажется, что они примерно одинаковы, составляя
обычно от 3 до 6 букв в секунду (Landauer, 1962). Таким образом,
повторение и речь сходны в том отношении, что на них затрачивается примерно
одинаковое время.
Мы уже упоминали о других данных, указывающих на то, что повторение представляет
собой внутреннюю речь; это данные об акустических ошибках, наблюдаемых в экспериментах
на непосредственное припоминание (Conrad, 1963; Sperling, 1960; Wickelgren,
1966).Чаще всего в КП может происходить смешение элементов, сходных по звучанию,
независимо от их зрительного или смыслового сходства. По мнению Сперлинга и
Спилмена (Sperling a. Speelman, 1970), такие ошибки обусловлены тем, что элементы,
хранящиеся в КП, представлены в акустической форме и при их забывании может
происходить выпадение одной фонемы (отдельного звука) за другой. Во время припоминания
испытуемый пытается восстановить частично забытые элементы по тем звукам, которые
еще сохранились. Таким образом, когда он делает ошибку, в его ответе будут содержаться
звуки, имевшиеся и в предъявленном элементе; с этим и связан акустический характер
ошибок. Согласно этой модели, повторение представляет собой внутреннюю речь,
которая приводит к повторному поступлению звуков в КП в той же форме, в какой
они были здесь первоначально закодированы. Эту модель с известным успехом использовали
для предсказания результатов в некоторых задачах на непосредственное припоминание.
Хотя представление о повторении как о внутренней речи хорошо соответствует
концепции о слуховом кодировании в КП, этого еще недостаточно. Если повторение
— это мысленное предъявление человеком самому себе какого-то элемента (например,
мысленное произнесение буквы), то повторение может быть также и зрительным.
Например, очень легко зрительно представить себе буквы алфавита. Чтобы убедиться
в этом, пройдитесь мысленно по всему алфавиту и подумайте, есть ли в каждой
из его букв вертикальная линия или нет (в А ее нет, в Б есть, и т. д.). Это
воспроизведение зрительных образов, которое мы в дальнейшем обсудим более подробно,
представляет собой своего рода повторение (в соответствии с приведенным выше
определением). Оценки его скорости (сколько, например, нужно времени, чтобы
мысленно пробежать глазами по всему алфавиту?) показывают, что оно занимает
больше времени, чем слуховое повторение, которое мы назвали внутренней речью
(Weber a. Castleman, 1970). Не означает ли наша способность к воспроизведению
зрительных образов, что повторение иногда может принимать форму "внутреннего
видения"?
ПОВТОРЕНИЕ И ПЕРЕНОС В ДП
Повторение, осуществляемое, видимо, с помощью внутренней речи, не только поддерживает
и оживляет следы в КП: предполагается, что оно обусловливает также перенос информации
в ДП, увеличивая тем самым прочность долговременных следов.
Так ли это в действительности? Одну из попыток ответить на этот вопрос предпринял
Рандус (Rundus, 1971; Rundus a. Atkinson, 1970), который просил своих испытуемых
производить повторение вслух. В одном из его типичных экспериментов со свободным
припоминанием испытуемому предъявляли список слов со скоростью одно слово в
5 с. Испытуемый должен был заучивать этот список, повторяя некоторые слова вслух
во время 5-секундных промежутков между словами. Его не просили произносить какие-то
определенные слова: он мог выбирать слова по своему усмотрению. Набор слов,
которые испытуемый повторял в течение данного 5-секундного интервала, называли
"повторяемым набором" для данного интервала (рис. 5.2, А). Рандус хотел выяснить
зависимость между составом повторяемых наборов и эффективностью запоминания,
которую проверяли после предъявления списка. Как и следовало ожидать, он обнаружил
весьма сильную зависимость (рис. 5.2, Б): чем чаще повторяется вслух данное
слово и чем больше число повторяемых наборов, в которых оно фигурирует, тем
выше вероятность его запоминания.
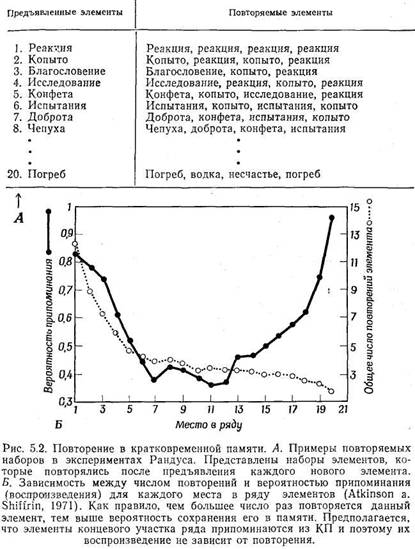
Рандус обнаружил также, что на выбор слов, которые испытуемые повторяли, влияло
прежнее знакомство с этими словами. В частности, вероятность того, что вновь
предъявленное слово будет включено в повторяемый набор, была выше для тех слов,
которые по своему смыслу подходят к остальным словам набора. Такое слово, как
"воробей", по всей вероятности, будет включено в набор, уже содержащий слова
"дрозд, канарейка, крапивник", но вряд ля будет повторяться, если этот набор
содержит слова "хлеб, яйца, сыр". Таким образом, полученные Рандусом результаты
позволяют считать, что повторение действительно повышает прочность определенных
следов в ДП (об этом говорит прямая зависимость между числом повторений и эффективностью
запоминания) и что организующие процессы используют информацию ДП, чтобы определить,
какие из имеющихся в КП элементов следует повторять. Вообще использование ДП
для того, чтобы связать усвоенную в прошлом информацию с информацией, перерабатываемой
в данный момент, называется опосредованием. Таким образом, результаты Рандуса
показывают, что повторение связано с опосредованием.
Эксперименты Рандуса подверглись критике ввиду того, что они были по существу
корреляционными — число повторений регулировалось испытуемым, а не экспериментатором.
Хотя в них и выявляется зависимость между числом повторений и припоминанием,
причинно-следственные отношения остаются неясными: нельзя считать доказанным,
что припоминание определяется повторениями. Возможно, что испытуемые повторяют
именно те элементы, которые легче вспоминаются и которые они в любом случае
припомнили бы и позднее, так что повторение не служит причиной лучшего
запоминания.
Возможность такого истолкования данных Рандуса сама по себе отнюдь не говорит
против того, что повторение повышает эффективность запоминания. Есть, однако,
другие данные, противоречащие представлению о том, что повторение непременно
ведет к переносу информации в ДП. Было, например, показано, что число повторений
данного элемента не всегда оказывает влияние на последующее вспоминание (Craik
a. Watkins, 1973; Woodward, 1973). Крейк и Уоткинс заставляли испытуемых удерживать
в КП отдельные слова в течение различных периодов времени. В одном эксперименте
они с этой целью просили испытуемого сообщать последнее слово, начинавшееся
на заданную букву, в ряду из 21 слова. Допустим, например, что задана буква
С и что ряд начинается словами ДОЧЬ, МАСЛО, РУЖЬЕ, САД, СЛОН, ШКАФ, ФУТБОЛ,
ЯКОРЬ, СТОЛ... Прослушивая этот ряд, испытуемый должен удерживать в памяти слово
"сад", пока не появится "слон", а затем — слово "слон", пока не появится "стол",
и так далее — до тех пор, пока не будет предъявлено последнее из слов, начинающихся
с буквы "С", которое он и должен произнести после прочтения списка. В результате
в КП испытуемого отдельные слова удерживаются на протяжении различного времени:
"сад" гораздо более короткое время, чем, например, "слон". После проведения
опытов с 27 такими списками Крэйк и Уоткинс неожиданно попросили испытуемого
припомнить все слова, какие он только может, из всех списков. Оказалось, что
время, в течение которого слово, начинающееся с заданной буквы, удерживается
в памяти (это время определялось числом последующих слов, начинавшихся с других
букв), не влияло на припоминание при неожиданной проверке. Таким образом, длительность
удержания данного слова в КП, по-видимому, не оказывала влияния на прочность
его следа в долговременной памяти.
В другом эксперименте Крэйк и Уоткинс установили, что время удержания данного
элемента в КП, измеряемое числом повторений вслух, также не влияет на припоминание.
Они предлагали испытуемым несколько списков слов для свободного вспоминания.
Некоторые списки надо было припоминать непосредственно после предъявления, другие
— спустя 20 с после предъявления последнего слова (вариант с отсроченным воспроизведением).
Испытуемым объясняли, что они должны, сосредоточиться на припоминании
последних четырех слов каждого списка, и просили производить повторение вслух,
если они ощущали потребность в этом. Экспериментаторы регистрировали число повторений
по каждому слову. Не удивительно, что последние четыре слова повторялись гораздо
большее число раз при отсроченном, чем при непосредственном воспроизведении.
После опытов с несколькими списками испытуемым неожиданно устраивали проверку
по всем тем спискам, которые им предъявлялись. И теперь уже не оказывалось никаких
различий между словами (из числа последних четырех), содержавшимися ранее в
списках для непосредственного и для отсроченного воспроизведения. Таким образом,
число повторений вслух, которое было гораздо выше для четырех последних слов
в списках для отсроченного воспроизведения, не влияло на прочность запоминания.
Такого рода эксперименты заставляют относиться с недоверием к любому простому
объяснению роли повторения в долговременном запоминании. По-видимому, иногда
повторение в этом смысле эффективно. Однако авторы (Craik а. Watkins, 1973;
Woodward а. о., 1973) полагают, что простое механическое повторение элемента
с целью удержать его в КП не ведет к закреплению долговременного следа. Повторение,
действительно способствующее прочному запоминанию,это, вероятно, очень сложный
процесс, при котором повторяемые элементы, кроме того, опосредуются, ассоциируются
друг с другом и обогащаются в результате контакта с информацией, содержащейся
в ДП. Как показали эксперименты Рандуса, испытуемые в самом деле используют
хранящуюся в ДП информацию при создании повторяемых наборов; поэтому вполне
возможно, что чисто "механическое" повторение происходит сравнительно редко.
Более вероятно, что испытуемые перерабатывают и усложняют повторяемый материал,
не замечая этого, и в результате обычно оказывается, что повторение повышает
эффективность запоминания.
СТРУКТУРИРОВАНИЕ И ЕМКОСТЬ КРАТКОВРЕМЕННОЙ ПАМЯТИ
Как видно из предшествующего обсуждения, название "рабочая память" очень подходит
для КП. По-видимому, даже повторение в ней удерживаемого материала, которое
прежде рассматривали как относительно пассивный процесс, может быть связано
с довольно сложной "работой", в частности с опосредованием и переработкой предъявленной
информации. Аналогичная активность происходит при "струк"турировании", т. е.
такой группировке материала, при которой он будет занимать как можно меньше
места в КП — хранилище с ограниченной емкостью. В сущности структурирование
материала и его повторение с переработкой, видимо, представляют собой две стороны
одной медали: опосредование и переработка информации приводят к тому, что она
занимает в КП минимум места, и вместе с тем эти же процессы приводят к повышению
прочности следов в долговременной памяти. Более подробное рассмотрение процесса
структурирования и его связи с емкостью КП позволит понять все это яснее.
СТРУКТУРИРОВАНИЕ И ЕМКОСТЬ КП
Мы уже отметили один из основных фактов, касающихся КП: ее емкость ограничена;
количество информации, которое может храниться в ней одновременно, не должно
превышать известного предела. Данные об этом получены главным образом при определении
объема непосредственной памяти, когда испытуемому сначала предъявляют короткий
список элементов (например, РАБОТА, МЫШЬ, ПАДЕНИЕ, СОЛЬ, .ДИСК, ПЛАТЬЕ, КНИГА),
а затем просят припомнить их. При малом числе элементов выполнение этой задачи
не со-ставляет труда и испытуемый точно воспроизводит список. Но если число
их превышает 7, большинство испытуемых начинает допускать ошибки. Число элементов,
которые испытуемый может припомнить, не делая ошибок, называют объ-емом памяти,
я его истолковывали как предельное количество информации, которое может вместить
КП. Предполагается, что КП может одновременно удерживать около семи элементов,
поэтому именно такое число их испытуемый может воспроизводить без ошибок. При
большем числе предъявленных элементов некоторые из них не могут удерживаться
в КП и испытуемый не сможет их припомнить, что приведет к ошибкам.
Объем непосредственной памяти модно определить как раввый.лримерно семи словам;
но он равен также семи буквам (если эти буквы не образуют слов) или семи бессмысленным
слогам. Иначе говоря, объем памяти выражается не в каких-то определенных единицах-словах,
буквах или слогах, а равен примерно семи любым предъявленным элементам. Таким
образом, испытуемый может запомнить 7 букв, если они не складываются ни в .какие
определенные структуры (X, П, А. Ф, М, К, И), но способен запомнить гораздо
больше букв, если они образуют 7 слов. Это происходит потому, что он может перекодировать
последовательность из многих букв в ряд более крупных единиц, если эта последовательность
образует осмысленные слова. Такое перекодирование — объединение отдельных стимулов
(букв) в более крупные единицы (слова) — называют структурированием
(chunking). Соответственно образующиеся при этом единицы называют структурными
единицами (chunks). Этот термин был введен Миллером (Miller, 1956), которому
принадлежит также ставшая ныне знаменитой фраза о том, что объем памяти, измеренный
в структурных единицах, равен "Магическому Числу Семь плюс или минус два".
Миллер обсуждал
некоторые другие объемы, соответствующие этому "магическому"
диапазону чисел от 5 до 9, однако в связи с нашей темой особенно
существенны его представления о КП: объем кратковременной памяти
измеряется в единицах, которые могут очень широко варьировать по своей
внутренней структуре. Единица емкости КП соответствует одной структурной
единице, а структурная единица вещь довольно изменчивая, она содержит в
зависимости от обстоятельств различное количество информации.
Одно из затруднений, связанных с концепцией структурной единицы, заключается
в том, что его определение вводит нас в замкнутый круг: с одной стороны, мы
определяем структурные единицы как элементы, которых в КП может находиться около
семи, а с другой стороны — утверждаем, что объем КП соответствует семи структурным
единицам. Иными словами, объем КП равен семи таким единицам, которых в ней помещается
семь штук. Смысла в этом мало, и нужно, очевидно, найти способ определить структурную
единицу как-то иначе. Конечно, довольно часто есть возможность определить характер
структурной единицы по-другому. Допустим, что мы предъявляем испытуемому в виде
последовательного ряда буквы, образующие несколько трехбуквенных слов (например,
К, О, Т, Б, О, Р, В, А, Л). При этом может оказаться, что испытуемый способен
запомнить примерно 21 букву (составляющие 7 слов) и воспроизвести их в пробе
на непосредственное припоминание. В таком случае одна структурная единица соответствует
одному слову, если принять, что одна единица — это такой элемент, которых испытуемый
может запомнить семь. Однако, поскольку нам известны слова, одна структурная
единица соответствует также одному слову. Иначе говоря, мы могли бы заранее
предсказать, что испытуемый сможет запомнить 21 букву (а не 7), потому что в
данном случае структурной единицей является слово. Таким образом, два способа
определения структурной единицы — на основе объема памяти и на основе наших
представлений о том, что соответствует единице, — согласуются между собой.
Имеется и другое подтверждение концепции структурной
единицы: если варьировать то, что мы интуитивно можем рассматривать как
структурную единицу, объем памяти будет оставаться постоянным,
соответствуя примерно семи таким единицам. Одну из проверок этой концепции
предпринял Саймон (Simon, 1974), используя в качестве испытуемого
самого себя. Он нашел, что количество материала, которое
он мог непосредственно припомнить без ошибок, составляло примерно 7
односложных слов, примерно 7 двусложных и 6 трехсложных. Пока все это хорошо
согласуется с концепцией структурирования. Объем памяти сохраняется на
уровне семи единиц, несмотря на вариации. Однако Саймон мог припомнить всего лишь четыре осмысленных сочетания из двух
слов (таких, как
МЛЕЧНЫЙ ПУТЬ, ДИФФЕРЕНЦИАЛЬНОЕ ИСЧИСЛЕНИЕ или УГОЛОВНЫЙ КОДЕКС) и всего
три более длинные фразы (такие, как В НЕКОТОРОМ ЦАРСТВЕ, В НЕКОТОРОМ
ГОСУДАРСТВЕ или НИЧТО НЕ ВЕЧНО ПОД ЛУНОЙ). Он пришел к выводу, что утверждение
о постоянстве объема КП, равного примерно семи единицам, в общем
справедливо Однако это далеко не точное утверждение, поскольку с
увеличением размеров того, что мы принимаем за структурную единицу, емкость
КП, измеряемая в этих единицах, уменьшается. А согласно определению структурной единицы эта емкость должна оставаться постоянной.
Как отмечает
Саймон, основная проблема, связанная с определением структурной единицы,
состоит в том, что эта единица используется для измерения объема
непосредственной памяти, но вместе с тем это понятие, выведенное из результатов задач на непосредственное припоминание. Если бы удалось найти
другую ситуацию, в которой структурные единицы играли бы какую-то роль, то
эту другую ситуацию можно было бы использовать для независимого описания
структурной единицы. Если бы затем можно было использовать это
описание для оценки роли структурной единицы в задачах на
непосредственное припоминание, то концепция структурной единицы приобрела
бы больший смысл.
Рассмотрим рассуждения Саймона более подробно. Прежде всего мы отмечаем, что
объем КП считается равным семи структурным единицам, а это означает, что число
слогов, которые могут воспроизводиться в задачах на непосредственное припоминание,
примерно равно числу слогов в одной структурной единице, умноженному на семь.
(Если, например, структурная единица-двусложное слово, то мы можем вспомнить
7х2, т. е. 14 слогов.) Таким образом, можно сказать, что число слогов на одну
структурную единицу (обозначим его S) равно в среднем 1/7 числа припоминаемых
слогов (обозначим его R), или S=1/7 R. Это позволяет нам оценивать величину
структурной единицы (S) для любого данного стимульного материала по воспроизведению
этого материала (R). Однако одного этого уравнения недостаточно, чтобы подтвердить
или опровергнуть гипотезу о том, что КП вмещает 7 структурных единиц, ибо мы
всегда можем подо КП: хранение и переработка, информации брать какую-либо оценку
величины структурной единицы, которая будет идеально соответствовать этому уравпению.
Итак, необходимо найти что-то иное, отличное от задачи на
объем КП, где бы структурные единицы играли известную роль, и Саймон
предложил использовать для этого механическое заучивание. Он высказал
мысль, что время, необходимое для заучивания списка слогов, возможно,
зависит от того, в какой мере эти слоги объединяются в структурные
единицы. Например, число слогов, которые можно заучить за данное время,
зависит от того, в какой мере эти слоги объединяются в слова. Можно
ожидать, что чем легче объединить заданные слоги в структурные единицы,
тем быстрее их можно заучить. Это касается вообще всякого механического заучивания,
например запоминания последовательностей элементов или
парных ассоциаций.
Сформулируем эту "гипотезу заучивания — структурирования" следующим образом:
F=kS, где S — величина структурной единицы (как и прежде, в слогах), a F — число
слогов,
которое можно заучить за данное время, например за одну минуту. Как видно из
этого уравнения, для любого заданного материала число слогов, которое можно
заучить за одну минуту, пропорционально числу слогов в одной структурной единице,
причем коэффлциентом пропорциональности служит некоторая неизвестная постоянная
k, аналогичная числу 7 d"семи структурных единицах". Исключив из наших двух
соотношений — S=1/7 R и S=1/k F — величину структурной единицы S, получим 1/7
R= 1l/k F. Это уравнение справедливо применительно к любому материалу (например,
к двусложным словам). Кроме того, для любого материала мы можем фактически измерить
R — число слогов, которые могут быть тотчас же верно повторены испытуемым, и
F — число слогов, заучиваемых за одну минуту (для этого достаточно разделить
общее число заученных слогов на время, потраченное на их запоминание). Можно
проделать это для материала двух разных типов, например для двусложных слов
(тип 1) и бессмысленных слогов (тип 2). Тогда 1/7 R1 =1/7 F1
и 1/7 R2 =1/7 F2, где подстрочные индексы указывают тип
материала. Разделив эти выражения друг на друга, получим R1/R2=
F1/F2 При этом неизвестная величина k исключается, и окончательное
соотношение не зависит даже от допущения, что объем КП равен семи структурным
единицам.
Итак, равенство R1/R2= F1/F2 дает
возможность проверить состоятельность концепции структурной единицы. Предполагается,
что структурирование играет роль при выполнении двух различных задач (на механическое
заучивание и на непосредственное припоминание), и можно ожидать, что соотношения
результатов, полученных в экспериментах с этими двумя задачами и с использованием
любых двух наборов материала (R1/R2 и F1/F2),
будут равны. Саймон проверил это предположение и установил, что в известных
пределах оба соотношения действительно равны. Таким образом, концепция структурирования
получила некоторое подтверждение, и представляется разумным считать, что объем
КП в самом деле равен примерно семи структурным единицам.
Теперь у нас есть достаточно оснований полагать, что испытуемые могут увеличить
количество информации, которую они способны одновременно удерживать в КП, путем
перекодирования этой информации в структурные единицы. Конечно, такое увеличение
объема памяти окажется полезным лишь в том случае, если испытуемый сможет затем
декодировать структурную единицу и восстановить ее компоненты. Например, испытуемый,
которому предъявили ряд из четырех букв "С, М, Л, Т" в задаче на непосредственное
припоминание, может перекодировать его в однословную структурную единицу "Самолет".
Позднее, во время припоминания, он может допустить ошибку и воспроизвести, например,
"С, А, Л, Т". В данном случае структурирование не помогло ему вспомнить все
буквы. Но, как правило, структурирование помогает нам увеличить ограниченную
емкость КП.
ПРОЦЕСС СТРУКТУРИРОВАНИЯ
Как мы убедились, КП — не склад, куда помещают разные вещи и где их просто
хранят без разбора, а система, в которой информация может подвергаться различным
воздействиям и храниться в разнообразных формах. Очевидно, что при структурировании
материала в КП используется информация, хранящаяся в ДП, — например, сведения
о правильном написании слов. Информация из ДП позволяет придать некоторую структуру
набору внешне не связанных между собой элементов; без этого образование структурных
единиц было бы невозможно. Таким образом, структурирование, подобно повторению,
связано с опосредованием.
Исходя из такой характеристики
процесса структурирования, можно представить себе, какие условия для него
требуются. Во-первых, структурирование обычно происходит в то время,
когда информация поступает в КП, а это означает, что объединяемый материал
должен поступать в КП более или менее одновременно (было бы трудно
объединить три буквы в слово, если бы эти буквы были случайно разбросаны в ряду из 21 буквы). Во-вторых, структурирование должно
облегчаться, если объединяемые элементы обладают каким-то внутренним сродством, позволяющим им
образовать некую единицу. В частности, если группа стимулов имеет
структуру, соответствующую какому-то коду в ДП, то можно ожидать, что
эти стимулы сложатся в структурную единицу, соответствующую этому коду.
Боуэр (Bower, 1970, 1972 a; Bower a. Springston, 1970) изучал некоторые из
этих аспектов структурирования, видоизменяя способы сочетания предъявляемых
элементов и степень их соответствия информации, хранящейся в ДП. В некоторых
работах он варьировал группировку букв в буквенных последовательностях. Одним
из способов такой группировки было временное разделение. Испытуемые выполняли
задачу на определение объема памяти при слуховом восприятии букв. Экспериментатор,
называя буквы, разделял их короткими паузами, положение и длительность которых
он варьировал. Например, он мог читать ряд букв следующим образом: УФО... ОНФР...
ГФ... НРЮ. Испытуемые, прослушавшие такую последовательность, запоминали меньше
букв, чем те, которым предъявляли те же буквы, но иначе: УФ... ООН...ФРГ...ФНРЮ,
хотя число букв, а также число групп из двух, трех и четырех букв было в обоих
случаях одинаковым. Боуэр получил примерно такие же результаты при зрительном
предъявлении букв с выделением групп цветом (в приведенных ниже рядах заглавные
и строчные буквы были разного цвета):
УФОонфрГФнрю или УФоонФРГфнрю
Как показывают эксперименты Боуэра, здакомые сочетания букв, такие, как акронимы
(буквенные сокращения), могут служить основой для структурирования, особенно
в тех случаях, когда легко заметить соответствие входных сигналов этим сочетаниям.
Структурные единицы могут возникать и при предъявлении более сложного материала,
чем списки букв, хотя принципы структурирования остаются теми же. Это иллюстрируют
эксперименты с дословным воспроизведением списков слов, различающихся по "порядку
приближения" к осмысленному английскому тексту. Концепция "порядка приближения",
развитая Миллером и Селфриджем (Miller a. Selfridge, 1950), касается определенного
свойства ряда слов, которое характеризует степень его сходства с текстом на
английском языке. Наименьшее сходство имеет место в случае приближения нулевого
порядка-это просто список взятых наугад английских слов. Приближение первого
порядка сходно с нулевым; оно отличается лишь тем, что слова взяты из какого-то
текста. Поэтому частота, с которой различные слова встречаются в списках первого
порядка, отражает частоту их использования в языке. Списки второго порядка создаются
при участии испытуемых. Сначала одному испытуемому называют какое-нибудь обычное
слово, например THE, и просят его использовать это слово в каком-нибудь предложении.
Испытуемый может, скажем, произнести фразу "The sky is falling". Затем
слово, которое следует в этой фразе за словом the (SKY), предлагают другому
испытуемому, который использует это второе слово в каком-нибудь предложении,
например "In the sky are birds". Слово, следующее в этой фразе за
предъявленным второму испытуемому словом, т. е. ARE, предлагают третьему, и
так далее до тех пор, пока не получится достаточно длинный список слов
("sky are..."). Для приближений третьего и более высоких порядков
используется та же процедура, с той разницей, что каждому испытуемому называют
по два и более следующих друг за другом слов, которые они используют для построения
фраз. С повышением порядка приближения количество контекста, имеющегося в момент
добавления к списку нового слова, возрастает и этот список становится все больше
похожим на английскую прозу. Наивысшее сходство достигается при приближении
седьмого порядка, а затем следует настоящий текст. Приведем несколько стримеров.
Приближение первого порядка: "abilites with than beside I for waltz you the
sewing "; 4-го порядка: "saw the football game will end at midnight on
January"; 7-го порядка: "recognize her abilities in music after he scolded
him before" (Miller a. Selfridge, 1950).
Ряды слов, сходство которых с английскими предложениями можно измерить, полезны
при изучении процесса структурирования. Миллер и Селфридж (Miller a. Selfridge,
1950) обнаружили, что непосредственное воспроизведение списка слов улучшалось
по мере приближения его к английскому тексту. Наиболее ярко такая зависимость
проявлялась в диапазоне от нулевого до примерно третьего порядка. Испытуемые,
видимо, использовали свое знание английского языка для облегчения непосредственного
припоминания, а это означает, что они прибегали к какому-то процессу опосредования,
возможно — к структурированию.
В пользу
того, что при этом действительно использовалось структурирование, говорит
эксперимент, проведенный Тульвингом и Пэтко (Tulving a. Patkau, 1962), Они
создавали списки из 24 слов, варьировавшие по степени приближения к
английскому тексту. Затем они предъявляли эти списки испытуемым для
непосредственного припоминания. Изучая ответы испытуемых, Тульвинг и Пэтко
определили единицу, названную ими "заимствованной структурной
единицей". Это такая группировка элементов на выходе (в словах, воспроизводимых
испытуемым), которая соответствует какой-то последовательности на входе (в
предъявленном списке). Так, например, если бы в списке была
последовательность "saw the football game will end at midnight on
January", а в ответе испытуемого — "the football game saw at midnight will end",
то считалось бы, что он использовал следующие заимствованные
структурные единицы: 1) "the football game", 2) "saw", 3) "at midnight"и 4)
"will end". Такие единицы называли "структурными" потому, что в каждой
из них при вспоминании элементы группировались в таком же порядке, как и
в предъявленном списке, а это позволяло думать, что слова, входившие в
состав каждой заимствованной структурной единицы, группировались
(структурировались) испытуемым во время предъявления.
В результатах, полученных Тульвингом и Пэтко (Tulving a. Patkau, 1962), содержатся
интересные указания на использование процесса структурирования при запоминании
списков слов. Во-первых, так же как в экспериментах Миллера и Селфриджа, число
припоминаемых слов находилось в прямой зависимости от порядка приближения к
английскому тексту. Во-вторых, оказалось, что испытуемые неизменно вспоминали
по 5 — 6 заимствованных структурных единиц независимо от порядка приближения.
Улучшение результатов (увеличение числа припоминаемых слов) по мере приближения
к тексту было обусловлено не тем, что испытуемый вспоминал больше структурных
единиц, а тем, что структурная единица содержала в среднем больше слов. Иначе
говоря, создавалось впечатление, что чем больше структура списка приближалась
к английскому синтаксису, тем более крупные структурные единицы мог создавать
и впоследствии припоминать испытуемый. А поскольку он всегда припоминал примерно
одинаковое число структурных единиц (число, соответствующее объему памяти),
его способность создавать более крупные структурные единицы позволяла ему вспоминать
больше слов. Короче говоря, какие-то особенности структуры английского языка,
по-видимому, способствуют образованию крупных структурных единиц.
Какой именно фактор, присущий английским предложениям, приводит к увеличению
размеров структурной единицы, неясно. Возможно, что структурирование основано
на правилах синтаксиса, которые .определяют, как должны сочетаться слова в предложениях.
Например, одно из правил синтаксиса гласит, что предложение должно содержать
именную фразу (подлежащее), за которой следует глагольная фраза (сказуемое).
Например, предложение "The boy ran" правильное с точки зрения английской грамматики,
a "Ran the boy" — неправильное. Все, кто владеет английским языком, усваивают
правила синтаксиса, и возможно, что именно знание этих правил приводит к структурированию
английского текста. Чем больше списки слов приближаются к английскому тексту,
тем лучше они соответствуют синтаксису английского языка; благодаря этому, может
быть, и облегчается структурирование.
Данные в пользу того, что правила синтаксиса приводят к
структурированию, получены, в частности, в экспериментах Джонсона (Johnson,
1968), в которых испытуемые обучались произносить целые предложения в ответ
на числовые стимулы. При этом использовался метод парных ассоциаций. Например, испытуемый
должен был произносить фразу "The tall boy saved the dying woman' в ответ на стимул "Семь".
Особенно большой интерес представляют ошибки, которые делал испытуемый, когда
он припоминал только часть предложения. Джонсон исходил из того, что при заучивании
предложений испытуемые, вероятно, должны перекодировать, или структурировать,
слова в единицы более высокого порядка. Например, в результате структурирования
ряда слов "the" + прилагательное + существительное можно получить именную
фразу. В пределах каждой единицы слова, очевидно, больше зависят друг от
друга, чем от слов любой другой единицы. А это позволяет предсказать, что припоминание
одного слова, входящего в состав данной единицы, будет гораздо теснее связано
с припоминанием других входящих в нее слов, чем с припоминанием слов из какой-нибудь
другой единицы. В частности, вероятность вспоминания двух соседних слов будет
различной в зависимости от того, входят ли они в одну или в две разные единицы.
Для проверки этой гипотезы
Джонсон вычислил вероятность "ошибки перехода" (ВОП). ВОП
определяется как процент случаев, когда какое-либо слово из данного предложения вспоминалось неверно,
тогда как предшествующее слово
воспроизводилось верно. Например, в предложении "The tall boy saved the
dying woman" ВОП между "TALL" и "BOY" определяет, в каком проценте случаев
испытуемые вместо "BOY" называли какое-либо другое слово, верно припомнив
слово "TALL". Следует ожидать, что ВОП будет низкой для тесно связанных
между собой слов, так как испытуемый, верно припомнив одно слово, скорее
всего так же верно назовет и тесно связанное с ним последующее слово. В
соответствии с гипотезой о том, что испытуемые заучивают предложения по
отдельным структурным единицам, можно предсказать, что для двух соседних
слов ВОП будет выше, если эти слова относятся к разным структурным единицам,
и ниже, если к одной и той же единице. Это следует нз предположения, что
высокая ВОП
между словами означает отсутствие между ними тесной связи.
Поскольку ВОП служит мерой связи между двумя соседними словами (причем тесная
связь соответствует низкой ВОП), мы имеем возможность проверить гипотезу о том,
что при структурировании используются правила синтаксиса. Если бы это подтвердилось,
мы могли бы предсказать, что ВОП должна быть высокой между синтаксическими
единицами например, между подлежащим и сказуемым) и низкой внутри отдельной
единицы. Именно это и обнаружил Джонсон (рис. 5.3). В предложении "The tall
boy saved the dying woman" ВОП оказалась высокой между 3-м и 4-м словами, и
именно здесь, между этими словами, по правилам синтаксиса проходит главный раздел
между частями предложения. А в таких предложениях, как " The house across the
street burned down", основные разделы — и в то же время наиболее высокие значения
ВОП — соответствуют границам между словами "house" и "across" и между "street"
и "burned". Даже в пределах отдельной фразы (например, во фразе "saved the dying
woman") величины ВОП отражают внутреннюю структуру, определяемую правилами синтаксиса.
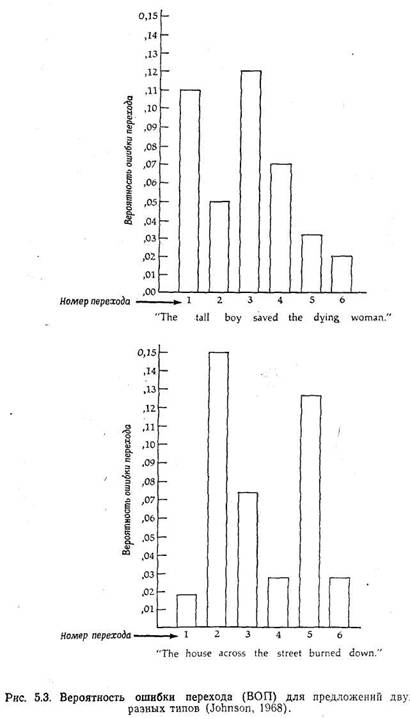
Результаты, полученные при определении ВОП, явно подтверждают идею о том, что
в. основе структурирования, лежат "правила синтаксиса; есть, однако, и другая
возможность, которую также следует рассмотреть. Структурирование может быть
основано не на порядке слов, а на смысле: слова, объединенные в соответствии
с правилами английского синтаксиса, образуют также более осмысленные фразы,
чем слова, расположенные в случайном порядке. Возможно, что именно .смысловой
(семантический) фактор, а не правила синтаксиса, т. е. определенный порядок
слов, облегчает структурирование. Джонсон приводит данные в пользу того, что
порядок слов действительно оказывает некоторое влияние на получаемые результаты.
Он сравнивает распределение значений ВОП для предложений трех разных типов:
1) нормального, т. е. осмысленного и синтаксически правильного (например, "The
house across the street burned down"); 2) синтаксически правильного, но бессмысленного
("The falsity calling flat sleep sang white") и 3) случайной последовательности
слов, лишенной смысла и правильной синтаксической структуры ("The sang white
falsity sleep calling flat"). He удивительно, что скорость заучивания этих трех
предложений была различной — первое заучивалось быстрее двух других, а третье
— медленнее всего. При этом распределение значений ВОП для двух синтаксически
правильных предложений (осмысленного и бессмысленного) было сходным. Это позволяет
предполагать, что испытуемые создавали структурные единицы по правилам синтаксиса,
независимо от наличия смысла. Величины ВОП для случайных групп слов были совершенно
иными, а именно эти группы и были построены без всякого соблюдения правил синтаксиса.
Таким образом, синтаксис, несомненно, играет определенную роль в структурировании.
Однако тот факт, что осмысленные предложения заучивались гораздо быстрее, чем
синтаксически правильные, но лишенные смысла, говорит о том, что и смысл имеет
большое значение. Другие (исследования (Salzinger а. о., 1962; Tejirian, 1968)
показали, что семантические факторы играют особенно важную роль в экспериментах
с приближением к английскому языку при порядках приближения выше третьего. Теджирян
(Tejirian, 1968) получал новые ряды слов, заменяя в рядах, приближающихся к
английскому языку, отдельные слова другими словами той же грамматической категории
(соответственно существительными, глаголами, прилагательными и т. д.). При такой
замене слов -семантическая структура ряда изменялась, но синтаксис оставался
прежним. Как показали эксперименты, при порядках приближения 3 и ниже подобные
замены не оказывали влияния на число припоминаемых слов. Это означает, что на
уровие 1-го — 3-го порядков приближения семантическое содержание не играет важной
роли в запоминании. Однако при порядках приближения выше 3-го семантическая
структура приобретает гораздо большее значение и замены слов ухудшают воспроизведение
материала.
Влияние особенностей правописания, синтаксиса и смысла показывает, каким образом
в процессе структурирования могут использоваться прочно заученные правила. Вы
могли заметить, что при обсуждении этих влияний мы рассмотрели несколько экспериментов,
которые, казалось бы, относятся скорее к долговременной, а не к кратковременной
памяти. Например, в экспериментах Тульвинга и Пэтко использовались списки из
24 элементов, что превышает объем КП, т. е. в них, очевидно, должна участвовать
ДП. Нетрудно заметить, однако, что такие эксперименты могут быть полезны для
изучения процессов структурирования, так как эти процессы, вероятно, должны
быть сходны с той переработкой информации, которая обеспечивает ее длительное
сохранение. Поскольку переработка, с которой связано структурирование материала
для хранения в КП, повышает прочность соответствующих долговременных следов,
изучение ДП может дать также ценные сведения о хранении информации в КП.
Структурирование облегчается и в том случае, если испытуемые заучивают правила,
созданные специально для этой цели. Например, в экспериментах Миллера (Miller,
1956)испытуемые обучались перекодированию длинных рядов нулей и единиц в более
короткие ряды цифр, научившись сначала переводить трехзначные структуры в отдельные
числа) следующим образом: 000=0; 001=1; 010=2; 011=3; 100=4; 101=5; 110=6; 111=7.
После этого при предъявлении им такой последовательности, как 001000110001110,
они разбивали ее на трехзначные структуры (001, 000, 110, 001, 110) и использовали
приведенный код для превращения их в отдельные цифры, получая в результате 10616.
После соответствующей практики испытуемые могли запоминать таким образом ряды,
в которых число нулей и единиц достигало 21!
Описанный выше способ структурирования относится к категории так называемых
мнемонических приемов, т. е. таких правил организации входного материала, которые
специально предназначены для его лучшего запоминания. Многие из этих приемов
известны издавна, а другие — вроде системы описанной Миллером, — созданы сравнительно
недавно. Некоторые мнемонические правила служат для запоминания той или иной
специфической информации (например, числа дней в месяцах), другие можно использовать
для любого ряда элементов. К таким универсальным способам относится, например,
старый мнемонический прием, называемый методом локальной привязки или методом
мест. Он состоит в том, что человек сначала заучивает ряд мест — можно, скажем,
; придумать десять различных мест, имеющихся в комнате ("на телевизоре", "около
стенных часов" и т. д.). Затем эти места используют для того, чтобы запоминать
списки предметов. Допустим, вам предъявили список из десяти предметов. Пользуясь
такой системой, вы мысленно связываете каждый; из этих предметов с теми местами,
которые вы заучили. Если, например, вам говорят: СОБАКА, ОГОНЬ, ГОРШОК, ...,
вы представляете себе собаку на экране телевизора, горящих стенные часы и так
далее. А в процессе припоминания вам достаточно будет мысленно переводить взгляд
с одной части комнаты на другую: представив себе телевизор, вы тут же вспомните
собаку, представив себе часы — вспомните об огне, и так до тех пор, пока не
восстановите в своей памяти все нужные предметы.
СОЗНАНИЕ И КРАТКОВРЕМЕННАЯ ПАМЯТЬ
Последнее, чего мы коснемся в нашем предварительном обсуждении КП, — это зависимость
между кратковременным хранением информации и "сознанием". Мы рассматривали КП
как рабочую память, так как это, по-видимому, то самое место, где над входными
элементами производятся различные операции — структурирование, опосредование
или повторение. Естественно возникает вопрос, не равнозначны ли такого рода
операции проявлениям сознания, или осознания: не означает ли "производить над
элементами действия" то же самое, что и "думать о них"?
В настоящее время на этот вопрос, по-видимому, нельзя дать удовлетворительного
ответа. Чем бы ни было сознание, это вряд ли то же самое, что и "работа" кратковременной
памяти. Чтобы убедиться в этом, обратимся к примеру с вечеринкой, когда человек,
участвуя в одном разговоре, слышит свое имя, упомянутое в другой группе присутствующих.
.Можно было бы сказать, что человек осознал факт произнесения его имени. В этом
смысле "осознать", по-видимому, эквивалентно тому, что выражается словами "уделить
внимание". Но если мы вспомним определение избирательного внимания, обсуждавшееся
в гл. 4, то внимание и осознание не покажутся нам синонимами. Когда вы, например,
ведете машину, большая часть связанных с этим стимулов подвергается, очевидно,
распознаванию, иначе вы съехали бы в кювет. Тем не менее нередко человек, управляющий
машиной, одновременно прислушивается к разговору, который ведут его пассажиры.
Он осознает разговор и не осознает всего того, что он делает с машиной, но между
тем уделяет по крайней мере некоторую часть своего внимания дороге (Kahneman,
1973). Мы можем допустить, однако, что управление автомобилем находится под
контролем процессов, предшествующих акту внимания и полному распознаванию образов,
а осознание соответствует полному распознаванию и полному вниманию. А это по
существу равносильно утверждению, что осознание соответствует кодированию информации
в КП. Если, однако, мы скажем, что осознание соответствует помещению информации
в КП, мы попадем в замкнутый круг. Откуда мы знаем, что что-то помещается в
КП? Да потому, что мы осознаём это; и в то же время мы определяем осознание
как внесение информации в КП. Создается впечатление, что в проблеме осознания
есть нечто "мистическое".
Ввиду этого кажется уместным рассмотреть здесь некоторые замечания Фрейда (Freud,
1925) о природе сознания и памяти — кратковременной и долговременной. Он проводит
аналогию с так называемым "волшебным блокнотом". Это пластинка из темного воскообразного
вещества, покрытая прозрачным целлулоидом, под которым находится еще полупрозрачный
листок тонкой вощеной бумаги. Записи делают заостренной палочкой, надавливая
ею на целлулоид. В свою очередь целлулоид давит на лежащий под ним тонкий листок,
который прилипает к восковой подушке, в результате чего на поверхности проступают
написанные слова. Чтобы стереть написанное, достаточно просто приподнять целлулоид
и вощеную бумагу, после чего можно делать новые записи. Иногда, если осторожно
приподнять два верхних слоя, можно увидеть, что восковая поверхность еще сохраняет
то, что было написано, хотя снаружи слова уже не видны.
Фрейд сравнивает с таким устройством память человека. По его мнению, память
состоит из двух частей: постоянной памяти, похожей на восковую пластинку, и
памяти, воспринимающей информацию и удерживающей ее лишь короткое время, которую
можно сравнить со средним листком. С этоН обновляемой, непостоянной памятью
и связано сознание: оно возникает, когда здесь появляется какая-то информация,
и исчезает, когда эта информация стирается. Все это очень напоминает описанное
нами деление памяти на К.П и ДП. Если это так, то создается впечатление, что
Фрейд считал явления кратковременной памяти частью сознания. И точно так же,
как отслаивание верхних листков "волшебного блокнота" приводило к исчезновению
сделанной записи, удаление информации из КП может приводить к удалению ее из
нашего сознания. Возможно, что Фрейд был прав — во всяком случае, мы не в состоянии
доказать, что он ошибался.
Глава 6
Кратковременная память: забывание
Представьте себе, что вы спрашиваете у телефонистки справочной
службы о номере телефона одного из ваших знакомых. Она дает вам нужный
номер, и вы повторяете его про себя, собираясь набрать его на диске. В это
время в комнату входит ваш приятель, и вы с ним здороваетесь. Когда вы
вновь хотите набрать номер, оказывается, что вы его уже не помните.
Информация об этом номере, находившаяся в вашей кратковременной памяти,
забыта.
Мы уже говорили о забывании, т. е. попросту утрате, информации, находящейся в КП; как мы предполагали в одной из предыдущих
глав, именно эта утрата лежит в основе "акустических" ошибок,
допускаемых в экспериментах по определению объема памяти. Мы объясняли эти
ошибки тем, что часть звукового следа какого-то элемента забывалась, и поскольку припоминание основывалось на сохранившихся в КП звуках, ошибочно
воспроизводимый элемент был акустически сходен с первоначальным.
По-видимому, частичное забывание представляет собой нормальную особенность
функции КП: хранящиеся в ней элементы могут постепенно утрачиваться.
Эта глава, в которой мы подробно рассмотрим процесс забывания, имеет
две цели. Одна цель состоит в постановке вопроса о причинах забывания
информации, хранящейся в ХП; эта проблема возникла довольно давно, и вокруг
нее ведутся споры. Другая цель-привлечь внимание к некоторым
экспериментальным факторам, влияющим на забывание, и попытаться получить
дополнительные данные о кратковременном хранении информации.
ТЕОРИИ ЗАБЫВАНИЯ
К вопросу о причинах забывания обычно подходят с двух альтернативных точек
зрения-.абывание рассматривается либо как "пассивное угасание" следов, либо
как результат "интерференции". Чтобы сделать смысл этих понятий более ясным,
постараемся представить проблему в упрощенном виде. Начнем с рассмотрения следа,
находящегося в КП. О свежем следе мы можем сказать, что он обладает предельной
четкостью (это несколько неопределенное понятие, но здесь оно означает "количество
имеющейся информации" или ее "полноту"). О забывании можно говорить, когда данный
след уже не обладает предельной четкостью, например если часть информации о
звучании данного элемента утрачена. Обычно это происходит только в отсутствие
повторения, поскольку мы предполагаем, что повторение поддерживает четкость
следа на первоначальном уровне. Забывание наступает при таком уменьшении четкости
следа, при котором данный элемент не может быть восстановлен в памяти. Главный
вопрос, который нас интересует, — это причина снижения четкости следа. Мы рассмотрим
две обычно выдвигаемые причины: 1) пассивное угасание и 2) интерференцию.
Под угасанием обычно понимают уменьшение четкости (или прочности) следов памяти
с течением времени. Предполагается, что для такого ослабления следов необходимо
только время-никакие другие причинные факторы здесь не участвуют. Поэтому мы
и называем угасание пассивным. В отличие от гипотезы угасания гипотеза интерференции
исходит из того, что причина забывания носит более активный характер, согласно
этой гипотезе, четкость следа того или иного элемента убывает в результате поступления
в КП новых элементов; таким образом, ослабление следов обусловлено не просто
течением времени, а появлением в памяти новой информации.
Было бы нетрудно установить, какая из этих двух гипотез верна, если бы можно
было провести следующий опыт. Сначала нужно предъявить испытуемому какой-нибудь
элемент. Затем испытуемый должен в течение некоторого времени примерно 30 с
(это так называемый "интервал удержания") ничего не делать. "Ничего" следует
понимать в абсолютном смысле — никакого повторения (поскольку это способствовало
бы поддержанию четкости следа) и никаких размышлений о других вещах (так как
при этом в КП могла бы поступить новая информация и возникла бы интерференция).
По прошествии 30 с испытуемого попросили бы вспомнить предъявленный элемент.
Если он не сможет восстановить его в памяти, это будет говорить в пользу пассивного
угасания, так как единственным действующим фактором могло быть протекшее время.
Ничто за этот период не могло вызвать интерференции. Если же элемент за это
время не был забыт, мы сможем считать этот факт доводом против гипотезы
угасания, т. е. в пользу представления об интерференции.
К сожалению, такой идеальный эксперимент неосуществим, так как невозможно представить
себе ситуацию, в которой испытуемый не делал бы абсолютно ничего. Однако, как
мы увидим позже, предпринимались попытки достичь наибольшего приближения к таким
условиям, и результаты оказались довольно противоречивыми.
Прежде чем перейти к рассмотрению этих экспериментов, обсудим более подробно
две альтернативные гипотезы. Займемся сначала гипотезой интерференции. Один
из вариантов этой гипотезы можно было бы назвать "моделью простых ячеек" или
"моделью вытеснения". Согласно этой модели, в КП имеется определенное число
ячеек — 7+2(-2). В каждой ячейке помещается одна структурная единица входного
материала. При поступлении элементов в КП каждый элемент (структурная единица)
занимает одну ячейку. Когда все ячейки будут заполнены и для вновь поступающих
элементов не окажется места, старые элементы должны будут куда-то переместиться,
чтобы освободить место для новых. В такой модели каждый новый элемент, поступающий
в заполненную КП, вытесняет один из находящихся в ней элементов, что и приводит
к забыванию последнего. Каждый из содержащихся в КП элементов имеет некоторые
шансы, быть вытесненным.
Модель вытеснения представляет
интерес в том отношении, что она помотает разъяснить более общую гипотезу,
согласно которой забывание информации, хранящейся в КП, обусловлено
интерференцией. Одно из следствий этой модели состоит в том, что первые
несколько элементов, поступивших в КП, не интерферируют друг с другом.
Очевидно, забывания не должно происходить до тех пор, пока в КП не будут
заполнены все ячейки: оно начнется лишь тогда, когда число элементов
превысит емкость КП. Из модели вытекает еще одно следствие: поскольку каждый
элемент (или структурная единица) занимает одну ячейку, которая либо
содержит этот элемент, либо нет, каждый элемент либо должен быть полностью удален (в ячейке его не будет), либо целиком останется на
месте. Между тем мы знаем, что это не так. Явление акустического смешения
слогов (например, названий букв), содержащихся в КП, можно объяснить
частичным забыванием этих слогов — стиранием следов отдельных фонем. Если
один слог соответствует одной структурной единице, то
такого рода частичное забывание несовместимо с моделью простых
ячеек.
Нетрудно модифицировать эту простую модель так, чтобы сделать ее совместимой
с частичным забыванием. Для этого достаточно предположить, что полнота находящегося
в КП элемента может быть различной, т. е. принимать несколько значений: "целиком
здесь", "в основном здесь", "осталось немножко", "полностью удален". Видоизменяя
модель таким образом мы, в сущности, допускаем, что след данного элемента может
быть неодинаково четким, если четкость зависит от полноты информации. В этом
измененном виде гипотеза вытеснения постулирует, что новые элементы, поступающие
в КП, могут частично вытеснять другие элементы, т. е. могут быть причиной уменьшения
четкости их следов.
В модификации нуждается еще одно положение, вытекающее из модели простых ячеек,
а именно — что забывание хранящихся в КП элементов происходит только тогда,
когда число элементов превышает объем КП. Ведь если забывание возможно лишь
после заполнения КП, гипотеза угасания и гипотеза интерференции становятся совместимыми.
Чтобы это стало понятным, рассмотрим гипотезу угасания следов с точки зрения
теории двойственности памяти: гипотеза угасания приложима только к незаполненной
КП, ибо идея об ограниченной емкости КП влечет за собой представление о том,
что забывание начинается тогда, когда в КП поступает больше информации, чем
она может вместить. Такое забывание нельзя приписывать пассивному угасанию;
поэтому речь может идти только о забывании, происходящем тогда, когда количество
информации в КП не выходит за пределы объема памяти1. Однако если
гипотеза угасания наиболее пригодна для объяснения забывания при отсутствии
перегрузки КП, то следует ввести аналогичное ограничение и для гипотезы интерференции.
Иными словами, в нашей гипотезе интерференции не должно предполагаться, что
забывание информации, хранящейся в КП, возможно только тогда, когда ее количество
превышает емкость КП. Ведь иначе между двумя гипотезами не было бы никакого
противоречия: гипотеза угасания относилась бы к случаям, когда количество информации
меньше емкости КП, а гипотез,а интерференции — к случаям, когда оно больше.
Короче говоря, в гипотезу вытеснения необходимо внести еще одну модификацию
— нужно допустить, что .интерференция может вести к забыванию содержащейся в
КП информации, даже если количество этой информации не превышает объема КП.
Иными словами, внесение новых элементов в КП может интерферировать с данным
элементом даже тогда, когда в КП достаточно места для всех этих элементов. В
таком виде гипотеза интерференции противоречит гипотезе угасания, согласно которой
четкость следа данного элемента в КП постепенно снижается, даже если в КП для
него достаточно места и в нее не поступает никаких других элементов.
1Это
ограничение приложимости гипотезы угасания, диктуемое концепцией
ограниченной емкости кратковременного хранилища, несколько отличается от
традиционных представлений об угасании. Вне рамок теории двойственности
гипотеза угасания применима независимо от того, превышает ли количество
забываемой информации объем непосредственной памяти или же оно меньше
этого объема. В сущности, объем памяти можно рассматривать как результат
угасания. Когда число предъявленных элементов невелико, все их следы могут
поддерживаться путем повторения, которое успевает произойти раньше, чем
соответствующий след будет полностью стерт; в результате при вспоминании
не возникает ошибок. Когда же число предъявленных элементов велико,
повторить каждый из них до угасания следа становится невозможным; поэтому
некоторые следы угасают, и при воспроизведении возникают ошибки. Таким
образом, объем памяти мог бы определяться наибольшим числом элементов,
которые могут быть повторены за то время, пока еще ни один след полностью не
угас.
Возможны и дальнейшие видоизменения гипотезы интерференции. Некоторые теоретики
считают, что интерференция зависит от степени сходства между вновь постутающими
в КП элементами и теми, которые в ней уже находятся. Этот вариант можно было
бы назвать "интерференцией по сходству" в отличие от простой "интерференции
вытеснения", степень которой не определяется сходством между элементами.
Наша новая, пересмотренная гипотеза интерференции состоит в следующем. Каждый
хранящийся в КП след обладает известной четкостью. Когда данный элемент только
что поступил в КП или повторяется, след его обладает предельной четкостью. Забывание
наступает после того, как прочность понизилась настолько, что элемент уже не
может быть восстановлен и воспроизведен. Причиной забывания служит поступление
в КП новых элементов. Мы можем также допустить, что степень забывания зависит
от сходства этих новых элементов с первоначальными. Постепенно, по мерепоступления
в КП новых элементов, следы тех элементов, которые находились в ней прежде,
угасают (рис. 6.1, А). В отличие от этого гипотеза пассивного угасания утверждает,
что забывание определяется только временем, а не интерференцией с другими элементами
(рис. 6.1, Б).
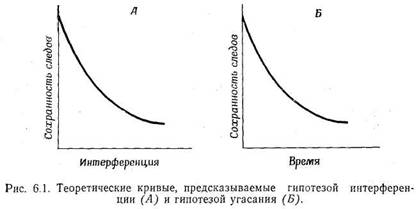
Два изображенных на рис. 6.1 графика явно отличаются друг от друга. На одном
по оси абсцисс отложена степень интерференции, на другом — время. Для того чтобы
выяснить, какая из двух гипотез верна, следует перевести теоретическую (внутреннюю,
непосредственно не наблюдаемую) переменную "сохранность следа" в нечто явно
выраженное и измеримое. Тогда мы сможем установить, что влияет на эту величину:
если действует само время, то мы получаем довод в пользу гипотезы угасания,
а если интерферирующие элементы, то в пользу гипотезы интерференции. Мерой,
предположительно отражающей сохранность следа, мог бы, например, служить процент
правильных ответов в задачах на припоминание. Допустим, что мы предъявляем испытуемому
небольшой набор элементов, а затем добавляем ряд элементов, предназначенных
специально для создания интерфереяции, после чего просим испытуемого припомнить
исходный набор. Если процент правильных ответов снижается в зависимости от числа
интерферирующих элементов, то это можно считать доводом в пользу гипотезы интерференции.
К сожалению, проведение такого рода экспериментов связано с рядом трудностей.
Введение интерферирующих элементов занимает какое-то время, поэтому чем больше
таких элементов предъявляют испытуемому, тем больше проходит времени. В результате
две переменные — число элементов и и количество времени — смешиваются: с увеличением
одной возрастает и другая, и невозможно бывает сказать, что именно ухудшило
эффективность припоминания — время или число интерферирующих элементов. Именно
из-за такого смещения факторов и приходится искать какой-то другой метод для
проверки этих двух гипотез. Таким методом мог бы служить описанный выше идеальный
эксперимент, в котором просто проходит время и нет никакой интерференции. Если
в этих условиях будет происходить забывание, то ясно, что его причина — само
время, и в таком случае теория угасания получит подтверждение. Если же забывания
не будет, то нам придется забыть о теории угасания.
ЭКСПЕРИМЕНТЫ С ДИСТРАКТОРОМ
Мы не можем провести идеальный эксперимент, но это не значит, что к
нему нельзя приблизиться. Для этого чаще всего используют так называемые
эксперименты с дистракторами, впервые поставленные Брауном (Brown, 1958) и
Петерсоном и Петерсон (Peterson a. Peterson, 1959). Заслугу в
разработке экспериментов, позволяющих сделать выбор между гипотезой
угасания и гипотезой интерференции в КП, приписывают Петерсонам; их работы
вообще сильно способствовали развитию исследований в области
кратковременной памяти.
Петерсоны использовали очень простой метод. Они производили с испытуемыми ряд
проб, заключавшихся в следующем. Сначала предъявляли (на слух) 1ряд, состоящий
из трех согласных (триграмму), например буквы PSQ, а затем трехзначное число,
например 167. После этого испытуемый производил обратный счет скачками через
3 единицы (167, 164, 161, 158...) в такт ударам метронома в течение некоторого
времени, называемого интервалом удержания. Затем подавался сигнал, по которому
испытуемый должен был вспоминать три предъявленные буквы.
Такие эксперименты называют задачами с дистрактором; считается, что обратный
счет отвлекает внимание испытуемого и не дает ему возможности повторять буквы,
из которых состоит триграмма. Предполагается, однако, что счет не интерферирует
с буквами триграммы, сохраняемыми, по-видимому, в КП, потому что числа не должны
храниться в КП для последующего припоминания. Таким образом, создаются условия,
близкие к тому случаю, когда время (в форме интервала удержания) идет, а испытуемый
ничего не делает, за исключением обратного счета, который, как полагают, не
оказывает интерферирующего воздействия. Если испытуемый забывает буквы, то это
служит доводом в пользу теории угасания.
Результаты эксперимента Петерсонов приведены на рис. 6.2. При использованных
ими интервалах удержания — от 3 до 18 с — способность испытуемого припоминать
триграмму заметно снижалась. Это было удивительно — в исследованиях памяти до
тех пор не наблюдалось такого быстрого забывания. Во-первых, в большей части
проводившихся в то время опытов использовались длинные списки элементов, привычные
методы последовательного припоминания, парных ассоциаций и т. д. Во-вторых,
в экспериментах с такими длинными списками кривые забывания строились как функции
времени, выраженного в часах или днях. И что самое удивительное, результаты
этого эксперимента можно было легко объяснить пассивным угасанием следов в КП.
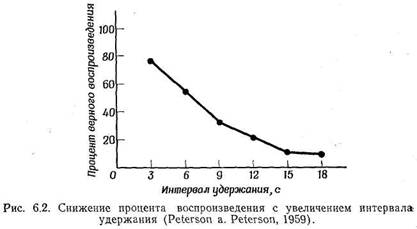
Полученные Петерсонами данные в пользу гипотезы пассивного угасания явились
важным событием в изучении памяти. Это произошло в то время, когда теория двойственности
памяти уже была известна (Hebb, 1949), но еще отнюдь неполучила широкого признания.
Кроме того, значительное количество имевшихся в то время данных указывало на
то, что главной причиной забывания из долговременной памяти следует считать
интерференцию: содержащийся в памяти материал по прошествии длительных периодов
времени оказывался забытым, так как его, по-видимому, разрушала другая информация.
Таким образом, результаты эксперимента с дистрактором позволяли предполагать
существование двух механизмов забывания — пассивного угасания и интерференции
в ДП, и это сильно склоняло к мысли о возможности двух типов забывания, coотвeтcтвующиx
двум системам памяти. Иными словами, данные Петерсонов о действии угасания на
коротких интервалах и данные других авторов о действии интерференции на длительных
интервалах можно было приписать тому, что забывание происходит в двух разных
хранилищах информащии — в КП и в ДП.
Все это привело к тому, что перед теоретиками, которых больше устраивал один
тип памяти, возникла задача: тем или иным способом показать, что результаты
Петерсонов не обязательно говорят о существовании не известной ранее кратковременной
памяти, в которой забывание происходит путем угасания. Наиболее перспективный
способ развенчать концепцию КП состоял бы в том, чтобы доказать подлинную причастность
интерференции к забыванию на коротких интервалах. Для того чтобы понять, как
это можно было бы сделать, нужно представить себе, что нам было известно об
интерференции как о причине забывания в ДП. Большая часть данных была получена
методом парных ассоциаций в экспериментах с так называемым проактивным торможением
(ПТ) и ретроактивным торможением (РТ).
Схема экспериментов с ПТ и с РТ представлена на рис. 6.3. Из этих двух явлений
ретроактивное торможение (РТ) ближе к тому, что мы называли интерференцией:
речь идет здесь об отрицательном влиянии новой информации на сохранение в памяти
материала, заученного ранее; именно поэтому такoe торможение называют ретроактивным.
При измерении РТ обычно используется несколько списков элементов, а не один,
как это чаще бывает при изучении кратковременной памяти. В экспериментах с РТ
участвуют две группы испытуемых — опытная и контрольная. Опытная группа заучивает
два списка парных ассоциаций — сначала "список А", а затем "описок В". Испытуемые
заучивают каждый список до тех пор, пока эффективность воспроизведения не достигнет
определенного уровня — может, например, требоваться трехкратное воспроизведение
списка без единой ошибки. Затем по прошествии интервала удержания испытуемых
просят воспроизвести первый из заученных ими списков — список А. Контрольная
группа проделывает то же самое с той разницей, что испытуемые не заучивают списка
В. Как показали эти эксперименты, эффктивность воспроизведения у контрольной
группы выше, чем у опытной. Вероятно, это связано с тем, что заучивание спиока
В, проводившееся только опытной группой, оказывало разрушающее (интерферирующее)
воздействие на следы памяти для списка А.
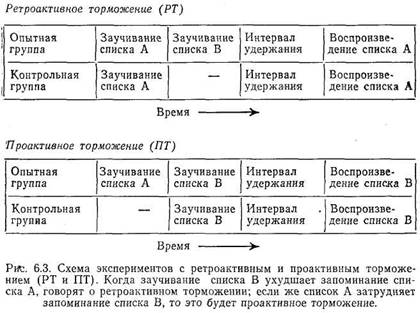
Возможно ли, что в экспериментах Петерсонов имело место ретроактивное торможение?
Ответ был бы утвердительным, если бы обратный счет интерферировал с хранящейся
в памяти триграммой. В то время это казалось маловероятным, поскольку для счета
не требовалось удерживать в памяти новую информацию. Кроме того, числа, называемые
при счете, сильно отличались от букв, которые следовало помнить. В то время,
когда Петерсоны проводили свои исследования, относительно РТ было хорошо известно,
что его влияние велико, когда материал, подлежащий запоминанию (список А), и
интерферирующий материал (список Б) сходны, и мало, когда они несходны. А так
как числа, по-видимому, несходны с буквами, сторонники теории интерференции
не пытались показать, что хранившаяся в памяти триграмма забывалась под влиянием
РТ, создаваемого счетом.
Мы уже упоминали о проактивном торможении (ПТ) как о другой возможной причине
забывания информации, хранящейся в кратковременной памяти. Метод изучения ПТ
очень сходен с методом изучения РТ, но только интересуются здесь интерференцией,
противоположно направленной во времени, — влиянием заучивания списка А на припоминание
заученного после него списка Б; запоминание этого второго списка проверяют
по прошествии интервала удержания (рис. 6.3). Обычно опытная группа, запоминавшая
сначала список А, а затем список Б, воспроизводила список Б хуже, чем контрольная,
которая не заучивала списка А. В таких случаях можно говорить о проявлении у
опытной группы проактивного торможения.
Могло ли проактивное торможение служить причиной забывания в эксперименте Петерсонов?
Никакого очевидного источника ПТ в этом эксперименте не было, поскольку, казалось
бы, предъявлению триграммы в каждой пробе не предел: забывание шествовало заучивание
какого-либо материала. Однако не следует спешить с выводами; ведь каждая проба
производится не сама по себе, а входит в длинный ряд других проб, а поэтому
возможно, что более ранние пробы оказывают воздействие на более поздние. Подобный
эффект ПТ не мог бы отчетливо выявиться в данных Петерсонов, так как он затемнялся
самим способом постановки эксперимента.
Мы можем рассуждать
следующим образом. В экспериментах Петерсонов испытуемые участвовали в
двух тренировочных пробах, за которыми следовало 48 проб (по 8 проб с
каждым из шести различных интервалов удержания). Как известно, проактивное
торможение быстро возрастает до максимума. Поэтому, хотя отрицательное
влияние заучивания одного списка на запоминание и воспроизведение другого
может быть велико, эффект заучивания двух списков будет ненамного
больше, чем эффект одного, а эффект пяти списковненамного больше эффекта
четырех. Поэтому следовало бы ожидать, что в эксперименте Петерсонов ПТ
будет быстро достигать максимума на протяжении нескольких первых проб (в
число которых входят и две тренировочные пробы), а в дальнейшем, вплоть до
48-й пробы, будет находиться на максимальном уровне. Для того чтобы
выяснить, проявляется ли здесь ПТ, нужно было бы учитывать лишь несколько
первых проб для каждого испытуемого, обеспечив равномерное
распределение всех интервалов удержания между последовательными пробами.
Приведенные выше рассуждения принадлежат Кеппелю и Андервуду (Keppel a.
Underwood, 1962), которые и поставили соответствующий эксперимент. Они
попытались выяснить, действует ли проактивное торможение в экспериментах с
дистрактором. Для этого они должны были проводить с каждым
испытуемым не более нескольких проб и, кроме того, обеспечить, чтобы каждый
интервал удержания одинаково часто сочетался с первой, второй и т. д.
пробами. Они достигли этого, используя три интервала удержания, по три
пробы на каждого испытуемого (по одной на каждый интервал) и большое
число испытуемых. Полученные данные представлены на рис. 6.4.
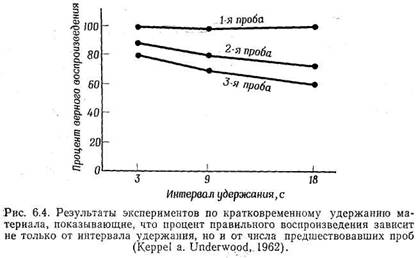
Результаты экспериментов Кеппеля и Андервуда имели большое значение для сторонников
теории единства памяти. Полученные данные для первой пробы показывают, что на
протяжении 18-секундного интервала никакого забывания не происходило. Однако
в последующих пробах, когда создавалась возможность возрастания ПТ, обнаруживалось
быстрое забывание, которое и наблюдали ранее Петерсоны. По-видимому, законы,
управляющие забыванием при долговременном хралении информации, а именно законы
проактивного торможения, определяют и время так называемого забывания из кратковременной
памяти, которое, таким образом, представляет собой результат интерференции.
Кеппель и Андервуд шриписывали забывание из кратковременной памяти, наблюдавшееся
в эксперименте Петерсонов, изменениям в эффекте проактивного торможения. При
изучении ПТ традиционным методом наблюдалось возрастание ПТ с увеличением интервала
удержания (на рис. 6.3 это период времени между заучиванием списка Б и его воспроизведением).
Это объясняли воостановлением прочности следов списка А (первоначально понизившейся
в результате заучивания списка Б) во время интервала удержания. Восстановление
списка А предположительно приводит к тому, что он все больше и больше интерферирует
со cписком Б. В экспериментах с дистрактором аналогичный эффект означал бы,
что после 18-секундного интервала проактивное торможение должно быть больше,
чем после 3-секундного, что и могло бы приводить кнаблюда1вшемуся забыванию.
Конечно, это было бы возможно только в том случае, если имелось некоторое ПТ,
которое .могло бы возрастать, т. е. если уже было проведено несколько проб для
создания ПТ. Таким образом, мы можем предсказать, что количество припоминаемого
материала должно уменьшаться с увеличением интервала удержания, но только после
нескольких первых проб. Именно это и наблюдали Кеппель и Андервуд.
Кеппель и Андервуд интерпретировали полученные ими: результаты в соответствии
с теорией единства памяти; они не были сторонниками теории двойственности. Но,
поскольку мы знаем, что есть и другие основания подразделять память на КП и
ДП, мы можем истолковать их результаты как довод в пользу гипотезы интерференции.
Забывание из КП оказывается феноменом, который может быть предсказан на основании
данных о проактивном торможении.
МЕТОД ЗОНДА
Рассмотрим теперь другое исследование (Waugh a. Norman, 1965), в котором получены
иного рода данные oтнocитeльнo интерференции в КП. В нем изучалось интерферирующее
воздействие последующей информации на материал, уже находящийся в КП. Проведенные
эксперименты не были приближением к описанному выше идеальному эксперименту,
поскольку в них не использовался дистрактор; вместо этого была сделана попытка
разделить эффекты "чистого" времени и числа промежуточных элементов — эффекты,
которые, как мы отмечали, обычно изменяются совместно. Для этого разделения
был использован так называемый "метод зонда". Этотметод состоит в следующем:
испытуемому предъявляют для запоминания ряд цифр (например, 16 цифр). Шестнадцатая
цифра уже встречалась среди остальных пятнадцати, и она используется в качестве
"зонда". Испытуемого просят припомнить цифру, которая следовала за первым появлением
цифры-зонда (при втором появлении цифра-зонд сопровождается звуковым сигналом,
указывающим на то, что эта цифра последняя в ряду, — чтобы испытуемому не приходилось
считать цифры).
Испытуемому может быть зачитан, например, следующий ряд
1 4 7 9 5 1 2 6 4 3 8 7 2 9 0 5*
(здесь звездочка обозначает звуковой сигнал). Испытуемому задают вопрос: "Какая
цифра следовала за цифрой 5 при ее первом появлении?" Верным ответом будет "единица".
В этих экспериментах важно выяснить зависимость среднего процента правильных
ответов, т. е. правильных припоминаний цифры, следующей за первым появлением
зонда, от числа цифр между первым предъявлением этой цифры и ее воспроизведением
(после цифры-зонда со звуковым сигналом). В приведенном примере таких промежуточных
цифр (включая цифру-зонд) было десять. Этот метод позволяет изучать припоминание
в его прямой зависимости от числа промежуточных цифр, которые принимаются здесь
за интерферирующие единицы.
Для того чтобы исследовать влияние "чистого" времени, следует ввести еще один
переменный фактор: можно варьировать скорость предъявления цифр (скажем, от
четырех цифр в секунду до одной в секунду). Это позволяет независимо изменять
время и число интерферирующих единиц. Иными словами, мы можем теперь раздельно
изучать влияние двух факторов-количества времени между первым и вторым появлениями
цифры-зонда и числа интерферирующих единиц.
Значение этого станет более ясным, если мы посмотрим, каких результатов следует
ожидать исходя из гипотезы угасания и из гипотезы интерференции. Если верна
гипотеза угасания, припоминание должно зависеть от прошедшего времени и не зависеть
от числа промежуточных цифр. А это означает, что разная скорость предъявления
приведет к разной эффективности припоминания при данном числе промежуточных
элементов, так как время, протекающее между первым и вторым появлением цифры-зонда,
будет зависеть от скорости предъявления цифр. Представив влияние этого времени
на процент правильных ответов в виде графика, мы получим кривую, изображенную
на рис. 6.5, А. Это гипотетическая кривая, основанная на предположении, что
забывание происходит постепенно, как функция времени, независимо от числа промежуточных
цифр, предъявляемых на протяжении этого времени (поэтому при обеих скоростях
предъявления результаты одинаковы, хотя для любого данного периода времени большая
скорость соответствует большему числу интерферирующих элементов, чем малая).
На рис. 6.5, Б те же данные представлены несколько иначе: по оси абсцисс отложено
число промежуточяых элементов. Такая кривая означает, что число элементов само
по себе не определяет забывания; при таком построении графика забывание тоже
зависит от времени, соответствующего данному числу элементов и зависящему от
скорости их предъявления.
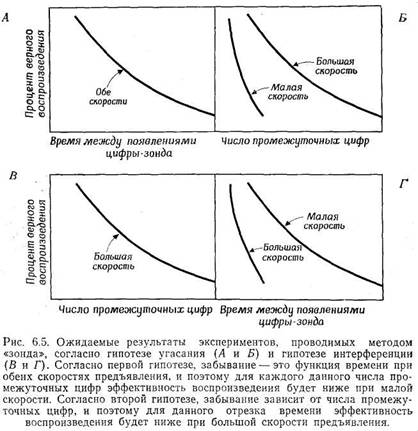
Рассмотрим теперь предсказания гипотезы интерференции, согласно которой главным
фактором, определяющим забывание, служит число цифр, предъявляемых в промежутке
между первым и вторым появлением зонда. Эти предсказания тоже можно графически
изобразить двумя способами (рис. 6.5, В и Г). На рис. 6.5, В представлены гипотетические
данные, основанные на предположении, что припоминание зависит от числа промежуточных
элементов и не зависит от скорости их предъявления. Рис. 6.5, Г показывает,
что если построить график зависимости тех же данных от времени, то мы получим
две разные кривые для двух скоростей предъявления, так как при этих двух скоростях
за любой данный промежуток времени будет предъявлено разное число .элементов
(при высокой скорости больше, чем при низкой).
Для того чтобы выяснить, какая же из двух гипотез верна, мы сравним эти предсказания
с экспериментальными данными, представленными на рис. 6.6 (Waugh a. Norman,
1965). Эти данные говорят в пользу гипотезы интерференции. При обеих скоростях
предъявления забывание определяется числом цифр, отделяющих первое появление
припоминаемой цифры от ее воспроизведения. Здесь уместно будет заметить, что
этот результат можно было предсказать исходя из кривой зависимости свободного
припоминания от места элемента в ряду. Мы знаем, что скорость предъявления не
влияет на концевой участок этой кривой, который, видимо, отражает припоминание
из КП (см. рис. 2.2,В). Тот факт, что в этой ситуации, так же как и в экспериментах
с "зондом", припоминание из КП не .зависит от скорости предъявления, означает,
что время здесь не играет роли, тогда как число промежуточных элементов (место
в ряду) имеет существенное значение.
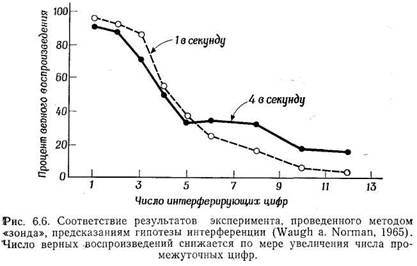
ДРУГИЕ ЭКСПЕРИМЕНТЫ С ДИСТРАКТОРОМ
Результаты описанных выше экспериментов с цифрой-зондом говорят в пользу того,
что забывание из КП обусловлено интерференцией. Если добавить эти результаты
к данным Кеппеля и Андервуда (Keppel a. Underwood, 1962), показавших, что с
проактивным торможением связано также и быстрое забывание в экспериментах Петерсонов,
то создается впечатление, что гипотеза интерференции имеет довольно прочную
основу. Поэтому мы рассмотрим еще одно "приближение" к нашему идеальному эксперименту
— эксперимент, проведенный Джудит Рейтман (Reitman, 1971); это наилучшее из
всех рассмотренных нами до сих пор приближений. Рейтман провела эксперимент
с дистрактором, в котором отвлекающим заданием был не обратный счет, а задача
на обнаружение сигнала. Испытуемым сначала предъявляли три слова, которые они
должны были запомнить. Затем на протяжении 15 с они прислушивались, ожидая появления
определенного тона на фоне белого шума (обнаружение сигнала); услышав этот тон,
они должны были нажать на кнопку. Задание было довольно трудным; звук был таким
слабым, что испытуемые могли слышать его только в течение примерно половины
времени. Поэтому задание можно было считать достаточно труддым для того, чтобы
оно мешало повторению слов. Кроме того, оно, по-видимому, не интерферировало
с тремя словами, находившимися в КП. Следовательно, его можно было рассматривать
как разумное приближение к тому состоянию "ничегонеделания", которым должен
быть заполнен интервал удержания в идеальном эксперименте. После 15-секундного
периода, в течение которого испытуемые прислушивались к звуковому сигналу, они
делали попытки вспомнить три слова, предъявленные в начале эксперимента.
Рейтман хотела выяснить, способны ли испытуемые помнить эти три слова. Она
пыталась также исключить возможность повторения этих слов испытуемыми на протяжении
15-секундного интервала. Чтобы установить, удалось ли ей устранить повторение,
она сравнивала точность и скорость, с которой испытуемые обнаруживали звуковой
сигнал, с теми же показателями для контрольных испытуемых, которые не должны
были помнить три слова, а только следили за звуковым сигналом. При такой проверке
никаких различий между двумя группами обнаружено не было; это говорило о том,
что опытная группа в самом деле была занята обнаружением сигнала и не повторяла
предъявленных слов. Поэтому Рейтман сочла, что результаты ее экспериментов действительно
позволяют судить о том, что происходит с находящейся в КП информацией, если
повторение исключено. Эти результаты ясно показали, что на протяжении 15-секундного
периода забывания не происходит: в отличие от Петерсонов Рейтман наблюдала почти
полное удержание в памяти слов по истечении 15 с. Иначе говоря, не было оснований
считать, что в этот период происходит угасание.
В другом варианте эксперимента Рейтман получила несколько иные результаты,
более сходные с первоначальными данными Петерсонов. В этом варианте отвлекающей
задачей служило обнаружение не просто звукового сигнала, а определенного слога:
они должны были заметить слог ТОН, произносимый иногда в ряду слогов ДОН. При
таком дистракторе эффективность вопроизведения предъявленных вначале слов резко
снизилась — со 100 до примерно 75%. Очевидно, характер отвлекающего задания
существенно влияет на забывание из КП.
Данные Рейтман были
подтверждены и дополнены в экспериментах Шифрина (Shiffrin, 1973), который
применял в качестве дистрактора обнаружение сигнала, продолжавшееся 1, 8 или 40 с. Кроме того, в некоторых пробах о;н
увеличивал интервал удержания, вводя арифметическую задачу, которую
следовало решить после обнаружения сигнала. Последний вариант имел целью
выявление "потолочного эффекта". Под этим имеют в виду
предполагаемое "скрытое" уменьшение прочности следов памяти в период,
когда испытуемые занимались обнаружением сигнала, — уменьшение
прочности, недостаточ.ное для того, чтобы сколько-нибудь снизить
эффективность .воспроизведения по сравнению с "потолком", т. е.
100%-ным воспроизведением.
Типичная проба в экспериментах Шифрина производилась следующим образом: испытуемый
прослушивал пентаграмму — группу из пяти согласных (например, RLXBT). Затем
он выполнял задачу обнаружения сигнала в течение 1, 8 или 40 с. В некоторых
пробах испытуемому после этого предлагали еще задание с арифметическими действиями,
выполнение которого продолжалось 5 или 30 с. Задача заключалась в прибавлении
однозначных чисел, предъявлявшихся одно за другим через 2-секундные интервалы,
к начальному трехзначному числу (например, 203+4+7+6+9+...).
Шифрин, так же как и Рейтман, нашел, что период обнаружения сигнала, независимо
от его длительности, не оказывал влияния на припоминание пентаграммы; во всех
случаях ее воспроизведение было почти безошибочным. Но добавление арифметической
задачи нарушало припоминание, причем 30-секундная задача нарушала его сильнее,
чем 5-секундная. Этот отрицательный эффект не зависел, однако, от продолжительности
периода об.наружения сигнала: после 40-секундного периода он проявлялся не больше,
чем после 1-секундного. Это говорит о том, что за период обнаружения сигнала
никакого угасания следа не происходило, т. е. "потолочный эффект" отсутствовал.
Ведь если бы за это время прочность следа пентаграммы уменьшалась (хотя бы и
не настолько, чтобы это привело к забываниию), то добавочный эффект арифметической
задачи "доводил бы дело до конца". В особенности этого следовало бы ожидать
после длительного периода обнаружения сигнала, так как промежуток времени между
предъявлением пентаграммы и ее воспроизведением был бы тогда максимальным и
поэтому угасание наибольшим. Добавление арифметической задачи приводило бы к
заметному забыванию. Таким образом, в случае угасания следа введение арифметической
задачи больше снижало бы эффективность припоминания согласных в варианте с 40-секундным
периодом обнаружения сигнала, чем в варианте с 1-секундным периодом. Отсутствие
такого различия говорит о том, что выполнение заданий на обнаружение сигнала
не оказывает никакого влияния на прочность следов в памяти.
В результате этих экспериментов создавалось впечатление, что нет никаких оснований
объяснять забывание хранящейся в КП информации угасанием следов; можно было
думать, что оно целиком обусловлено интерференцией. Однако положение вещей изменилось,
после того как Рейтман повторила свой первоначальный эксперимент, введя новые
условия для контроля "потолочного эффекта" и повторения. В отношении "потолочного
эффекта" ее беспокоили те же обстоятельства, что и Шифрина: она хотела исключить
возможность того, что испытуемые в период удержания забывают часть информации,
хотя и не в такой степени, чтобы уже нельзя было восстановить в памяти все три
предъявленных слова. Ей казалось также, что первоначальные эксперименты, в которых
она пыталась выяснить, не повторяют ли испытуемые в период удержания предъявленный
материал, были, возможно, недостаточно строгими. Ведь если испыгуемые незаметно
повторяли его, то это и могло быть причиной того, что забывания не происходило.
Ввиду этого Рейтман провела эксперименты,
спланированные таким образом, чтобы устранить "потолочный эффект" и
точно определить возможность повторения. Для устранения "потолочного
эффекта" она предъявляла испытуемому не три слова, как в первоначальном
варианте, а пять. А чтобы учесть возможность повторения, была разработана
сложная система анализа с семью различными оценками эффективности
припоминания слов и обнаружения сигнала; этот анализ позволял судить о
том, повторял ли испытуемый слова, какой из нескольких способов повторения
он выбрал и насколько активным было это повторение. Эти оценки производились при следующих условиях: 1) когда испытуемого специально
просили незаметно повторять материал; 2) когда его просили не повторять
материал; 3) когда ему не предъявлялось никаких элементов для повторения;
4) при полном воспроизведении первоначального эксперимента.
Полученные Рейтман результаты подтвердили ее опасения: оказалось, что на ее
первоначальных данных сказывался потолочный эффект. Она установила также, что
в первоначальном эксперименте испытуемые незаметно повторяли материал и что
применявшиеся ею способы проверки этого были недостаточно эффективны. Более
того, в ее новых экспериментах лишь десяти испытуемым из 52, по-видимому, удалось
избежать повторения, когда их об этом просили. Из этих 10 испытуемых и была
создана группа для проведения решающего эксперимента: угасание или интерференция?
Действительно ли они забывали предъявленную им информацию за 15-секундный интервал
удержания, во время которого они были заняты обнаружением звукового сигнала
и избегали повторения? Ответ оказался утвердительным: за эти 15 с терялось в
среднем около 25% первоначально получеяной информации. Это указывало на то,
что следы в период удержания угасали. Важно отметить и другой факт: когда промежуточное
задание заключалось в обнаружении определенного слога (слога ТОН в ряду из слогов
ДОН и ТОН), степень 3абывания была на 44% выше, чем при обнаружении звука. Из
этого Рейтман сделала вывод, что "потолочный эффект" (в ее экспериментах, но,
вероятно, не в экспериментах Шифрина, который принимал более эффективные предосторожности)
и незаметное повторение (как в ее первоначальных опытах, так и у Шифрина) исказили
результаты, обратив их против гипотезы угасания, и что на самом деле забывание
из КП по крайней мере частично связано с угасанием следов.
Однако Рейтман вместе с тем отметила, что в ее эксперименте были получены данные,
указывающие на забывание в результате интерференции, в данном случае — интерференции,
связанной с выполнением задачи обнаружения определенного слога; она установила,
что забывание было в этих условиях более значительным, чем при обнаружении простого
звукового сигнала (тона). Шифрин тоже нашел, что арифметическая задача вызывает
забывание в тех случаях, когда задача обнаружения звукового сигнала не оказывает
такого действия. Хотя задания-дистракторы предназначались для того, чтобы предотвращать
повторение, не интерферируя с элементами, которые следовало запомнить, некоторые
из этих заданий, по-видимому, все же создавали интерференцию. И именно при таких
интерферирующих заданиях наблюдался наиболее высокий процент забывания.
В ряде экспериментов было показано, что задания-дистракторы действительно могут
создавать интерференцию. Сюда относятся эксперименты Рейтман и Шифрина, в которых
задания, требующие известных вербальных навыков (навыков оперирования словами
или слогами), чаще мешали удержанию в памяти вербального материала (слогов или
слов), чем невербальные задания, как, например, обнаружение сигнала. Уоткинс
и его сотрудники (Watkins а. о., 1973) показали, что трудные невербальные задания
также могут приводить к забыванию из КП. Они предъявляли испытуемым для запоминания
последовательности из пяти слов. Дистрактором служило задание, в котором испытуемый
прослушивал ряд звуков, производимых на рояле, и следил за ними, нажимая после
появления каждого звука на определенную кнопку. Это вызывало частичное забывание
пяти предъявленных слов в течение 20-секундного интервала удержания (рис. 6.7),
хотя и не такое значительное, как в экспериментах Петерсонов.
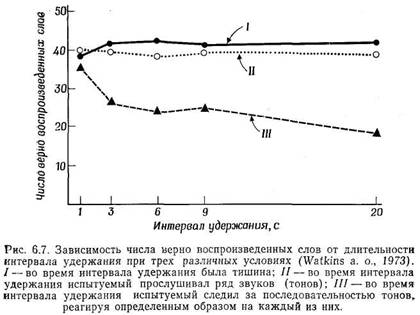
Уоткинс и его сотрудники высказали предположение, что степень забывания из
КП, обусловленного заданием-дистрактором, зависит от двух особенностей этого
задания. Один из них — степень его сходства с материалом, который следует помнить.
Предполагается, что интерференция обусловлена этим сходством: чем больше сходство,
тем сильнее интерферен-ция, ведущая к ослаблению следов в КП, и тогда информацию
уже не удается восстановить после интервала удержания. Описанные нами здесь
эксперименты (Peterson a. Peterson; Reitman; Shiffrin, Watkins а. о.), а также
другие, еще не рассмотренные данные подтверждают это. Уиклгрен (Wickelgren,
1965) нашел, что если материал, служащий дистрактором, и запоминаемый материал
сходны по звучанию, то степень забывания выше, чем в случае их несходства. Дейч
(Deutsch, 1970) обнаружил, что удерживать в памяти определенный набор тонов
во время прослушивания другого ряда тонов труднее, чем при прослушивании ряда
чисел. Все это позволяет думать, что дистракторы могут вступать в контакт и
интерферировать с подлежащим запоминанию материалом, находящимся в КП. Такое
представление, по-видимому, согласуется с идеей о том, что КП — это то место,
где производится какая-то "работа" (например, при выполнении задания-дистрактора).
Поскольку хранение этого материала также происходит в КП, вполне вероятно, что
два набора материала могут вступить в контакт и что этот контакт приводит к
интерференции, степень которой определяется сходством между тем и другим материалом.
Другой фактор, от которого, согласно Уоткинсу и сотр., зависит забывание из
КП, — это общая сложность задания дистрактора. Эти авторы считают, что в той
мере, в какой при выполнении задания-дистрактора используется емкость перерабатывающей
информацию системы (.или внимание в смысле известной емкости), это задание будет
создавать интерференцию. Примерами таких заданий служат: 1) слежение за рядом
тонов; 2) обратный счет; 3) задачи на сложение. Эту мысль подкрепляют результаты
других экспериментов, показавших, что степень трудности задания-дистрактора
действительно влияет на удержание материала в КП (см., например, Posner a. Konick,
1966; Posner a. Rossman, 1965). На основании данных Рейтман можно предполагать,
что один из механизмов интерференции при таких заданиях состоит в том, что они
мешают повторению и таким образом создают условия для угасания следов. Мы могли
бы также заметить, что это согласуется с представлением о КП как о месте не
только хранения, но и переработки информации. Следует ожидать, что для выполнения
более трудных задач понадобится рабочее пространство; это приведет к сокращению
пространства для такой работы, как повторение информации, а также для ее хранения
и тем самым к большему забыванию. С этим представлением согласуются также данные
Мердока (Murdock, 1961) о том, что на припоминание влияет количество информации,
подлежащей хранению. В эксперименте, в котором дистрактором служило задание
на обратный счет, Мердок наблюдал, что забывание происходило быстрее, когда
нужно было помнить триграмму из согласных или три слова, и медленнее, когда
это было одно слово. В первом случае материал содержал три структурные единицы
(и требовал больше места для хранения), а во второмтолько одну структурную единицу.
ВЛИЯНИЕ ПОЗНАВАТЕЛЬНЫХ ПРОЦЕССОВ НА ЗАБЫВАНИЕ
Если такие факторы, как характер работы, производимой во время интервала удержания,
количество запоминаемой информации н степень трудности промежуточной задачи,
влияют на сохранение материала в КП, то это снова подводит нас к уже знакомой
мысли. Эта мысль заключается в том, что в забывании из КП участвует познавательный
компонент, аналогичный тем факторам, которые регулируют избирательную переработку
входной информации и распознавание образов, а также процессы, подобные структурированию
и повторению. Эту мысль подкрепляют результаты исследований Вп и Нормана (Waugli
a. Norman, 1968), которые провели ряд дополнительных экспериментов с "цифрой-зондом".
Эти авторы обнаружили, что на забывание из КП влияет не только число элементов
в промежутке между предъявлением данного элемента и его контрольным воспроизведением,
но также и содержание этих элементов. Данные Во и Нормана показывают, что дело
не в общем числе промежуточных элементов, а в числе тех элементов, которые интерферируют
с подлежащим запоминанию материалом. Некоторые элементы не создают интерференции,
особенно те, которые могут быть .предсказаны в контексте данного эксперимента.
Для того чтобы убедиться в этом, посмотрим, что произойдет, если нам предъявят
ряд чисел, составленных из трех одинаковых цифр: 555, 666, 333 и т. д. Можно
ли каждое повторение цифры рассматривать как интерферирующий элемент? По чисто
интуитивным соображениям это кажется маловероятным: ведь нам достаточно просто
запомнить правило, что каждая цифр а повторяется трижды, вместо того чтобы запоминать
каждое повторение отдельно. Именно это и происходит на самом деле; Во и Норман
установили, что те элементы, которые можно предсказать, не интерферируют так,
как неожиданные элементы. И нам еще раз
приходится сделать вывод, что система, перерабатывающая информацию, не
пассивна, а содержит какой-то регуляторный механизм, связанный с
познавательными процессами.
На этом мы закончим рассмотрение процессов забывания из КП. Мы можем заключить,
что для объяснения всех имеющихся данных нужна теория, в которой нашлось бы
место как для пассивного угасания следов, так и для интерференции: угасание
происходит при отсутствии повторения; интерференцию можно создать, внеся новую
информацию или же выполняя какое-либо задание (работу) в то время, когда требуется
удерживать первоначально предъявленную информацию. Степень интерференции, создаваемой
данным заданием, по-видимому, варьирует в зависимости от его близости к материалу,
хранящемуся в КП, а также от той емкости КП, которую необходимо использовать
для его выполнения. Чем больше интерференция при данном задании, тем более значительное
забывание конкурирующего материала оно вызовет. И наконец, очень важно отметить,
что характер забывания определяется регуляторными процессами. От этих процессов
зависит, какая именно информация сохраняется в памяти, какая над ней производится
работа и происходит ли повторение; поэтому они играют важную роль и в определении
того, какая информация будет удерживаться в КП.
Глава 7
Кратковременная память: хранение информации в неакустической
форме
В гл. 2 мы рассмотрели общую модель системы переработки информации у человека.
По необходимости описание этой модели было упрощенным; одним из упрощений было
утверждение, что в КП информация кодируется в акустической (слуховой) форме,
а в ДП — в семантической форме. В конце главы мы отметили, что в нашем описании
КП был опущен ряд осложняющих моментов. В настоящей главе мы увидим, в чем состоят
некоторые из этих усложнений, и закончим рассмотрение КП и относящихся к ней
процессов.
Одна из самых важных проблем, связанных с нашим первым, упрощенным описанием
кратковременной памяти, состоит в том, что КП изображалась как хранилище элементов,
закодированных акустически. Конечно, большая часть оригинальных исследований
в этой области (например, "слуховые" ошибки, отмеченные Conrad, 1964) указывала
на то, что в КП информация хранится в акустической форме. Однако имеются также
данные в пользу зрительного и семантического кодирования элементов в КП. Например,
хотя в нашем первом описании КП предполагалось, что при зрительном предъявлении
буквы она для хранения в КП метится и кодируется акустачески (так, буква С превращается
в звук "ЭС"), некоторые данные говорят о том, что буква, предъявленная зрительно,
может быть закодирована в КП в зрительной же форме (т. е. С хранится в виде
фигуры "С"). В настоящей главе мы сосредоточим внимание на имеющихся данных
в пользу такого неакустического хранения информации.
Прежде чем начать рассмотрение неакустических кодов КП, следует уточнить, что
имеется в виду, когда. говорят о зрительном или семантическом представлении
информации в КП. Мы произвольно определили КП как то место, где хранятся
вербальные описания тех или иных элементов (т. е. слогов или слов) в акустической
форме; но само это определение исключает возможность зрительного или семантического
кодирования в КП. Поэтому для того, чтобы изучить характер хранящейся в КП информации,
мы должны теперь дать определение КП, независимое от кода того или иного типа.
Для такого определения может быть использован признак длительности хранения
информации. Мы могли бы оказать, что кратковременная память — это хранилище,
в котором элементы удерживаются в течение короткого времени — порядка нескольких
секунд, если не происходит повторения. Мы могли бы также сказать, что в КП может
храниться информация, поступающая от органов чувств (или сенсорных регистров)
или же из долговременной памяти. При таком определении КП хранящуюся в ней информацию
можно рассматривать в любой форме. Однако при этом особенно важно будет тровасти
границу между сенсорными регистрами и КП, так как в сенсорных регистрах информация
тоже хранится в течение короткого времени. Поэтому нужно ввести еще одну характеристику.
Мы можем сказать, что элементы, поступающие в КП из сенсорных регистров, не
содержатся в ней в виде необработанной сенсорной информации, а уже
прошли через решающий этап распознавания образов, в процессе которого они вступают
в контакт с соответствующим представлением в ДП. Эти элементы уже перестали
быть прекатегориальными. Поэтому нам хотелось бы рассмотреть данные, указывающие
на возможность кратковременного хранения информации в несенсорной форме — в
виде неакустического (а именно зрительного или семантического) кода.
ЗРИТЕЛЬНЫЕ КОДЫ В КРАТКОВРЕМЕННОЙ ПАМЯТИ
Из неакустических несенсорных кодов кратковременной памяти мы рассмотрим сначала
зрительные коды. В частности, мы обсудим данные в пользу того, что зрительная
информация может некоторое время сохраняться и после исчезнjвения стимула, хотя
эта информация, по-видимому, уже не находится в сенсорном регистре. Мы обсудим
также данные о возможности извлечения из ДП на короткое время хранящейся в ней
информации, закодированной в зрительной форме. Таким образом, нам нужно будет
рассмотреть результаты исследований, подтверждающие возможность хранения информации
в зрительной форме — хранения, обладающего такими же характеристиками, что и
акустическое хранение, на которое было направлено главное внимание в предшествующем
анализе КП.
ЭКСПЕРИМЕНТЫ ПОЗНЕРА ПО СРАВНЕНИЮ БУКВ
Одна группа данных, говорящих о существовании зрительного кодирования в КП,
получена с помощью метода, разработанного Познером (Posner, 1969; Posner a.
o" 1969; Posner a. Mitchell, 1967). Исследававия Познера дают веские основания
полагать, что: 1) после воздействия зрительного стимула зрительная информация
может сохраняться в условиях, несовместимых с иконическим хранением; 2) зрительная
информация может также поступать на короткое время из ДП. Основной метод Познера
состоит в следующем (рис. 7.1). Испытуемый участвует в длинном ряде шроб, каждая
из которых продолжается очень недолго. В каждой пробе испытуемому предъявляют
две буквы. Он должен сообщить, имеют ли эти буквы одинаковые названия (например,
А и А или Б и б) или разные (например, А и Б); испытуемый делает это, нажимая
на одну из находящихся перед ним кнопок.
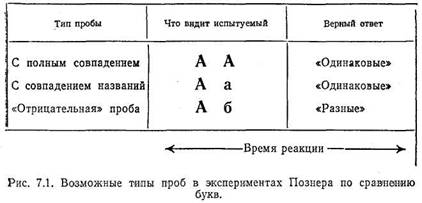
Совершенно очевидно, что это задание — в отличие от большинства рассмотренных
прежде испытуемый может выполнить без всяких ошибок. Поэтому экспериментатора
в данном случае не могут удовлетворить такие данные, как просто процент верных
и неверных ответов. Зависимой переменной здесь будет время реакции (ВР) испытуемого
— время, необходимое ему для того, чтобы после предъявления букв дать ответ
— "одинаковые" или "разные". Точнее, ВР — это время между появлением букв и
ответом испытуемого.
Теоретически эта величина показывает, сколько требуется времени для соответствующих
внутренних процессов. В задании Познера в ВР входит время, необходимое испытуемому
для того, чтобы зрительно воспринять букы, сопоставить их друг с другом, решить,
одинаковые они или разные, и нажать нужную кнопку. ВР будет больше или меньше
в за.висимости от того, сколько времени понадобится испытуемому для выполнения
этих действий. Однако использование ВР в экспериментальной психологии не ограничивается
задачами такого типа. Этот показатель имеет давнюю историю. Познер заимствовал
его из работы Дондерса (Bonders, 1862), который предложил "метод вычитания"
для использования ВР при изучении психических процессов. Этот метод очень прост.
Допустим, что у нас есть два задания, Х и Y, и что в заданиеY целиком входит
все задание Х плюс еще некоторый компонент Q (т. е. Y=X+Q). Тогда, измерив ВР
для выполнения заданий Х и Y, можно вычесть ВР для Х из ВР для Y и получить
время, необходимое для выполнения компонента Q. Таким способом можно исследовать
природу Q, даже если этот компонент нельзя непосредственно наблюдать в отдельности.
В более общей форме: используя время реакции, можно выделять отдельные компоненты
заданий и исследовать некоторые свойства психических процессов.
Вернемся к экспериментам Познера. Как видно из рис. 7.1, существуют две ситуации,
в которых испытуемый ответит "одинаковые". Он даст такой ответ, если две предъявленные
буквы идентичны (например, А и А); мы будем называть это "полным совпадением".
И он опять-таки ответит "одинаковые", если буквы не идентичны, но имеют одно
и то же название (как А и а); это будет "совпадение названий". В остальных случаях
испытуемый будет отвечать "разные". (Ответы "одинаковые" и "разные" называют
также положительными и отрицательными соответственно.) Как правило, для этих
трех ситуаций — с полным совпадением, с совпадением названий и с разными буквами-величины
ВР различны. В случае полного совпадения испытуемый обычно отвечает на 0,1 с
быстрее (в экспериментах с ВР это очень большая величина), чем в случае совпадения
названий или отрицательного ответа. Это позволяет предполагать, что во внутренних
процессах, связанных с выполнением таких задач, есть какие-то различия.
Чтобы выяснить, в чем состоят эти различия, следует разбить выполняемую задачу
на отдельные компоненты, каждый из которых занимает часть всего затрачиваемого
времени. Таким способом мы пытаемся выделить тот компонеит или те компоненты,
которые занимают дополнительное время в вариантах, отличных от случая полного
совпадения. Мы могли бы предположительно расчленить задачу следующим образом:
сначала испытуемый воспринимает буквы (зрительно кодирует их); затем он должен
назвать их; после этого он решает, имеют ли они одинаковые или разные названия,
и наконец, он дает ответ, нажимая на кнопку. Эти операции занимают все время
— от начала предъявления букв до ответа. Нет достаточных оснований предполагать,
что время, необходимое для восприятия букв, в разных случаях различно; точно
так же вряд ли может варьировать и время, затрачиваемое на нажатие кнопки. Скорее
всего различия в ВР зависят от времени, необходимого для процессов называния
и сравнения. Когда буквы идентичны, на выполнение этих процессов, вероятно,
уходит меньше времени, чем если буквы отличаются друг от друга.
По мнению Познера, различия в ВР обусловлены тем, что в случае двух идентичных
букв нет нужды называть их. Он полагает, что идентичность их замечается сразу
же при зрительном восприятии их физической формы. Только тогда, когда буквы
не идентичны, возникает необходимость дать им названия и сопоставить эти названия.
Короче говоря, в случаях полного совпадения (А, А) задача сводится к восприятию
и зрительному кодированию, сравнению физических образов и даче ответа; в случае
же совпадения названий (А, а) или отрицательного ответа (А, Б) она включает
восприятие и зрительное кодирование, вербальное кодирование (называние), сравнение
названий и дачу ответа. При совпадении названий ответная реакция — ввиду большего
числа входящих в нее компонентов — должна занимать больше времени, что я приводит
к наблюдаемым различиям ВР. Короче говоря, сопоставление в случаях полного совпадения
основано, по мнению Познера, на зрительной информации, а в случаях совпадения
названий — на словесных кодах (рис. 7.2).
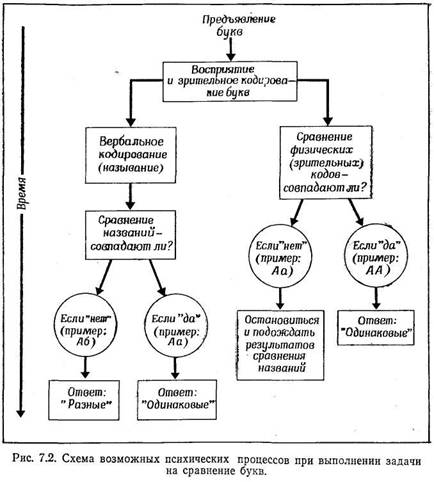
Считая, что в случае полного совпадения сопоставляется зрительная информация,
мы тем самым подразумеваем наличие этой информации. Последнее не вызывает сомнений,
если две буквы предъявляются одновременно и остаются на виду до тех пор, пока
испытуемый не даст ответа, — именно такой случай мы и рассматриваем. Нам, однако,
нужны доказательства того, что зрительная информация остается в памяти
и после, исчезновения стимула. Более того, мы хотим показать, что эта информация
содержится не в иконическом образе, а за его пределами, т. е. в КП.
Для того чтобы показать наличие в памяти такой зрительной информации, задачу
Познера можно видоизменить, предъявляя две буквы не одновременно, а последовательно.
Типичная проба будет состоять в следующем: сначала появляется первая буква,
примерно на полсекунды, затем следует межстимульный интервал, на протяжении
которого испытуемый видит пустое поле, после чего появляется вторая буква. Испытуемый,
как и в прежнем варианте, должен указать, "одинаковы" или "различны" две предъявленные
ему буквы. Время реакции определяют в этом случае как промежуток между появлением
второй буквы и ответом испытуемого.
В этой задаче первая буква должна еще оставаться в памяти испытуемого, когда
он сообщает свой ответ, так как она исчезла с экрана перед межстимульным интервалом.
Для сопоставления двух букв должна использоваться информация, находящаяся в
памяти. Есть ли доказательства того, что при этом используется именно зрительная
информация? Иначе говоря, наблюдается ли в этом варианте опыта сокращение ВР
совпадение названий при полном совпадении по сравнению со случаем совпадения
названий? На это следует ответить утвердительно, по крайней мере для некоторых
условий. Если межстимульный интервал меньше 1 с, то сопоставления три полном
савпадении занимают меньше В1ремени, но если он приближается к 2 с, различия
в ВР исчезают (рис. 7.3). Рассуждая таким же образом, как и прежде, можно заключить,
что если ВР при полном совпадении меньше, чем при совпадении названий, то для
установления полной идентичности букв используется зрительная информация. Поскольку,
однако, первая буква в момент сопоставления физически отсутствует, соответствующая
зрительная информация должна, очевидно, находиться в мозгу. Таким образом, мы
имеем доказательство того, что зрительная информация относительно первой буквы
сохраняется в течение примерно 2 с после исчезновения этой буквы. Постепенное
исчезновение различия во времени реакции по мере удлинения межстимульного интервала
можно объяснить постепенным угасанием в памяти зрительного следа первой буквы.
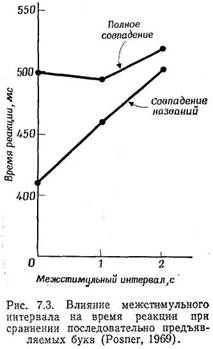
Итак, мы теперь располагаем данными о том, что зрительная информация может
некоторое время сохраняться в памяти после исчезновения стимула. Остается, правда,
важный вопрос: откуда нам известно, что зрительная информация находится в КП,
а не в иконической памяти? Ведь описанные здесь эксперименты не позволяют утверждать,
что в сопоставлении двух идентичных букв не используется иконическая информация.
Есть, однако, данные, указывающие на то, что используемые при этом следы находятся
не в сенсорном регистре и что их скорее следовало бы отнести к "кратковременной"
памяти (в соответствии с критериями, которые мы установили в начале главы).
Один из доводов в пользу несенсорной природы этих зрительных следов состоит
в том, что они, по-видимому, сохраняются даже после исчезновения иконического
образа (Posner a. о., 1969). Предположим, например, что в интервале между двумя
буквами (предъявляют какое-то маскирующее поле — скажем, произвольный черно-белый
узор. Следовало бы ожидать, что этот узор сотрет иконический образ первой буквы.
В таком опыте полное совпадение все еще выявляется испытуемым быстрее, чем совпадение
названий (хотя в обоих случаях затрачивается больше времени, чем при "пустом"
межстимульном интервале). Таким образом, зрительная информация о первой букве,
по-видимому, сохраняется даже после предъявления маскирующего поля, а это означает,
что она хранится не в сенсорном регистре, а в каком-то ином месте.
Другим указанием на то, что обсуждаемая нами зрительная память не является
сенсорной, служат данные о возможности "заимствовать" соответствующий образ
из ДП. Опишем результаты одного из таких экспериментов (Posner а.о., 1969).
Вместо зрительного предъявления первой буквы испытуемому говорят: "Это заглавное
А". Затем следует "пустой" интервал, после чего предъявляется либо заглавное
А, либо какая-нибудь другая буква. При таких условиях время реакции для положительных
ответов (когда вторая буква соответствует объявленной) сравнимо с ВР для случаев
полного совпадения (в обычных условиях, т. е. при зрительном предъявлении обеих
букв) при межстимульном интервале порядка 1 с и более. При интервале менее 1
с полное совпадение выявляется испытуемым несколько быстрее. Эти результаты
позволяют предполагать, что испытуемый использует вербальное предъявление для
того, чтобы создать внутренний зрительный образ объявленной буквы (с помощью
правил, описывающих соответствие между звучанием и видом букв). После появления
второй буквы он сравнивает с ней этот созданный им внутренний образ. Если испытуемый
располагает по меньшей мере одной секундой для построения этого внутреннего
образа, то этот образ сравним с тем, что имелось бы при зрительном предъявлении
первой буквы. Если же времени слишком мало (меньше 1 с), получается образ "худшего
качества", чем след буквы, предъявленной зрительно. Как мы видим, испытуемый,
вероятно, может создавать зрительное представление в соответствии с содержащимися
в ДП правилами или может удерживать в памяти подобный же образ после фактического
предъявления стимула. Это служит веским доводом в пользу того, что зрительный
образ, сохраняющийся после исчезновения стимула, не является иконическим следом,
поскольку такого рода образ может быть извлечен из ДП, а не только получен непосредственно
через органы чувств.
ЭКСПЕРИМЕНТЫ С "МЫСЛЕННЫМИ ПОВОРОТАМИ"
Представление, которое испытуемый создает, пользуясь информацией из ДП, сходно
с тем, которое может возникнуть при попытке зрительно перебрать в уме буквы
алфавита. Дополнительные сведения о таких представлениях были получены в работах
Роджера Шепарда, Линн Купер и их сотрудников (Cooper a. Shepard, 1973; Shepard
a. Metzier, 1971). Эти авторы занимались исследованием так называемых мысленных
поворотов — поворотов зрительных образов, подобных тем, которые мы рассматривали.
Они давали испытуемым задания, сходные с познеровскими. В одном из экспериментов
испытуемые должны были нажимать на одну кнопку при предъявлении буквы и на другую
— при предъявлении зеркального отображения этой буквы. Особенно интересно то,
что стимул мог быть повернут в своей собственной плоскости. Так, например, 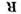 нужно было опознать как "нормальную" букву (какой она и будет, если ее правильно
повернуть), а
нужно было опознать как "нормальную" букву (какой она и будет, если ее правильно
повернуть), а 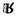 — как ее зеркальное отображение. Угол поворота
относительно нормального положения варьировал в пределах от 0 до 360o.
Шепард я его сотрудники установили, что ВР, необходимое для правильного ответа,
находилось в прямой зависимости от степени поворота буквы (рис. 7.4). По мере
ее вращения от 0 до 180o ВР возрастало; при дальнейшем вращении от
180 до 360o (что соответствует поворотам от 180 до 0o
в обратную сторону) оно постепенно уменьшалось. Характер изменения ВР позволяет
предполагать, что испытуемый мысленно поворачивал букву, приводя ее в нормальное
положение (по часовой стрелке или против часовой стрелки, смотря по тому, какой
путь короче, например — как ее зеркальное отображение. Угол поворота
относительно нормального положения варьировал в пределах от 0 до 360o.
Шепард я его сотрудники установили, что ВР, необходимое для правильного ответа,
находилось в прямой зависимости от степени поворота буквы (рис. 7.4). По мере
ее вращения от 0 до 180o ВР возрастало; при дальнейшем вращении от
180 до 360o (что соответствует поворотам от 180 до 0o
в обратную сторону) оно постепенно уменьшалось. Характер изменения ВР позволяет
предполагать, что испытуемый мысленно поворачивал букву, приводя ее в нормальное
положение (по часовой стрелке или против часовой стрелки, смотря по тому, какой
путь короче, например 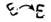 ), а затем на основании полученного
зрительного образа решал, обычная это буква или "зеркальная". Каждый лишний
градус, на который приходилось поворачивать стимул, увеличивал время реакции,
что и приводило к постепенному возрастанию этого времени с увеличением угла
поворота. Таким образом, судя по этим результатам, испытуемые способны производить
поворот какого-то мысленного отображения стимула — своего рода кратковременного
зрительного кода. Мы можем также кое-что заключить относительно природы этого
зрительного кода: во всяком случае, он должен быть таким, чтобы его можно было
поворачивать, а это означает, что кодне просто перечень тризна ков. Как можно
было бы повернуть перечень признаков? Как можно было бы, поворачивая какойлибо
перечень, вызвать такое закономерное изменение вpeмeни реакции? Шепард и его
сотрудники полагают, что зрительный код должен быть более или менее прямым отображением
первоначального стимула. ), а затем на основании полученного
зрительного образа решал, обычная это буква или "зеркальная". Каждый лишний
градус, на который приходилось поворачивать стимул, увеличивал время реакции,
что и приводило к постепенному возрастанию этого времени с увеличением угла
поворота. Таким образом, судя по этим результатам, испытуемые способны производить
поворот какого-то мысленного отображения стимула — своего рода кратковременного
зрительного кода. Мы можем также кое-что заключить относительно природы этого
зрительного кода: во всяком случае, он должен быть таким, чтобы его можно было
поворачивать, а это означает, что кодне просто перечень тризна ков. Как можно
было бы повернуть перечень признаков? Как можно было бы, поворачивая какойлибо
перечень, вызвать такое закономерное изменение вpeмeни реакции? Шепард и его
сотрудники полагают, что зрительный код должен быть более или менее прямым отображением
первоначального стимула.
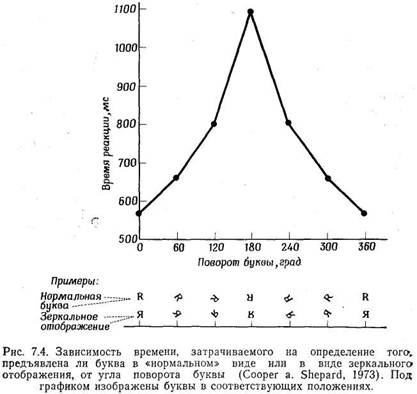
Многие другие эксперименты, шроведенные в последнее время, тоже говорят в пользу
того, что код КП не обязательно должен быть акустическим: возможно существование
таких зрительных представлений (создаваемых с помощью информации из ДП или прямо
отображающих внешний стимул), которые сохраняются в КП несколько секунд или
же до тех пор, пока над ними производится какая-то "работа". Подобных исследований
так много, что рассмотреть их все здесь не представляется возможным. Однако,
прежде чем закончить обсуждение зрительной КП, мы ознакомимся еще с одной группой
экспериментов, имеющих отношение к гипотезе о существовании зрительных кодов.
Эти эксперименты не были предназначены для изучения зрительной КП. Их автора,
Саула Стернберга, интересовала в первую очередь проблема извлечения информации
из кратковременной памяти.
СКАНИРОВАНИЕ ПАМЯТИ И ЗРИТЕЛЬНАЯ КП
Свой основной эксперимент Стернберг (Sternberg, 1966) поставил с целью изучить,
каким образом происходит извлечение информации из КП: воспринимается ли она
целиком, сканируется или считывается? Может ли вся информация обследоваться
одновременно — с помощью какого-то процесса параллельного сканирования? Или
же сканирование производится последовательно, так что каждый элемент или структурная
единица прочитывается одна за другой? Для выяснения этого и других вопросов
Стернберг разработал следующую задачу. Каждый испытуемый участвовал в ряде проб,
и в каждой пробе ему сначала предъявляли "стандартный набор", например от одной
до пяти цифр (примером набора из четырех цифр может служить "2, 4, 7, 3"). Число
элементов в наборе было меньше объема КП, и испытуемого просили запомнить их.
Затем ему предъявляли "контрольный стимул" — одну цифру, которая могла входить
или не входить в исходный набор. Испытуемый должен был ответить "да", если контрольный
стимул соответствовал одному из элементов стандартного набора, и "нет", если
он не соответствовал ни одному из них. Так же как и в экспериментах Познера,
испытуемые могли выполнять это задание с очень небольшим числом ошибок, поэтому
измеряемой переменной было время реакции (ВР). В данном случае ВР определялось
как промежуток времени между предъявлением контрольного стимула и ответом испытуемого
(обычно состоявшем в нажатии на кнопку, рис. 7.5, A).
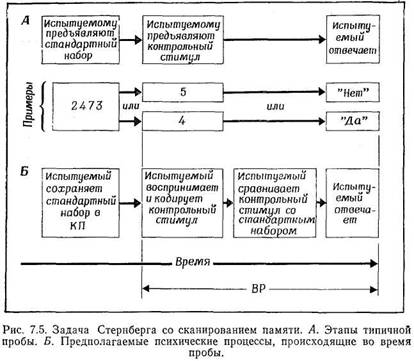
Какого рода переработка информации происходит в этот короткий период? Задачу
можно предположительно расчленить на отдельные компоненты того же типа, что
и в экспериментах Познера (рис. 7.5, Б). Мы исходим из того, что при появлении
контрольного стимула в КП испытуемого содержится стандартный набор элементов.
Будем считать, что последующая переработка состоит из трех этапов. Сначала испытуемый
воспринимает и кодирует контрольный стимул — переводит его в какую-либо внутреннюю
форму; затем он сравнивает этот стимул с элементами стандартного набора и, наконец,
на основании этих сравнений дает ответ. Суммарное время, затрачиваемое на все
эти этапы, представляет собой ВР данного испытуемого.
Стернберга особенно интересовали изменения ВР, связанные с изменением величины
стандартного набора, т. е. числа элементов в этом наборе. Из таких изменений
ВР можно кое-что заключить относительно процесса сравнения, производимого испытуемым
на втором этапе выполнения задачи. Что произойдет, если увеличить стандартный
набор на одну цифру? Испытуемому придется произвести больше сравнений, так как
он должен сравнивать контрольный стимул с каждым элементом стандартного набора.
Изменение ВР при добавлении одной цифры должно быть различным в зависимости
от того, каким способом испытуемый выполняет задание; поэтому, выяснив, как
изменяется ВР, мы сможем судить о том, как он перерабатывает предъявленную информацию.
Допустим, например, что у нас имеется простая гипотеза о параллельном
процессе сравнения в КП — о том, что испытуемый обладает неограниченными возможностями
переработки информации и может обследовать сразу все, что содержится в КП, затрачивая
на это не больше усилий, чем было бы нужно для просмотра лишь некоторой части
содержимого КП. Эта гипотеза позволяет нам сделать определенные предсказания
относительно изменений ВР. В частности, мы можем ожидать, что добавление одной
цифры к стандартному набору не окажет на ВР никакого влияния. Содержит ли память
2, 3 или 4 элемента — ВР для данного задания варьировать не будет, так как испытуемый
затрачивает на сравнение нескольких элементов с контрольным стимулом не больше
времени, чем на сравнение одного элемента. Это предсказание иллюстрирует рис.
7.6, А, на котором представлен график зависимости ВР от числа элементов в стандартном
наборе.
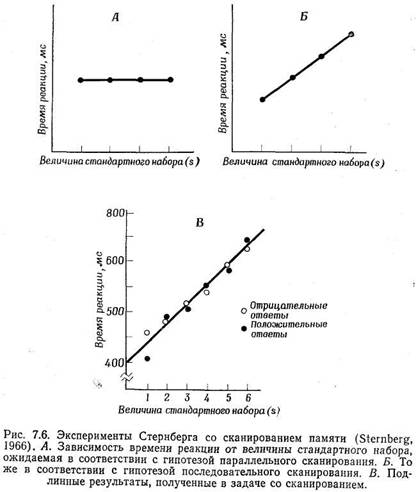
Согласно другой возможной гипотезе, задача решается путем последовательного
сканирования — испытуемый может сравнивать стимул одновременно лишь с одним
из элементов стандартного набора. В этом случае каждый элемент, добавляемый
к набору, будет удлинять время, необходимое для выполнения задачи. Соответственно
будет увеличиваться ВР, причем степень этого увеличения будет зависеть от того,
сколько времени требуется для сравнения еще одной цифры с контрольным стимулом.
Следует ожидать, что при этом получится график, подобный представленному на
рис. 7.6, Б.
Рассмотрим эту гипотезу последовательного сканирования более подробно. Мы предположили,
что процесс выполнения испытуемым задания состоит из трех этапов, каждый из
которых занимает какую-то часть всего затрачиваемого времени. Допустим, что
испытуемый затрачивает е миллисекунд на то, чтобы закодировать контрольный
стимул, с миллисекунд на сравнение одного элемента стандартного набора
с этим стимулом и r миллисекунд на третий этап (дачу ответа). Если
стандартный набор состоит только из одного элемента, испытуемый сможет выполнить
задание за е+с+r миллисекунд — это и будет его ВР. Допустим теперь,
что в стандартном наборе 5 элементов и ни один из них не соответствует контрольному
стимулу. Испытуемый даст в этом случае отрицательный ответ, и его ВР составит
e+с+с+с+с+с+r миллисекунд. В общем случае время, затрачиваемое испытуемым
на то, чтобы дать в аналогичной ситуации отрицательный ответ, будет равно e+sXc+r,
где s-число элементов в стандартном наборе. Если построить график зависимости
ВР от s, получится прямая линия. Ее можно описать уравнением, BP=(e+r)+(sXc).
Таким образом, наклон этой линии будет равен с. Иными словами, если
бы какой-нибудь испытуемый выполнял это задание и мы построили бы график зависимости
его ВР при отрицательных ответах от величины стандартного набора, то получилась
бы прямая линия. Наклон этой прямой теоретически будет соответствовать тому
времени (с), которое испытуемый затрачивает на одно сравнение. ВР при
s=0 — это время, необходимое для того, чтобы закодировать стимул (е)
и дать ответ (r).
Читателю может показаться странным, что мы сосредоточили все внимание на отрицательных
ответах. Это связано с тем, что отрицательный ответ может быть дан лишь после
того, как испытуемый сопоставит с контрольным стимулом все элементы стандартного
набора; иначе как бы он мог выяснить, что контрольного стимула в этом наборе
не было? В случае же положительных ответов картина осложняется, так как испытуемый
может прекратить сравнение, обнаружив соответствие одного из элементов стандартного
набора контрольному элементу. Он не обязательно произведет все возможные сравнения.
Это так называемая гипотеза "самопрекращения": в ней предполагается, что испытуемый
прекращает сканирование, как только он найдет элемент, соответствующий контрольному
стимулу. Можно выдвинуть и другое предположение, называемое гипотезой "полного
просмотра". Согласно этой гипотезе, испытуемый независимо от того, обнаружил
он соответствующий элемент или нет, "просматривает" на стадии сравнения весь
стандартный набор. Он не прекращает сопоставление, а доводит его до конца. Эта
последняя гипотеза интуитивно кажется необоснованной, но тем не менее ее следует
проверить.
Решающим критерием при выборе между гипотезами "самопрекращения" и "полного
просмотра" служит угол наклона функции ВР (графика зависимости ВР от величины
стандартного набора) для положительных ответов. Когда испытуемый обнаруживает
соответствие между контрольным стимулом и одним из элементов стандартного набора,
в среднем это происходит после просмотра половины набора. В соответствии с гипотезой
самопрекращения это означало бы, что
в тех случаях, когда ответ положительный, испытуемый прекратит сканирование,
дойдя (в среднем) до середины набора, а в случае отрицательного ответа будет
доводить этот процесс до конца. Если испытуемый сам прекращает сканирование,
то при положительном ответе он производит в среднем (s+1)/2 сравнений. Его ВР
при положительных ответах составит e+r+[(s+1)/2]Xc. Если преобразовать эту формулу
так, чтобы представить ВР как функцию 5 (при этом получим ВР=(е+r+с/2)+[(с/2)s]),
то окажется, что наклон графика для положительных ответов вдвое меньше, чем
для отрицательных (с/2 для положительных и с-для отрицательных) . В отличие
от этого гипотеза полного просмотра утверждает, что этап сравнения при положительных
и отрицательных ответах одинаков — в обоих случаях производятся все возможные
сравнения — и поэтому такого различия в наклоне графика не должно быть (в обоих
случаях наклоны будут равны с).
Теперь у нас имеется три гипотезы. Одна из них — это гипотеза параллельного
сканирования, которая предсказывает, что зависимость ВР от s будет
выражаться горизонтальной прямой как для положительных, так и для отрицательных
ответов (рис. 7.6, А). Две другие гипотезы-это варианты гипотезы последовательного
сканирования, согласно которой сравнения производятся то одному, а ВР возрастает
с увеличением числа элементов в стандартном наборе (рис. 7.6, Б). В одном из
вариантов предполагается, что сканированиепроцесс самопрекращающийся. В этом
случае наклон графика для положительных ответов будет вдвое меньше, чем:, для
отрицательных. Согласно другому варианту, сканирование носит исчерпывающий характер
и никакого различия между графиками для положительных и отрицательных ответов
быть не должно.
Для того чтобы установить, насколько обоснованны эти гипотезы, мы должны провести
эксперимент. Нужно собрать данные о величине .ВР для нескольких испытуемых,
каждый из которых проделал по многу проб. Среди проб должны, быть как положительные,
так и отрицательные, и проводиться они должны при нескольких различных размерах
стандартного набора. Затем следует вывести среднее время реакции для проб каждого
типа-положительных и отрицательныхи для каждого из стандартных наборов. После
этого нужно построить графики зависимости ВР от s. Именно это проделал Стернберг,
и полученные им результаты представлены на рис. 7.6, В. Из всего сказанного
выше следует, что его: данные говорят в пользу гипотезы последовательного исчерпывающего
сканирования. То обстоятельство, что результаты Стернберга подтверждают эту
гипотезу, представляет особый интерес, поскольку, как мы заметили, гипотеза
полного просмотра противоречит нашим интуитивным ожиданиям. Напомним, что, согласно
этой гипотезе, испытуемый независимо от того, обнаружил ли он соответствие одного
из элементов стандартного набора контрольному стимулу или нет, всегда сравнивает
с этим стимулом все элементы стандартного набора. Он не прекращает сравнений,
если обнаружит соответствие. А это, казалось бы, означает, что в случае положительного
ответа, т. е. при нахождении соответствия, испытуемый производит много ненужных
сравнений.
Тем не менее исчерпывающему сканированию можно найти объяснение. Для этого
прежде всего разделим происходящий при сканировании процесс сравнения на два
компонента. Один из них — это акт сравнения как таковой, другой — принятие
решения относительно результатов сравнения. Если при сравнении обнаружилось
соответствие между одним из элементов стандартного набора и контрольным стимулом,
то решение будет положительным, ведущим к положительному ответу. В противном
случае ответ будет отрицательным.
Посмотрим теперь, что произойдет, если время, которым располагает испытуемый
для сравнения контрольного стимула с элементами стандартного набора, будет очень
коротким, а время, в течение которого он должен решить, привело ли это сравнение
к положительному результату, относительно более долгим. В случае самопрекращающегося
процесса его продвижение по стандартному набору можно было бы представить следующим
образом: сравни, решай, сравни, решай и т. д. до тех пор, пока не будет обнаружено
соответствие (принято решение "да") или пока не будет исчерпан стандартный набор.
Исчерпывающий же процесс будет иметь вид: сравни, сравни, сравни и т. д., а
затем — когда стандартный набор будет исчерпан — решай. Если принятие решения
занимает намного больше времени, чем сравнение, то нетрудно понять, что исчерпывающее
сканирование может оказаться более выгодным: оно требует только однократного
принятия решения. Таким образом, исчерпывающее сканирование будет более эффективным
в том случае, если испытуемый может производить сравнения очень быстро-так быстро,
что ему было бы трудно останавливаться для того, чтобы принимать решения. Вместо
этого испытуемый "проносится пулей" по всему набору и только после этого принимает
решение и дает ответ.
Если такое объяснение исчерпывающего сканирования верно, то сравнение должно
занимать очень мало времени. Это можно проверить по данным о ВР, вычислив наклон
графика зависимости ВР от величины стандартного набора; теоретически этот наклон
соответствует времени, которое нужно затратить на сравнение контрольного стимула
с одним элементом стандартного набора. Подсчет показывает, что фактические данные
подтверждают предположение об очень быстром сравнении. Из данных, представленных
на лис. 7.6, В, можно заключить, что наша переменная с, определяющая наклон
графика ВР для отрицательных ответов, равна примерно 35 мс (0,035 с). Отсюда
следует, что испытуемый затрачивает 0,035 с на сравнение контрольного стимула
с одним элементом стандартного набора. Из этого нетрудно вычислить, что испытуемый
может произвести около 30 таких сравнений за одну секунду. Удивительно быстро!
Это открытие возвращает нас к основной теме настоящей главы. Выведенная скорость
сопоставления позволяет думать, что сравнения производятся не на основе словесных
меток, представленных в КП акустически. Стернберг (Sternberg, 1966) мог утверждать
это, исходя из того, что он знал (и что известно также и нам) об относительно
малой скорости внутренней речи. Измерения этой скорости, так же как и скорости
внешней речи (см. гл. 5), дают основания предполагать, что испытуемый может
акустически повторять всеголишь около шести элементов в секунду. Если бы в задаче
Стернберга сравнения производились на основе акустических кодов (и стимулы внутренне
"проговаривались"), то нельзя" было бы ожидать более шести сопоставлений в секунду.
При этом наклон графика ВР соответствовал бы примерно170 мс, тогда как фактически
наблюдаемый наклон соответствует 35 мс. Поэтому сопоставления вряд ли могут
быть акустическими.
В связи с этим Стернберг (Sternberg, 1967) высказал предположение, что сравниваются
не акустические, а зрительные коды и что сравнения на зрительной основе производятся
быстрее, чем вербальные сопоставления. (Здесь следует отметить, что это, казалось
бы, противоречит нашему прежнему предположению о том, что зрительное повторениепроизводится
медленнее, чем вербальное. Однако при вербальном повторении буквы извлекались
из ДП, при зрительном же повторении они, очевидно, уже содержатся в КП к началу
процесса сканирования и наклон графика отражаеттолько время, затрачиваемое на
сравнения.) Как мы увидим, получен ряд данных, подтверждающих мысль о том, что
при выполнении задачи Стернберга происходит переработка зрительных представлений.
Для того чтобы проверить предположение о том, что при сканировании памяти используются
зрительные коды, Стернберг (Sternberg, 1967) предъявлял контрольный стимул то
в частично замаскированной, то в "нормальной" форме. Для маскировки на контрольный
стимул накладывали узор в видешахматной доски. При построении графика за1висимости
ВР от величины стандартного набора оказалось, что точка пересечения этой функции
с осью ординат для замаскированного стимула находится выше, чем для нормального.
Это можно объяснить тем, что восприятие и кодирование стимула, замаскированного
шахматным рисунком, занимает больше времени (возрастает компонента е суммарного
ВР). Однако более существенно то, что при этом возрастал также наклон
графика (который, как мы считаем, соответствует времени, затрачиваемому на сравнение).
Последний эффект был, правда, выражен слабо, и у хорошо натренированных испытуемых
не было различия в наклоне графика при двух вариантах стимула.
Стернберг интерпретировал эти результаты следующим образом. Поскольку частичная
маскировка контрольного стимула оказывала некоторое влияние на наклон графика,
можно думать, что для сравнения используется зрительный код: ведь если бы стимул
перекодировался в вербальную форму (т. е. если бы испытуемый воспринимал стимул,
называл его, а затем сравнивал данное название с элементами стандартного набора),
то маскировка стимула могла бы затруднить его восприятие и называние, но не
сказалась бы на использовании этого названия в последующих сравнениях. Таким
образом, время сравнения не должно было измениться, а потому не изменился бы
и наклон графика. Факт изменения наклона говорит о том, что сравнивались не
названия, а зрительные образы. Однако у хорошо натренированных испытуемых наклон
графика изменялся очень мало. Это указывает на то, что для сравнения использовались
не первичные сенсорные образы. Маскировка контрольного стимула приводила к резкому
искажению сенсорного образа, и его использование для сравнения сильно увеличивало
бы время сравнения. А между тем наклон графика, отражающий это время, изменялся
незначительно; значит, со стандартным набором сравнивался, видимо, не сенсорный
образ. Короче говоря, можно думать, что код стимула, используемый в задаче Стернберга,
является зрительным, но не сенсорным, т. е.-по принятой нами терминологии —
это зрительный код кратковременной памяти.
В другом эксперименте Клифтон и Тэш (Clifton a. Tash, 1937) использовали варианты
задачи Стернберга, в которых элементами стандартного набора были буквы, трехсложные
слова из 6 букв (например, POLICY) или односложные слова из 6 букв (например,
STREET). Для стимулов каждого типа они вычисляли наклон графика ВР. Оказалось,
что все наклоны были примерно одинаковы. Из этого мы можем заключить, что число
слогов в элементах стандартного набора и в контрольном стимуле не влияет на
время, необходимое для сравнения. Однако это означает, что скорость сравнения
не зависела от того, сколько времени требовалось бы для произнесения названий
элементов, — результат, который показался бы абсурдным, если бы для сравнения
использовались акустические коды. Вместе с тем отсутствие различия в наклонах
указывает также на то, что и зрительно воспринимаемая длина элемента не влияла
на скорость сравнения. Значит, если сравнивались зрительные образы, то они,
вероятно, были очень далеки от сенсорного уровня, на котором зрительно воспринимаемые
размеры скорее всего оказывали бы влияние на ВР. Этот эксперимент, таким образом,
наводит на мысль, что в основе сравнений в задаче Стернберга лежат несенсорные
неакустические коды, хотя из полученных результатов не ясно, являются ли эти
коды зрительными.
Несколько более убедительные данные в пользу зрительного кодирования при выполнении
задач Стернберга были получены в эксперименте Клацки и Аткинсона (Klatzky а.
Atkinson, 1971). Эти авторы исходили из специфических способностей к переработке
информации двух полушарий мозга, а именно из того, что левая половина мозга
(у большинства людей) специализирована для переработкй вербального материала,
а правая — для переработки зрительно-пространственной информации. Положив это
в основу своих исследований, они провели эксперимент со сканированием памяти,
сходный с экспериментом Стернберга, с той разницей, что контрольный стимул предъявлялся
испытуемому либо в левой, либо в правой части его зрительного поля. Связи между
глазом и мозгом у человека устроены таким образом, что информация от левой части
зрительного поля обоих глаз поступает прямо в правое полушарие мозга, а от правой
части-в левое полушарие. Благодаря этому Клацки и Аткинсон могли направлять
контрольный стимул то в одно, то в другое полушарие и определили для каждого
полушария -зависимость ВР от величины стандартного набора. Когда стимул направляли
в левое полушарие, точка пересечения графика ВР с осью ординат была выше, чем
когда его направляли в правое полушарие, хотя наклон графика был в обоих случаях
одинаковым. Клацки и Аткинсон истолковали это различие как результат передачи
информации из одного полушария в другое. Они рассуждали следующим образом: когда
контрольный стимул поступает в левое полушарие, информация о нем должна быть
сначала передана в правое полушарие и только после этого может начаться сопоставление;
для этой передачи требуется некоторое время, и в результате точка пересечения
графика ВР с осью ординат соответственно смещается. При поступлении стимула
прямо в правое полушарие такой передачи не требовалось. Это указывает на то,
что процесс сравнения происходит в правом полушарии-в том, которое приспособлено
для переработки пространственной, а не вербальной информации. Тем самым получает
значительную поддержку мысль о том, что при сравнениях используется не вербальный
код, а скорее зрительные образы. Этот эксперимент, подобно эксперименту Стернберга
(Slernberg, 1967), подтверждает, что КП, вероятно, .может использовать зрительные
коды и что представление о чисто акустической природе КП требует пересмотра1.
Как мы увидим дальше, есть данные о том, что информация в КП может храниться
и в семантической форме.
1Здесь важно отметить, что мы вынуждены были несколько упростить
описание эксперимента Стернберга и других подобных исследований. О некоторых
главных упрощениях следует упомянуть. Прежде всего, модель последовательного
исчерпывающего сканирования — не единственная модель, позволяющая объяснить
линейное возрастание ВР с увеличением числа элементов в стандартном наборе.
Можно предложить модель параллельного сканирования, которая приведет к тем
же результатам (Townsend, 1972). Такая модель отличается от рассмотренной
нами простой параллельной модели (той, что предсказывает независимость ВР
от величины стандартного набора) тем, что она предполагает лишь ограниченную
способность испытуемого к переработке информации. При этом активность перерабатывающих
механизмов должна быть равномерно распределена между всеми подлежащими переработке
элементами. Когда этих элементов немного, на каждый из них приходится относительно
больше этой активности и переработка происходит быстро. Если же число элементов
велико, эта активность распределяется более "жидко", каждому элементу достается
меньше и переработка занимает больше времени. Это параллельная модель, поскольку
в ней предполагается, что все элементы могут сканироваться одновременно. Между
тем она предсказывает возрастание ВР с увеличением числа элементов в стандартном
наборе — ввиду ограниченной способности к переработке информации. Еще одна
модель, позволяющая предсказать полученные Стернбергом результаты, — это представление
о сканировании памяти как о последовательном самопрекращающемся процессе (Theios.
а. о., 1973).
Второе замечание касается влияния места, которое занимает в стандартном наборе
элемент, совпадающий с контрольным стимулом. Для положительных ответов можно
построить график зависимости ВР от места этого элемента (например, при стандартном
наборе и контрольном стимуле Р это будет второе место, при контрольном
стимуле Q — третье и т. д.). Модель последовательного исчерпывающего сканирования
предсказывает, что такой график будет горизонтальной прямой линией, так как
испытуемый всегда "просматривает" весь стандартный набор независимо
от места искомого элемента. Тем не менее в различных экспериментах такого типа были получены данные об увеличении ВР в зависимости от места в
ряду, об уменьшении ВР и, наконец, данные, соответствующие перевернутой
U-образной кривой. Обзор этих и других данных можно найти у Никкерсона
(Nickerson, 1972). Представляет также интерес подробный анализ,
произведенный Стернбергом (Sternberg, 1969).
СЕМАНТИЧЕСКИЕ КОДЫ В КРАТКОВРЕМЕННОЙ ПАМЯТИ
Поскольку мысль о хранении информации в КП в акустической форме впервые возникла
в связи с характером ошибок смешения, кажется очень удачным то, что первая демонстрация
содержащейся в КП семантической информации также была основана на смешениях.
Шульман (Shulman, 1972) показал, что характер смешений, происходящих в КП, вероятно,
можно предсказать, исходя из смысла информации. В его экспериментах с испытуемыми
проводили ряд проб, каждая из которых начиналась с того, что им предъявляли
список из 10 слов. За десятым словом следовало контрольное слово, и испытуемый
должен был сказать, "соответствует" ли оно какому-либо из слов, содержащихся
в списке. В некоторых пробах "соответствие" означало полную идентичность, а
в других-одинаковый смысл (или синонимию). В каждой пробе испытуемому непосредственно
перед контрольным словом сообщали о том, какого рода соответствие имеется в
виду в данной пробе.
Особый
интерес представляют те случаи, когда контрольное слово было синонимом
одного из слов, содержавшихся в списке, а испытуемого просили устанавливать
соответствие по принципу идентичности. Если испытуемый отвечает "да",
несмотря на отсутствие в списке идентичного слова, это указывает на
семантическое смешение; мы можем подозревать, что испытуемый допустил эту
ошибку (ошибочно идентифицировал контрольное слово с одним из элементов
списка, тогда как на самом деле оно было только синонимом) потому, что
он спутал эти два слова из-за семантического сходства между .ними. Чтобы
это могло произойти, нужно, чтобы в К.П испытуемого содержались какие-то
сведения о семантическом содержании слов, входящих в описок. Шульман
включил в свой эксперимент пробы, в которых под соответствием имелась
в виду синонимия, именно для того, чтобы побудить испытуемого активизировать
такую семантическую информацию, если он мог это сделать.
Полученные Шульманом результаты свидетельствуют в пользу семантического представления
информации в КП. Он установил, что ошибочная идентификация контрольного слова
с одним .из элементов списка чаще происходила в тех случаях, когда это слово
было синонимом одного из элементов, чем при отсутствии какого-либо смыслового
родства между этим словом и элементами списка. Такие ошибки случались даже тогда,
когда контрольное слово было синонимом одного из слов, предъявленных совсем
недавно (например, занимавших одно из трех последних мест в ряду), т. е. слов,
которые почти наверное содержались в КП (вспомните кривую зависимости свободного
припоминания от места в ряду — см. гл. 2). Таким образом, мы обнаружили смешения
в КП, имеющие семантическую основу.
Данные в пользу семантических представлений в КП получены и другими путями
(обзор см. Shulman, 1971). Наиболее исчерпывающими были работы Уиккеяса и его
сотрудников (обзор см. Wickens, 1972), которые использовали феномен снятия проактивного
торможения.
Для того чтобы понять работы Уиккенса, нам надо вспомнить два эксперимента,
которые были описаны в гл. 6 при обсуждении забывания из КП. Это эксперименты
Петерсона и Петерсон (Peterson a. Peterson, 1959) и Кетшеля и Андервуда (Keppel
a. Underwood, 1962). Говоря в двух словах, Петерсоны наблюдали быстрое забывание
триграммы, состоявшей из согласных, в течение 18-секундного интервала между
предъявлением и воспроизведением, а затем Кеппель и Андервуд показали, что такое
забывание происходило только в тех случаях, когда после нескольких первых проб
могло возникнуть проактивное торможение. Исходя из этих данных, Уиккенс и сотр.
(Wickens а. о., 1963) провели эксперимент следующего типа. Представим себе,
что с испытуемым проводят три пробы по задаче Петерсона, где запоминаемым материалом
служат различные триграммы, состоящие из согласных, а в течение 11-секундного
интервала удержания следует выполнять определенное задание-дистрактор. За это
время создается проактивное торможение (ПТ), и с каждой пробой испытуемый запоминает
все меньше и меньше согласных. Перед четвертой пробой характер запоминаемого
материала изменяют: вместо трех согласных предъявляют три цифры. Типичные результаты
такого эксперимента можно видеть на рис. 7.7. У испытуемых опытной группы, которым
стали предъявлять цифры, внезапно повысилась способность к припоминанию по сравнению
с контрольной группой, которой продолжали предъявлять согласные. По существу,
эффективность припоминания в экспериментальной группе в четвертой пробе (с цифрами)
близка к эффективности в первой пробе (с согласными). Создается впечатление,
что ПТ, разеивающееся во время первых проб, специфично для материала определенного
типа (в данном случае это согласные буквы) и не влияет на новый материал (цифры).
Таким образом, переключение на цифры-это переключение на деятельность, свободную
от лроактивного торможения, эффективность которой существенно выше, чем при
наличии ПТ.
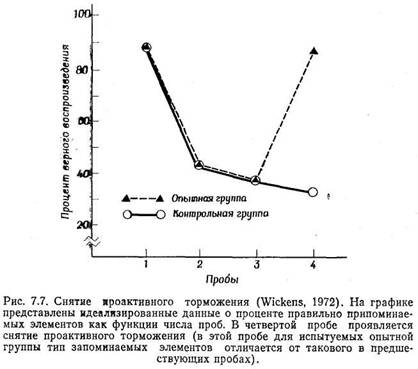
Специфичность ПТ в отношении того или иного типа запоминаемого материала-факт
чрезвычайно важный. Снятие ПТ указывает на то, что в данной ситуации используется
"новый" материал. Поэтому эффект снятия ПТ может служить средством для выяснения
того, какие аспекты стимулов представлены в КП. Поясним это на конкретном примере.
Предположим, что мы создаем у испытуемого ПТ, проводя с ним несколько проб,
в которых запоминаемым материалом служат группы из трех слов. В первых трех
пробах все слова относятся к пище. В пробе 1 это ХЛЕБ, ЯЙЦА, МОЛОКО; в пробе
2 — МЯСО, РЫБА, СЫР, в пробе 3 — МАСЛО, ЯЙЦА, КАША. А в пробе 4 мы вводим триграмму
нового типа, состоящую из названий животных: СОБАКА, КОШКА, ЛОШАДЬ. Будет ли
в этой пробе наблюдаться снятие ПТ? Произойдет ли резкое повышение эффективности
припоминания? Рассмотрим существующие возможности.
Допустим, что снятие ПТ не наблюдается. Это означает, что тип запоминаемого
материала остался прежним. Если пойти чуть дальше, это означает, что мы не изменили
характер материала с точки зрения испытуемого, т. е. не изменили ту информацию,
которую он кодирует и хранит во время пробы. Очевидно, он не хранит в памяти
тот факт, что в первых трех пробах все слова были названиями пищевых продуктов,
а в четвертой пробе — названиями животных.
Допустим теперь, что мы обнаружили снятие ПТ — внезапный скачок в способности
к припоминанию в четвертой пробе. Это говорило бы о переходе к материалу другого
типа. Значит, в контексте той информации, которую сохранял испытуемый в первых
пробах, переход от пищи к животным имел смысл. Но из этого следует,
что испытуемый должен был кодировать и хранить какие-то сведения относительно
смысла запоминаемых слов — о том, что первая группа слов относится к видам пищи,
а вторая — нет. Короче говоря, у нас были бы данные о том, что в КП хранится
смысл информации.
Уиккенс обнаружил, что изменения в семантическом содержании действительно сопровождаются
сдвигом в эффективности припоминания. Примером служат изменения, подобные только
что описанному (от пищи к животным); они ведут к эффекту снятия ПТ. Такой же
эффект наблюдается при переходе с одного языка на другой (например, с французского
на английский); от существительных мужского рода (дворецкий, петух, коверкот)
к существительным женского рода (королева, юбка, корова); от абстрактных существительных
(выгода, скука, положение) к конкретным (дворец, акробат, фабрика) и при многих
других переходах. Мы можем сделать вывод, что в КП представлен семантический
уровень запоминаемых элементов, а не просто их акустические коды.
Хотя результаты только что перечисленных экспериментов, казалось бы, подтверждают
мысль о семантическом кодировании в КП, их можно интерпретировать и по-иному.
Бэддли (Baddeley, 1972) оспаривает эти и другие данные, относящиеся к семантической
КП. По его мнению, данные о семантической КП возникают на самом деле в результате
того, что испытуемый прибегает к использованию приемов и правил, хранящихся
в ДП. Когда, например, испытуемый выполняет задачу на определение объема памяти,
где он должен запомнить ряд букв, то при воспроизведении он вряд ли допустит
ошибку смешения и назовет какую-либо цифру. Если к моменту припоминания в КП
будет содержаться след буквы "а", то испытуемый может назвать вместо нее букву
"h" , но не цифру "8"1 — просто потому, что, как ему известно, предъявлявшийся
ряд состоял из букв. Точно так же испытуемый может использовать информацию из
ДП в экспериментах с КП таким образом, что результаты будут совместимы с теорией
о возможном хранении в КП семантической информации.
1Речь идет об ошибке акустического смешения: а, h
и 8 по-английски звучат соответственно как "эй", "эйч" и
"эйт", — Прим. ред.
Рассмотрим феномен снятия проактивного торможения. По мнению Бэддли, это явление
свидетельствует о переработке информации в ДП, а не в КП. В данной пробе испытуемый
старается припоминать самые последние элементы в ряду. Интервал удержания достаточно
велик, так что искомая информация может уже не находиться в КП. Кроме того,
источником интерференции служит материал, предъявлявшийся в нескольких предыдущих
пробах. Если этот материал сходен с тем, что нужно вспомнить сейчас (если, например,
все элементы — слова одной категории, скажем названия животных), то единственное,
что может сделать испытуемый, чтобы выбрать самые недавние элементы, — это использовать
какие-то сведения о порядке или времени предъявления элементов. Если же подлежащий
.припоминанию материал отличается от предъявлявшегося прежде (как это бывает
в тесте на снятие ПТ), то тогда это различие служит дополнительным фактором,
помогающим испытуемому выбрать самые недавние элементы. Если, например, в предыдущих
пробах использовались названия животных, а в текущей — названия видов пищи,
то эти различия могут создать основу для извлечения самых недавних элементов
— тех, которые предъявляются в текущей пробе. Использование этого различия ведет
к лучшему припоминанию — и к явлению снятия ПТ.
Эмпирические данные в пользу того, что снятие проактивного торможения объясняется
извлечением информации из ДП, были получены Гардинером с сотрудниками (Gardiner
а. о., 1972). Они провели тесты на снятие ПТ, используя переход с материала
одного подкласса на материал другого подкласса того же класса. Например, если
все элементы в предшествующих пробах были названиями полевых цветов, то в последней
пробе вместо них могли быть предъявлены названия садовых цветов. Экспериментаторы
нашли, что типичное снятие ПТ происходит лишь при определенных условиях. Оно
не происходило, если испытуемому для облегчения задачи сообщали общее название
класса (например, ЦВЕТЫ). Однако оно наблюдалось в тех случаях, когда ему сообщали
более специальное название подкласса (например, ПОЛЕВЫЕ ЦВЕТЫ) — во время предъявления
или во время припоминания. Из этих результатов следуют два особенно важных вывода.
Во-первых, снятие ПТ для одного и того же материала может происходить при одних
условиях, но не происходить при других. Это указывает на то, что само по себе
изменение характера запоминаемого материала не вызывает снятия ПТ. Во-вторых,
снятие ПТ удавалось получить, сообщая испытуемому во время припоминания соответствующий
"ключ" — название специфического класса. Это служит веским доводом в пользу
того, что снятие ПТ осуществляется во время извлечения информации. Иначе говоря,
тот факт, что "ключ" эффективен только при сообщении его во время припоминания
(а не в то время, когда происходило кодирование материала), показывает, что
снятие ПТ не зависит от кодирования. По-видимому, ключ может оказывать свое
воздействие в период извлечения информации, и его наличие или отсутствие определяет,
произойдет ли снятие ПТ. Таким образом, имеющиеся данные свидетельствуют в пользу
того, что снятие ПТ зависит от процессов извлечения информации из долговременной
памяти.
Критические замечания Бэддли и приведенные выше данные,
несомненно, заставляют несколько усомниться в существовании семантических
представлений в кратковременной памяти. Однако наша концепция КП может
помочь разрешить эту проблему. Если мы рассматриваем просто ту часть
КП, в которой материал удерживается в результате механического
повторения, то кажется маловероятным, что семантическое содержание играет
здесь сколько-нибудь важную роль. Но рассматривая рабочее пространство КП, в
частности роль КП в выполнении таких функций, как структурирование,
мы имеем дело с той частью КП, которая носит в основном семантический
характер. Из нашей концепции КП вытекает, что для выполнения многих задач,
связанных с кратковременным хранением информации, требуется также
значительное участие ДП. Мысль о взаимодействии между этими двумя
хранилищами информации помогает включить в нашу модель представление о том,
что семантическая информация может быть закодирована для хранения в КП, а
самый акт кодирования для КП, в котором участвует ДП, может
рассматриваться как одна из форм выполняемой КП "работы".
На
данном этапе, по-видимому, ясно следующее: та картииа КП, которая
создается в результате проведенного в этих трех главах обсуждения, уже мало
похожа на простую теорию, изложенную в гл. 2. Но ведь нам с самого начала
было известно, что адекватная теория не может быть такой простой.
Теории КП усложнились, так как фактические данные указывают на то, что
кратковременная память действительно очень сложна.
ЕЩЕ НЕСКОЛЬКО СЛОВ О ТЕОРИИ ДВОЙСТВЕННОСТИ
Отвлечемся теперь от обсуждения кратковременной памяти и ознакомимся поближе
с одним интересным вариантом теории двойственности памяти — с так называемой
"буферной моделью" (Atkinson a. Shiffrin, 1968). Эта теория примечательна тем,
что она пытается ввести в рамки ставших привычными представлений о двух типах
памяти идею о сложной, "когнитивной" КП. Именно Аткинсон и Шифрин предлагали
разграничивать в памяти "регулирующие процессы" и "структурные компоненты",
и именно их подход к процессам регулирования в КП представляет особый интерес
в данном контексте.
Напомним, что регулирующий процесс не является встроенным,
а лишь прилагается к внутренним структурам. Он предста.вляет собой результат
принятия субъектом решения, не обязательно осознанного, оперировать системой
памяти определенным образом. Мы можем задать вопрос: по каким параметрам
система, перерабатывающая информацию, может регулировать КП? Одна группа
процессов регулирует величину имеющегося в КП пространства для хранения
информации, которое в этой модели называется "буфером повторения". По Аткинсону я Шифрину, это то место, где может
производиться
лишь механическое повторение небольшого числа структурных единиц, а не
какая-то более сложная "работа". К числу регулируемых параметров
здесь относятся: размеры используемого буфера (конечно, в границах, определяемых объемом памяти), соотношение между числом элементов iB буфере
и рабочим пространством (должно ли быть много элементов при небольшом
рабочем пространстве или мало элементов при гораздо большем пространстве для
работы). В последнем случае выбор зависит от самого процесса
повторения. Мы можем выбрать для повторения определенные элементы,
потому что они хорошо соответствуют друг другу, например сходны по ритму:
"работа", "колода", "зевота", "природа" (к этому
набору для повторения мы не стали бы добавлять слово
"несоответствие"). Или же мы можем прекратить повторение какого-либо
элемента и изъять его из буфера.
Если покажется, что это снова начинает
напоминать нашу простую модель с ячейками, то не следует поддаваться такому впечатлению. Ведь в эту модель входят также регуляторные
процессы, влияющие на рабочее пространство КП, и в ней оговорено, что форма
информации, передаваемой из КП в ДП, завысит от этих процессов. Аткйнсон и
Шифрин допускают, что повторение многих элементов может производиться
механически, но при этом они будут переноситься в ДП, будучи обогащены лишь
в какой-то минимальной степени. Быть может, при этом в ДП попадает только
самый факт, что они находились в КП. Этому следует противопоставить
переносимую в ДП информацию об элементах, подвергшихся обработке. Элементы
могут быть опосредованы, ассоциированы с чем-либо или же структурированы,
после чего информация может быть передана в ДП в обогащенной форме.
Однако это обогащение-процесс дорогостоящий: он уменьшает число элементов,
которые могут находиться в КП.
Итак, идея о том, что между рабочей
памятью и пространством для хранения существует постоянный "обмен"
(как это обсуждалось в гл. 6), получает дальнейшее развитие. Но дело
не только в этом. В буферной модели заложена идея о тесных и сложных связях
между КП и ДП, а также о возможности хранения в КП семантической и
зрительной информации. В соответствии с результатами рассмотренных нами
экспериментов эта модель намного сложнее, чем представление о КП как о
наборе ячеек.
Глава 8
Долговременная память: структура и семантическая
переработка информации
Как мы уже говорили, в
долговременной памяти хранится все то, что нам известно об окружающем мире.
Именно благодаря находящемуся в ДП материалу мы можем вспоминать
прошлые события, решать задачи, распознавать образы — короче говоря,
мыслить. Все знания, лежащие в основе познавательных способностей человека,
хранятся в ДП.
В предыдущих главах уже упоминалось о некоторых аспектах ДП. Нам известно,
что в ДП хранятся абстрактные коды образов и что эти коды могут сопоставляться
с входными стимулами, обеспечивая распознавание этих стимулов. Мы видели, что
информация может быть структурирована с помощью различных правил — правил орфографии,
правил перекодирования рядов цифр, правил синтаксиса. Все эти правила хранятся
в ДП. Мы также убедились, что в ДП содержатся значения слов и факты. В экспериментах
Шифрина (Shiffrin, 1973) по забыванию из КП использовались арифметические правила,
хранящиеся в ДП. Кто написал "Макбет"? Ответ на этот вопрос, вероятно, имеется
в вашей ДП. Если Джон бежит быстрее, чем Мэри, а Салли — быстрее, чем Джон,
то кто бежит быстрее всех? При ответе на этот вопрос вы используете информацию,
хранящуюся в ДП. Уже само количество хранящейся в ДП информации поразительно.
По мнению некоторых теоретиков (например, Penfield, 1959), все, что человек
когда-либо заложил в ДП, остается в ней навсегда. В таком случае наша долговременная
память содержит огромную массу всевозможных сведений.
"Расположение" всей этой информации в ДП представляет не меньший
интерес, чем ее количество. Информация, повидимому, хранится здесь в
весьма упорядоченном виде. Факты связаны с другими фактами неслучайным
образом; одно слово соединяется с другими по смыслу. Вероятно, именно
благодаря такому упорядоченному хранению мы имеем возможность
извлекать из ДП информацию — например, о том, кто написал "Макбет", —
за несколько секунд. И уж во всяком случае мы не ищем наугад по всей ДП
автора "Макбет", так как на это пришлось бы потратить годы.
СТРУКТУРА ДОЛГОВРЕМЕННОЙ ПАМЯТИ
Браун и Мак-Нейл (Brown a.
McNeill, 1966) продемонстрировали и попытались описать некоторые
закономерности хранения информации в ДП, проведя эксперимент, в котором было использовано так называемое "состояние готовности" —
хорошо знакомое каждому состояние, когда какое-то слово или имя "вертится
на кончике языка", но человек никак не может окончательно вспомнить
его. В этом эксперименте испытуемым предъявляли определения слов и просили
их называть эти слова. Например, испытуемому говорили: "небольшая
лодка, используемая в гаванях и реках Японии и Китая, на которой гребут
одним веслом с кормы и на которую часто ставят парус". Браун и Мак-Нейл
хотели создать состояние готовности, при котором испытуемый чувствовал бы, что он знает слово (оно "вертелось бы на кончике
языка"), но просто не мог бы припомнить его. Конечно, во многих
пробах этого не происходило — испытуемый либо тотчас же вспоминал слово,
либо сознавал, что вообще не знает его. Таким образом, состояние готовности
было довольно трудно уловимым, но авторам удавалось создавать его достаточно часто (вероятно, благодаря удачному подбору определений). Когда
это состояние возникало, оно обладало рядом характерных черт. Испытуемый
не только чувствовал, что он знает слово,-иногда он даже мог сказать,
сколько в нем слогов, с какой буквы оно начинается или на какой слог
падает ударение. (Он говорил, например: "В нем два слога, ударение на
первом, а начинается оно с буквы "S"".) Нередко он мог сказать, какие
слова не подходят ("это не sandal и не schooner"), и мог назвать
слова, близкие по смыслу. Такого рода припоминание, при котором испытуемый
может определить общие особенности слова, называется припоминанием
родовой принадлежности.
Излагая свои соображения относительно припоминания родовой принадлежности,
Браун и Мак-Нейл описали некоторые аспекты структуры ДП. По их мнению, то или
иное слово хранится в ДП в определенном месте, оно представлено здесь как слуховой,
так и семантической информацией. Поэтому извлечение данного слова из ДП может
быть основано на его звучании (например, я произношу слово СОБАКА, а вы объясняете
мне, что оно означает) или на его смысле (я говорю ЛУЧШИЙ ДРУГ ЧЕЛОВЕКА, а вы
отвечаете "собака"). В состоянии готовности полное извлечение по смыслу оказывается
невозможным, но испытуемый все же частично извлекает требуемое слово. Он имеет
некоторое представление о его звучании, но, очевидно, не имеет его полного акустического
образа. Браун и Мак-Нейл полагают также, что .вместе с каждым словом хранятся
его ассоциации, или связи, с другими словами ,в ДП, так что испытуемый может
назвать другие слова, означающие почти то же самое. Таким образом, эти авторы
описывают ДП как обширный набор взаимосвязанных участков, в каждом из которых
содержится сложная совокупность информации, относящейся к одному слову или факту.
Структура ДП будет главным предметом этой главы. Результаты экспериментов с
состоянием готовности наводят на мысль, что ДП можно изобразить как сеть, образованную
пучками информационных связей. Такая концепция находится в прямом родстве с
теорией "стимул — реакция", обсуждавшейся в гл. 1. Некоторые более поздние модели
структуры ДП также основаны на ассоциациях (Anderson a. Bower, 1973; Quillian,
1969; Rumelhart а. о., 1972); однако возможны и другие представления о структуре
ДП, например концепции, согласно .которым ДП состоит из неких наборов информации
(Meyer, 1970) или групп значимых характеристик (Rips а. о., 1973; Smith а. о.,
1974). Каждый из этих подходов имеет свои преимущества, и мы рассмотрим их поочередно.
С каждой моделью строения ДП связаны определенные объяснения происходящих в
ДП процессов — способов, при помощи которых структурированная информация может
быть использована.
Прежде чем
мы перейдем к подробному рассмотрению моделей ДП, следует сделать
несколько замечаний. Прежде всего надо иметь в виду, что современные модели
ДП весьма сложны. Это определяется сложностями самой ДП. О некоторых
из них мы уже упоминали: во-первых, использование хранящейся в ДП информации
связано с решением задач, логической дедукцией, дачей ответов на вопросы,
припоминанием фактов и многим другим; во-вторых, ДП содержит поразительно много разнообразной информации; в-третьих, ее
организация
упорядоченна, а не случайна. Ни одна из современных моделей не может
вполне адекватно объяснить многочисленные способы использования хранящейся в
ДП информации, ее количество и ее организацию. Однако модели постоянно
видоизменяются с учетом вновь появляющихся данных.
Другое замечание также отражает все связанные с ДП сложности: в сущности, имеет
смысл говорить не об одной ДП, а о двух. Мысль о существовании двух ДП выдвинул
Тульвинг (Tulving, 1972), который предложил провести различие между семантической
и эпизодической памятью. Обе памяти служат долговременными хранилищами
информации, но различаются по характеру этой информации.
Все, что нам нужно для того, чтобы пользоваться речью, хранится в семантической
памяти. Она содержит не только слова и обозначающие их символы, их смысл и их
референты (т. е. вещи, названиями которых они служат), но такж правила обращения
с ними. В семантической, памяти хранятся такие вещи, как правила грамматики,
химические формулы, правила сложения и умножения, знание того, что осеь наступает
после лета, — все те факты, которые не связаны каким-то определенным временем
или местом, а представляют собой просто факты. Эпизодическая память, напротив,
содержит сведения и события, закодированные применительно к определенному времени,
информацию о том, как выглядели те или иные вещи и когда мы их видели. Эта память
хранит разного рода автобиографические данные, как, например: "Я сломал ноту
зимой 1970 года". Она содержит сведения, зависящие от контекста: "Я не каждый
день готовлю на обед рыбу, но вчера у нас была рыба".
Материал, хранящийся в семантической и в эпизодической памяти, различается
не только по своему характеру, но и по своей подверженности забыванию. В эпизодической
памяти информация довольно легко может стать недоступной, потому что сюда непрерывно
поступает новая информация. Когда вы извлекаете какие-либо сведения из одной
или другой памяти — например, когда вы умножаете 3 на 4 (при этом используется
семантическая память) или вспоминаете, что вы делали прошлым летом (из эпизодической
памяти), — этот акт извлечения информации сам представляет собой некое событие.
Как таковое это событие должно поступить в эпизодическую память, в которой появятся
сведения о том, что вы умножили 3 на 4 или что вы предавались воспоминаниям
о прошедшем лете. Таким образом, эпизодическая намять находится в состоянии
непрерывного изменения, и содержащаяся в ней информация часто преобразуется
или становится недоступной для извлечения. В отличие от этого семантическая
память, вероятно, изменяется гораздо реже. На нее не оказывает влияния акт извлечения,
и хранящаяся в ней информация, как правило, остается на месте.
В связи с разделением ДП на две такие части особенно важно установить их соотношение
традиционными методами исследования человеческой памяти, в частности с помощью
экспериментов, в которых используются списки слов (они рассматривались в гл.
1). Такие списки слов, несомненно, фиксируются в эпизодической памяти. Если,
например, испытуемому предъявляют список из 20 слов, в число которых входит
слово "лягушка", это не значит, что он усваивает слово "лягушка" заново. Это
слово содержалось в семантической памяти испытуемого до того, как он заучил
описок, находится в ней сейчас и останется там в будущем. Однако испытуемый
узнал, что слово "лягушка" содержится в том списке, который ему в данное время
предъявляют, — факт, который привязан к данному времени и к данной ситуации.
Этот факт сохранится в его эпизодической памяти. А это означает, что в
традиционных психологических экспериментах изучается эпизодическая, а не
семантическая память. Изучению семантической памяти со времен Эббингауза
уделялось очень мало внимания.
Только за последние десять лет или около того семантическая память стала предметом
многочисленных исследований. Эти исследования касаются прежде всего структурной
организации наших семантических знаний об окружающем мире и использования этих
знаний при выполнении различных задач. В этой главе мы рассмотрим несколько
моделей семантической памяти (некоторые модели включают также и эпизодическую
память); сейчас мы перейдем к описанию строения и функций ДП в соответствии
с этими моделями. Модели семантической памяти можно грубо классифицировать как
сетевые, теоретико-множественные и модели, основанные на семантических признаках.
Эти типы моделей нельзя полностью разграничить; все они взаимосвязаны, и это
не удивительно, так как все они пытаются дать объяснение одним и тем же человеческим
способностям. Однако модели каждого типа обладают некоторыми отличительными
особенностями; в дальнейших р.азделах мы рассмотрим характер моделей каждого
типа и некоторые возникающие в связи с ними проблемы.
СЕТЕВЫЕ МОДЕЛИ ДОЛГОВРЕМЕННОЙ ПАМЯТИ
Сетевые модели семантической памяти, подобно теории Брауна и Мак-Нейла, описывают
ДП как чрезвычайно обширную сеть связанных между собою понятий. Сетевые модели
обладают известным сходством с концепцией "стимул — реакция", рассматривающей
память как пучок ассоциаций. Однако эти модели в некоторых отношениях существенно
отличаются от традиционных ассоциационистских концепций. Прежде всего большинство
таких моделей допускает образование ассоциаций разного рода, т. е. допускает,
что не все ассоциации одинаковы. Это значит, что при ассоциировании двух понятий
взаимоотношения между ними известны; ассодиация — это нечто большее, чем простая
связь. Такой подход получил название "неоассоциационизма" (Anderson а. Bower,
1973). Подобное представление о ДП содержит также идею о том, что ассоциативные
сети обладают максимально возможной упорядоченностью и компактностью. Следует
ожидать, что предметы, концептуально близкие друг другу, будут тесно ассоциироваться
в сетях ДП. В этом смысле ДП похожа на словарь, где, однако, "слова" не расположены
в алфавитном порядке; алфавитный принцип, по которому построены наши обычные
словари, мало полезен при выяснении связей между понятиями. Возьмем, например,
названия .двух таких сравнительно необычных животных, как архар и як. Они очень
близки понятийно, но максимально разделены в словаре. В ДП они, вероятно, ассоциированы
более тесно, чем в словаре.
Но если ДП представляет собой такого рода упорядоченную сетевую структуру,
можно задать вопрос: что же означает "упорядоченная"? Мы можем попросить дать
нам более подробное описание этой сети-именно в этом и состоит задача моделей,
которые мы собираемся рассмотреть. При этом рассмотрении мы прежде всего обнаружим,
что связи между понятиями оказываются круговыми. Что это означает? Вернемся
вновь к нашему примеру со словарем. Допустим, что нам нужно выяснить по словарю
значение слова "клиент". Мы найдем: "клиент, сущ.-1. Постоянный
покупатель или заказчик. 2. Лицо, пользующееся услугами профессионала, например
юриста". Мы получили довольно подробное описание слова "клиент"-это существительное,
т. е. название некоторой "вещи"; оно имеет несколько значений, и нам сообщили
об этих значениях. Допустим, однако, что мы не знаем языка, на котором составлен
словарь, и поэтому нам мало поможет определение, данное через другие слова,
которые нам тоже неизвестны, такие, как "профессионал". Мы можем посмотреть
в словаре слово "профессионал" и найдем, что это "лицо, владеющее данной профессией".
Это нам не очень поможет. Мы можем посмотреть слово "юрист" и обнаружим, в частности,
что "...юрист-общий термин, приложимый ко всем лицам, занимающимся данной профессией;
адвокат и поверенный — юристы, ведущие дела своих клиентов". Короче говоря,
мы запутались: "клиент" определяется через слово "юрист" и "профессионал"; "юрист"
определяется через слова "профессия" и "клиент"; "профессионал"-через слово
"юрист" и так далее. Вот это и означает круг в определении. Слова определяются
при помощи других слов. И, как мы увидим, d сетевых теориях ДП предполагается,
что понятия приобретают смысл
благодаря их ассоциациям с другими понятиями.
Следует сделать еще одно последнее замечание относительно языка, которым пользуются
при описании современных моделей ДП. Вам может показаться, что эта терминология
взята прямо из школьного учебника грамматики, поскольку ДП описывают с помощью
таких слов, как подлежащее, сказуемое, существительное и т. п. В чем тут дело?
Немного подумав, мы увидим, что в этом нет ничего странного. Возьмем, например,
термины "подлежащее" и "сказуемое". "Подлежащее" — это некий предмет, некое
понятие, которое может быть представлено существительным или именной фразой.
"Сказуемое" — это понятие, сообщающее нам что-либо о подлежащем. Подлежащее
и сказуемое, "вещность" и предикация вещей, очевидно, соответствуют различным
аспектам действительных отношений. В качестве таковых они обладают не только
грамматической, но и психологической реальностью и, вероятно, представлены в
ДП в виде элементов, отделимых друг от друга. Таким образом, в той мере, в какой
грамматические понятия обладают психологической реальностью, мы будем встречаться
в моделях ДП с грамматическими терминами. Кроме того, в современных моделях
структуры семантической ДП основной упор делается на то, каким образом в ней
представлены те знания, которые передаются при помощи языка. Поэтому грамматические
термины особенно удобны для описания ДП. Такое выделение роли языка вполне оправдано,
так как именно необычайное развитие речи отличает человека от других живых существ.
Возможно даже, что именно эти лингвистические
способности обусловливают огромную емкость нашей памяти. По всем этим
причинам структура языка занимает центральное место в описаниях ДП.
МОДЕЛЬ КУИЛЛИАНА
Существует несколько моделей долговременной памяти, в которых язык и ассоциативные
сети играют важную роль. Первая из них-"Обучаемая система, понимающая язык"
(ОСПЯ)1 -была предложена Куиллианом (Quillian, 1969; Collins a. Quilliap,
1969). Эта модель реализована в виде
машинной программы, которая
пытается имитировать способность человека понимать и использовать язык
естественным образом. В ..сущности, это попытка научить вычислительную машину разговаривать. На самом деле модель Куиллиана гораздо
обширнее, чем она представлена здесь, так как описание ДП-лишь один из
аспектов этой модели. Мы ограничимся рассмотрением содержащихся в модели
положений относительно структуры ДП, процессов, действующих на эту
структуру, и экспериментальных данных, относящихся к этому вопросу.
1Ее оригинальное (TLC). — Прим.ред. название — Teachable Language
Comprehender
Рассмотрим прежде всего структуру ДП в соответствии с моделью Куиллиана. Фактическая
информация представлена в этой модели структурами трех типов-элементами, свойствами
и стрелками. Элементы и свойства-это определенные "места" в ДП в том смысле,
как это понимают Браун и Мак-Нейл, т, е. участки, соответствующие информации
о тех или иных понятиях. Различие между элементами и свойствами состоит в том,
что они представляют понятия разного рода. Элемент — это структура, соответствующая
какому-то объекту, событию или идее; это вещи, которые в английском языке бывают
представлены существительным, именной фразой пли, если они достаточно сложны,
целым предложением. По существу элемент-это то, что мы назвали "вещностью" (примерами
элементов могут служить понятия "собака", "Америка", "отец", "хорошая погода",
"хороший вибрафон" и т. п.). Свойство — это структура, сообщающая нам что-нибудь
об элементе; грамматически она соответствует сказуемому в предложении или же
прилагательному, наречию и т. п. (примеры: "плотный", "изящный", "быстро", "любит
кошек"). Следует отметить, что хотя мы здесь приводим в качестве примеров слова,
на самом деле элементы и свойства — структуры более абстрактные, чем слова.
Это всего лишь внесенные в ДП записи, соответствующие определенным словам, а
не сами слова. Однако использование словудобный способ называть определенные
элементы или свойства, хранящиеся в ДП.
Чтобы понять, как стрелки вместе с элементами и свойствами образуют структуру
ДП, полезно обратиться к рис. 8.1, где изображена структура, соответствующая
всего лишь одному понятию-понятию, выражаемому словом "клиент" (таким образом,
здесь отображен только один крошечный участок ДП). Как видно из этой схемы,
слово "клиент" находится вне сетевой структуры ДП; в "умственном словаре" оно
лежит за пределами этой сети. Однако оно указывает тот участок (т. е. элемент)
в сети, который соответствует слову "клиент". Ассоциация между словом "клиент",
находящимся в умственном словаре, и элементом "клиент" называется стрелкой.
В сущности стрелки — это ассоциации в системе ОСПЯ. Они позволяют ассоциировать
словарные метки с понятиями, хранящимися в ДП, а также связывают друг с другом
элементы и свойства внутри сети ДП. Тем самым они служат для определения этих
элементов и свойств; фактически определения соответствуют комплексам ассоциаций.
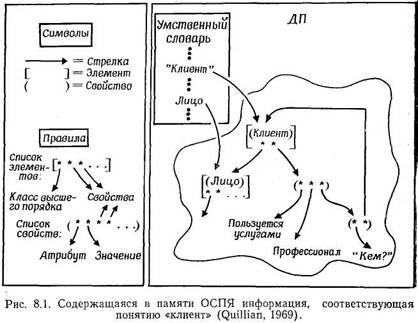 ; ;
Согласно модели ОСПЯ, природу элементов и свойств
можно описать, пользуясь небольшим числом правил. Рассмотрим правила,
по которым можно создать элемент (рис. 8.1). Любой элемент состоит из
упорядоченной группы стрелок. Первая стрелка данного элемента должна указывать на какой-то другой элемент, а именно на тот, который стоит по рангу
непосредственно над первым. (Например, элементе, соответствующем понятию
"клиент", первая стрелка ведет к элементу "лицо", так как
понятие "лицо" включает в себя понятие "клиент". В сущности
это класс ("лица"), стоящий на одну ступень выше класса
"клиенты"ближайший класс высшего ранга, в который входит класс
"клиенты".) Остальные стрелки этого элемента ведут к свойствам.
Число таких стрелок не ограничено. В данном примере, однако, мы приводим только одну
стрелку-ту, которая ведет к свойству, определяемому как "пользуется
услугами профессионала".
Для того чтобы понять свойства, нужно ознакомиться с правилами, по которым
они создаются в модели ОСПЯ. Подобно элементам, свойства состоят из упорядоченных
групп стрелок. Как мы сейчас увидим, первые две стрелки совершенно обязательны.
Чтобы понять, куда они направлены, мы должны сначала рассмотреть природу свойств
вообще. Возьмем какое-нибудь типичное свойство, которое могло бы характеризовать
какой-либо элемент, что-нибудь вроде "оно белого цвета". Это свойство относится
к опреде.ленному атрибуту — предмет, характеризуемый данным свойством, обладает
атрибутом цвета, и в данном случае значение этого атрибута — "белый". Вообще
свойство можно представить себе как некий атрибут плюс определенное значение
этого атрибута. Это может быть что-то иное, не выражаемое прилагательным (как
"белый"); это может быть обстоятельство места, например "на холме". Здесь "на"
есть атрибут, а "холме" — значение этого атрибута. Другого рода свойство может
быть больше похоже на сказуемое, например "забрасывает мячи". Таким образом,
форма, "атрибут-значение" носит достаточно общий характер и может включать свойства
практически любого рода.
Вернемся теперь к правилам построения свойств. Мы уже говорили, что они должны
содержать две обязательные "стрелки. Ясно, что первая из них указывает на какой-то
атрибут, а вторая на значение этого атрибута. Первая стрелка, "определяющая
свойство клиента (рис. 8.1), указывает на "пользуется услугами" (атрибут), а
вторая — на "профессиоиала" (значение). Таким образом мы узнаем, что свойство
клиентов состоит в использовании услуг профессионалов. Помимо этих двух обязательных
стрелок, соответствующих атрибуту и его значению, свойство может содержать любое
число стрелок, ведущих к другим свойствам. Рассматриваемое нами свойство имеет
такую дополнительную стрелку; она указывает на свойство "клиентом" (на характеристику,
в данном случае отвечающую на вопрос: кем используются услуги профессионала?).
Таким образом, выясняется, что клиент — это лицо, которое пользуется услугами
профессионала; профессионал используется (кем?) клиентом. Нетрудно было бы расширить
приведенную схему до размеров всей этой книги. Мы могли бы отобразить свойства
элемента "лицо" и свойства тех элементов и свойств, которые входят в определение
понятия "лицо". В это определение может, например, входить элемент "живое существо";
представьте себе все стрелки, которые потребуются для определения этого нового
элемента, а также вcex тех объектов, на которые они указывают. В результате
получилось бы огромное взаимосвязанное множество понятий — это и есть память
системы ОСПЯ.
Итак, все это приводит к созданию колоссальной сети понятий. Они бывают двух
типов-элементы и свойства, а связи между ними придают им смысл. Элементы определяются
при помощи других элементов и свойств, свойства при помощи других свойств и
элементов. Следует также отметить (хотя в модели ОСПЯ это специально не выделено),
что понятия должны определяться также своими связями с внешним миром, осуществляемыми
через органы чувств. ДП не может быть полностью замкнута в себе. Какую пользу,
например, может принести определение такого понятия, как "белый", через его
связи с такими понятиями, как больница, ландыши, простыни и т. п., если у нас
нет воспоминаний о том, что мы все это видели? Таким образом, в конечном счете
модели долговременной памяти должны объяснить нетолько взаимосвязи между ее
внутренними частями, но и ее взаимодействие с внешним миром. Те из ее внутренних
взаимосвязей, которые определяют понятия через их отношения к другим понятиям,
придают ДП большое сходство с толковым словарем. Как мы видели, в таких словарях
определения слов даются при помощи других слов, а если мы начнем искать эти
другие слова, то обнаружим, что и они определяются при помощи слов. Каждое слово
в словаре приобретает смысл только благодаря сложным взаимосвязям между объясняемыми
словами и довольно редким картинкам, которые позволяют связать слова со зрительным
сенсорным опытом.
Мы могли бы оказать, что предложенная Куиллианом модель ДП дает картину обширной
ассоциативной сети. Ассоциируются здесь понятия — такие, например, как "клиент",
или "иметь окраску", или "действовать тем или иным образом". Понятия связаны
друг с другом стрелами, которые по существу и отображают ассоциации. Эти ассоциации
отличаются от традиционных связей "стимул — реакция" тем, что они бывают нескольких
различных типов: иерархические ассоциации, ассоциации через свойства, атрибуты
и их значения. Изображение ДП как набора ячеек, связанных помеченными ассоциациями,
— главная черта сетевых моделей ДП.
МОДЕЛЬ АНДЕРСОНА И БОУЭРА
Модель Куиллиана была одной из первых, в которых долговременная память изображалась
как сеть, содержащая все, что известно данному человеку об окружающем мире,
и делалась попытка имитировать язык человека путем создания детализированной
программы для вычислительной машины. Позже появились и другие сетевые модели,
у каждой из которых были свои особенности. Для того чтобы расширить представление
о сети, полезно рассмотреть еще одну модель такого типа, созданную Андерсоном
и Боуэром (Апderson a. Bower, 1973) и названную АПЧ, т. е. "Ассоциативная память
человека" (НАМ -- Human Associative Memory)1.
1Сходная модель, созданная Румельхартом, Линдсеем и
Норманом (Rumelhart а. о., 1972), подробно рассматривается в книге Линдсея и
Нормана (Lindsay a. Norman, 1972). Эту книгу можно рекомендовать для
дополнительного чтения тем, кто заинтересуется сетевыми моделями.
Хотя модель АПЧ обладает общим сходством с куиллиановской ОСПЯ, она сильно
отличается по предполагаемой детальной структуре долговременной памяти. Конечно,
будучи сетевой моделью, АПЧ описывает долговременную память как обширное собрание
ячеек и помеченных ассоциаций. Однако основной компонент АПЧ — "молекула" ДП
— называется высказыванием. Эти высказывания сходны с предложениями, с той разницей,
что они более абстрактны. Иными словами, высказывание может отображать какую-то
лингвистическую структуру, например предложение, но это не есть само предложение.
(В высказываниях может быть представлена не только лингвистическая информация;
они могут также представлять нелингвистичеокую информацию в ДП. Например, согласно
Андерсону и Боуэру, описания визуальных сцен могут быть представлены в ДП высказываниями.)
Обычно высказывание — это небольшая группа ассоциаций и ячеек (подобно тому
как единица в модели ОСПЯ это небольшой набор элементов и свойств). Каждая ассоциация
— бинарная; это означает, что в ней связаны, или ассоциированы, два понятия.
Ассоциации бывают нескольких типов. Типы ассоциаций и способы их соединения
при построении высказываний представлены на рис. 8.2. Следует рассмотреть четыре
основных типа ассоциаций, каждая из которых объединяет две более простые идеи.
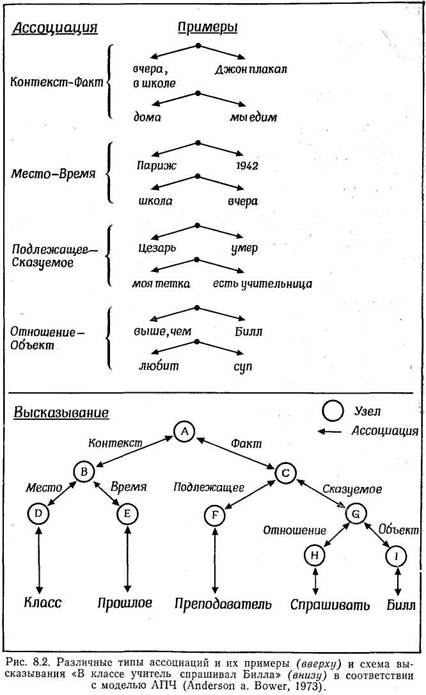
1.
Ассоциация, соединяющая некоторый контекст с определенным фактом. Контекст
сообщает, где и когда имел место факт, а факт несет информацию о том, что
произошло в данном контексте.
2. Ассоциация, соединяющая место и
время; это сочетание образует определенный контекст. Место сообщает нам
о том, "где", а время — о том, "когда".
3. Ассоциация, соединяющая подлежащее со сказуемым. Такое сочетание образует
некоторый факт. Подлежащее сообщает нам о том, к чему относится данный факт,
а сказуемое — о том, что происходит с подлежащим.
4. Само сказуемое
может быть ассоциацией, состоящей из двух частей: сказуемое нередко сообщает
нам о взаимоотношениях между подлежащим и каким-либо объектом. Так,
можно сказать, что сказуемое связывает какое-то отношение(глаголоподобную форму, вроде "есть выше, чем", "ударил" или
"есть отец такого-то") и его объект.
В надлежащих сочетаниях эти четыре типа ассоциаций (контекст — факт, место
— время, подлежащее — сказуемое, отношение — объект) образуют высказывание.
Высказывание лучше всего проиллюстрировать при помощи дерева — разветвленной
схемы, из которой видно, каким образом различные понятия могут объединиться
в высказывание. В нижней части рис. 8.2 изображено такое дерево для высказывания.
"В классе учитель спрашивал Билла". В вершине дерева буквой А обозначено понятие,
соответствующее данному высказыванию в целом. Точка А, так же как и все другие
точки, в которых соединяются два ассоциированных элемента, называется "узлом".
Узел высказывания представляет собой результат бинарной (двучленной) ассоциации
между контекстом и фактом. Последние представлены на следующем уровне схемы.
Еще ниже мы видим, что контекстный узел (B) — это ассоциация между определенным
местом (D, в классе) и временем (Е, в прошлом, поскольку учитель спрашивал Билла).
Узел факта (С), подобно другим, может быть разбит на две части — подлежащее
(F) и сказуемое (G). Но узел сказуемого тоже состоит из двух частей: в нем ассоциируются
отношение (H, глагол "спрашивать") и объект(I, "Билл").
Такова структура высказывания. Оно состоит из некоторого контекста и некоторого
факта (хотя иногда, напримерв таких высказываниях, как "Мыши едят сыр", контекст
может отсутствовать). Контекст (если он есть) слагается в свою очередь из места
и времени. Факт-это подлежащее плюс сказуемое, а сказуемое — отношение плюс
объект. В самой нижней строке схемы стоят единицы, не поддающиеся: дальнейшему
разложению. Они называются "терминальными узлами" (терминальными — потому, что
здесь ветвление заканчивается) . Эти узлы соответствуют основным понятиям ДП,
представленным здесь словами (точно так, как мы могли представить словами единицы
и свойства в модели ОСПЯ). Они служат для того, чтобы "привязать" высказывание
к ДП; это те фиксированные, точки, к которым можно присоединить любое число
деревьев. Таким образом, мы видим. что ДП подобна сети из таких деревьев (высказываний),
которые служат для ассоциации различных ячеек (соответствующих терминальным
узлам деревьев).
ПРОЦЕССЫ, ПРОТЕКАЮЩИЕ В МОДЕЛЯХ ОСПЯ И АПЧ
Итак, мы теперь знаем, что в сетевых моделях ДП обладает структурой, основанной
на ассоциациях. Но это лишь часть дела. Эти модели, равно как и любая другая
модель ДП, немногого достигнут, если все сведется к одной лишь структуре. Для
того чтобы имитировать поведение человека или предсказывать результаты экспериментов,
касающихся семантической памяти (которые будут рассмотрены несколько позже),
модель должна отображать также и процессы. Процессы действуют на структуру и
участвуют вместе с ней в кодировании, хранении и извлечении информации.
Например, в случае модели Куиллиана необходимо объяснить, каким
образом ОСПЯ приобретает новую информацию, т. е. истолковывает
лингвистические входы (что существенно для приобретения новой информации),
и отвечает на вопросы. Самый важный процесс, используемый с этой целью,
называется "поиском по пересечению". Допустим, что ОСПЯ пытается
понять следующее предложение, подаваемое на вход: "Волк может
укусить". В этом предложении названы некоторые понятия ("волк" и
"укусить"). Процесс поиска одновременно входит в ячейки ДП для каждого
из названных понятий, а затем следует по стрелкам, т. е. отходящим от
этих ячеек путям. Всякий раз, когда какая-та стрелка приводит к новому
понятию, это понятие получает метку, которая означает, что процесс поиска
прошел через данный пункт, и указывает, от какого понятия он сюда пришел. Возможно, что в какой-то момент один из путей поиска приведет к
понятию, которое уже было помечено (т. е. поиск уже приводил к нему раньше).
Эта точка представляет собой пересечение. Если найдено пересечение, это
значит, что данной точки можно достигнуть, ведя поиск от двух разных понятий, и, следовательно, эти два понятия как-то связаны между собой.
Проверив, имеется ли в данной точке метка и пройдя в обратном направлении
путь, приведший к пересечению, можно установить, какие именно понятия
пересекаются и как они связаны между собой. Если связь между понятиями в ДП совместима с их отношением во входном предложении, то
можно сказать, что данное предложение понято.
Поиск по пересечению в модели ОСПЯ иллюстрирует рис. 8.3. На нем изображена
часть сетевой структуры ДП (несколько более четко, чем на рис. 8.1, с указанием
всех элементов и свойств), содержащая понятия о некоторых животных и их свойствах.
Допустим, что мы ввели в ОСПЯ предложение "Канарейка есть рыба". Процесс поиска
начнется в точках, соответствующих элементам "канарейка" и "рыба". На пути от
"канарейки" будут помечены понятия "птица", "петь" и "желтый"; на пути от "рыбы"
— понятия "плавники", "плавать" и "животное". Наконец, когда поиск, идущий от
понятия "канарейка", достигнет понятия "животное", там будет обнаружена метка
с указанием на стрелку, ведущую сюда от понятия "рыба". Пройдя в обратном направлении
пути, .приведшие к "животному", можно выяснить отношение между понятиями "рыба"
и "канарейка". Оно несовместимо с их отношением в высказывании, которое утверждает,
что "канарейка есть рыба". Если бы, однако, это высказывание гласило, что "канарейка
родственна рыбе", то оно подтвердилось бы. Сходным образом результаты поиска
могли бы подтвердить, что "канарейка имеет кожу" (был бы найден путь от "канарейки"
к "птице", от "птицы" к "животному" и от "животного" к "коже"), или привести
к выводу, что "канарейка может летать" ("канарейка есть птица", а "птица может
летать").
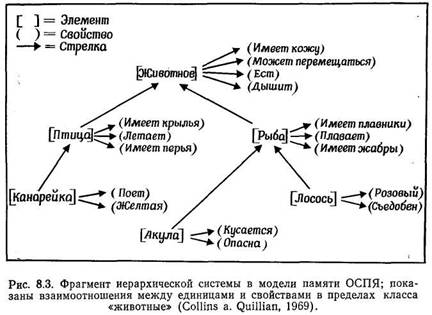
В модели АПЧ процесс, соответствующий поиск) по пересечению !B ОСПЯ, называется
процессом "сопоставления". Он изображен на рис. 8.4. Этот процесс имеет своей
целью связывать входную информацию с памятью, в результате чего модель получает
возможность интерпретировать эту информацию. Сначала система АПЧ пытается закодировать
входную информацию (например, какое-либо предложение), представив ее в виде
дерева, — процесс кодирования, называемый "разбором" входного сообщения. Затем
она сопоставляет терминальные — самые нижние — узлы схемы с соответствующими
ячейками в ДП. (Если во входном сообщении окажется незнакомое слово, оно не
сможет быть сопоставлено с определенной ячейкой ДП; тогда в ДП образуется новый
узел, представляющий в ней это слово, и начинается сбор информации об этом узле:
каково правописание этого слова, с какими словами оно ассоциируется в предложении
и каким образом.) Затем делается попытка найти в ДП дерево, сходное с входным
деревом. Такой поиск начинается от каждой ячейки ДП, соответствующей одному
из слов входного предложения; это .поиск в сети ДП путей, соединяющих терминальные
узлы таким же образом, как они соединены во входном сообщении. Иными словами,
требуется найти такое дерево ДП, которое соединяло бы те же понятия и таким
же образом, как и во входном сообщении. Когда такое дерево найдено, это значит,
что соответствие между входным сообщением и сетью ДП установлено и предложение
понято.
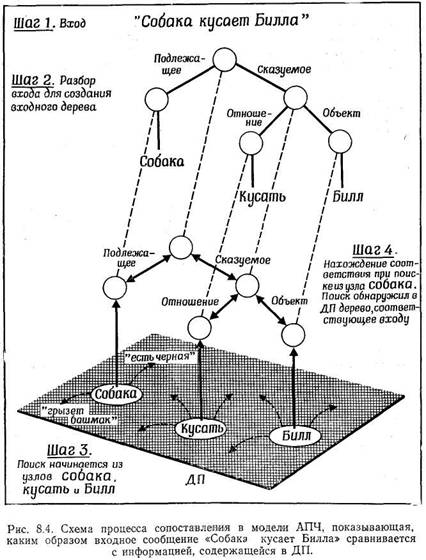
Тот же процесс может быть использован при входных сообщениях многих различных
типов, например при вопросах. Получив вопрос "Кто ударил Билла?", система произведет
грамматический разбор вопроса и построит входное дерево, в котором местоимение
"кто" будет рассматриваться как пропуск, подлежащий заполнению. Она будет пытаться
установить соответствие между остальными частями дерева и информацией, имеющейся
в памяти. Если в памяти найдутся сведения о том, что "Билла ударил Джон", система
сможет заполнить пропуск и дать ответ на вопрос. (Этот пример несколько тривиален,
но описанный метод можно распространить на более сложные случаи ответов на вопросы.)
Другая важная особенность метода сопоставления в модели АПЧ состоит в том, что
его можно распространить на нелингвистические входы, например "зрительные" (сцены).
Некоторые процессы в системе АПЧ предназначены для разбора или описания таких
входов путем построения деревьев, позволяющих выяснять, что это за входы. С
данным входом можно сопоставить имеющиеся в памяти описания, в результате чего
система получает возможность распознать предъявленную картину. Короче говоря,
процесс сопоставления выполняет много функций, так как это основной механизм,
который позволяет связывать текущий опыт с приобретенными ранее знаниями об
окружающем мире и играет тем самым главную роль в кодировании информации и в
ее извлечении.
ДАННЫЕ О СЕМАНТИЧЕСКОЙ ПАМЯТИ
Теперь, когда мы ознакомились с одним типом моделей ДП (а именно с сетевыми
моделями), уместно будет рассмотреть кое-какие данные, для объяснения которых
эти модели были созданы. В настоящей главе мы рассмотрим данные относительно
семантической памяти (эпизодической памяти мы коснемся в последующих главах).
Мы сможем оценить объяснительную силу ООПЯ, АПЧ и других моделей, когда увидим,
в какой мере они позволяют понять известные факты.
Как правило, при изучении семантической памяти имеют дело с "неэпизодической"
информацией, т. е. знаниями, существующими независимо от времени или места их
приобретения. Одним из лучших примеров такого рода информации служат определения
слов. Почти каждому известно, что "канарейка — птица" и что "все алмазы — камни".
Не удивительно поэтому, что определения слов использовались во многих экспериментах
по семантической памяти. Оддн из самых обычных методов, применяемых в таких
экспериментах, это задача на проверку истинности утверждения. Испытуемому предъявляют
некоторое утверждение и предлагают решить, истинно оно или ложно; например:
КАНАРЕЙКА — ПТИЦА1 (истинно) или КАНАРЕЙКА — РЫБА (ложно).
Как и
следовало ожидать, испытуемые выполняют такого рода задания с очень
небольшим числом ошибок. Зависимая переменная в таких заданиях-это время
реакции (ВР), определяемое обычно как интервал между предъявлением
утверждения и ответом испытуемого.
1Строго
говоря, следовало бы писать "канарейка есть некоторая птица", но в
данном контексте, где обсуждается вопрос о механизме понимания обычной
речи, мы будем переводить подобные утверждения упрощенной формой,
свойственной обычному языку. — Прим. ред.
ЭФФЕКТ ВЕЛИЧИНЫ КЛАССА
Из всех явлений семантической памяти, вероятно, наибольшее внимание исследователей
привлекает так называемый эффект величины класса. В типичном случае для изучения
этого эффекта используется задача на проверку истинности утверждения, имеющего
вид
(Некоторое подлежащее) (S) есть (Некоторое сказуемое) (Р).
Независимой переменной служит величина класса сказуемого Р. Под величиной
класса имеется в виду число входящих в него членов. Часто невозможно бывает
точно указать число членов, входящих в данный класс (но иногда это число совершенно
очевидно, например в случае класса "времена года", в который входит четыре члена).
Тем не менее всегда есть возможность определить относительную величину класса,
т. е. сказать, что один класс больше другого. Обычно об этом можно говорить
в тех случаях, когда один класс входит в другой; тогда, конечно, второй должен
быть больше первого. Например, класс "птицы" входит в класс "животные"; следовательно,
к классу "животные" относятся все "птицы" плюс что-нибудь еще, так что он должен
быть больше. Основной результат, к которому привели эксперименты по проверке
истинности утверждений, состоит в том, что ВР, необходимое для ответа "истинно",
возрастает с увеличением объема класса Р. Например, проверка утверждения "канарейка-животное"
занимает больше времени, чем проверка утверждения "канарейка-птица" (см., например,
Collins a. Quillian, 1969; Meyer, 1970). ВР для ложных утверждений также обычно
возрастает с увеличением класса Р (см., например, Landauer a. Freedman, 1968;
Meyer, 1970).
Эффект величины класса чрезвычайно важен для построения модели семантической
памяти. Суть его сводится к тому, что время, необходимое для проверки принадлежности
данного объекта (скажем, канарейки) к данному классу ("птицы"), зависит от величины
этого класса. А это в свою очередь говорит кое-что о природе семантической ДП,
так что любая разумная модель должна объяснять эффект величины класса. В случае
модели Куиллиана нетрудно дать ему довольно правдоподобное объяснение. В этой
модели предполагается, что данный объект связан с непосредственно стоящим над
ним высшим классом одной стрелкой; этот высший класс связан со стоящим над ним,
и так далее. Такова внутренняя структура ДП в данной модели. Для того чтобы
проверить истинность утверждения "канарейка — птица", надо пройти только по
одной стрелке, а чтобы добраться до более удаленного из высших классов, надо
уже пройти по двум таким стрелкам (см. рис. 8.3). Поскольку прохождение по стрелке
занимает определенное время, путь, соответствующий двум стрелкам, потребует
больше времени. В результате мы и получим эффект величины класса: чем выше положение
данного класса Р в иерархии, тем большее число стрелок нужно пройти и тем больше
это занимает времени.
Несколько труднее объяснить с помощью модели ОСПЯ, почему эффект величины класса
наблюдается и при проверке ложных утверждений (таких, например, как "маргаритка
рыба"). Действительно, ВР будет больше, если, например, заменить в приведенном
выше утверждении понятие "рыба" на "животное". Коллинз и Куиллиан (Collins a.
Quillian, 1970) предложили следующее объяснение. По их мнению, в большинстве
случаев эффект величины класса не проявляется. Он возникает только тогда, когда
S и Р связаны между собой (например, маргаритка, рыба и животные — это все живые
организмы). А если S и Р связаны, то они чаще всего будут связаны теснее, когда
Р — большой, а не малый по объему класс. Например, как можно видеть из рис.
8.3, "маргаритка" будет ближе (в смысле близости в иерархической системе) к
"животному", чем к "рыбе". Кроме того, если 5 и Р близки, в процессе поиска
могут возникать ошибки. При поиске может быть выявлено отношение, которое окажется
неподходящим. Чем больше класс Р, тем ближе отношение, тем легче здесь ошибиться
и тем больше потребуется времени, чтобы решить, что, несмотря на близость двух
данных понятий, утверждение ложно. Такое объяснение нельзя, однако, считать
адекватным, поскольку было показано (Landauer a. Meyer, 1972), что при проверке
ложных утверждений эффект величины класса проявляется даже тогда, когда степень
близости двух рассматриваемых понятий во всех случаях одинакова. Это было бы
особенно печально для модели ОСПЯ, если бы другие модели позволяли без труда
объяснить обнаруженный эффект, но они тоже не дают объяснения! Эффект величины
класса при проверке ложных утверждений создает затруднения для многих моделей.
Поэтому мы пока согласимся с тем, что идея, высказанная Коллинзом и Куиллианом,
может в общем служить объяснением зависимости ВР от величины класса.
ЭФФЕКТЫ СЕМАНТИЧЕСКОЙ БЛИЗОСТИ
Близость, упомянутая выше в качестве возможной причины эффектов величины класса
при проверке ложных утверждений, сама служит важным объектом исследований, касающихся
семантической памяти, особенно в экспериментах с предъявлением истинных утверждений.
В типичных работах по изучению этой "близости" испытуемым сначала предъявляют
набор, состоящий из пар слов. В каждой паре одно слово представляет собой название
какого-либо объекта, принадлежащего к данному классу, а другое — название этого
класса; например, объектом (представителем класса) может быть "малиновка", а
классом — "птицы". Испытуемого просят оценить, насколько типичен данный представитель
для данного класса или насколько близки два соответствующих слова (Rips а. о.,
1973; Rosch, 1973). Оценки типичности различных представителей для данного класса
варьируют довольно сильно. Например, "малиновка" оценивается как гораздо более
типичная "птица", чем "курица". Эти различия в оценках типичности составляют
один из тех фактов, которым теория семантической памяти должна дать объяснение.
В самом деле, "типичность" оказывается довольно серьезной проблемой для сетевой
модели, подобной ОСПЯ. В этой модели каждый представитель какого-либо класса
отделен от стоящего непосредственно над ним класса одной стрелкой. Поскольку
все члены данного класса отделены от названия класса одинаковым (равным одной
стрелке) расстоянием, трудно представить себе, отчего возникают различия в оценках
типичности. Модель АПЧ, созданная Андерсоном и Боуэром, позволяет лучше объяснить
эти и другие эффекты, которые, как .мы увидим, плохо согласуются с сетевыми
моделями. В данном случае модель АПЧ может объяснить явление типичности или
близости как результат происходящего в ДП процесса поиска (сопоставления). Как
вы помните, отправной точкой процесса сопоставления служит поиск, начинающийся
из каждой ячейки ДП, упомянутой во входном сообщении; цель этого процесса —
найти дерево, которое соответствовало бы входному сообщению. Поиск начинается
одновременно с разных ячеек и ведется параллельно; однако из каждой отдельной
ячейки одновременно можно вести поиск только по одному пути. А так как обычно
от каждой ячейки ДП идет много путей, предполагается, что среди них устанавливается
некая очередность; она определяет последовательность, в которой производится
поиск по разным путям, идущим от данной ячейки. Наиболее важные пути обследуются
в первую очередь. Это позволяет модели АПЧ учесть влияние "типичности" на истинное
время реакции, так как есть определенная зависимость между типичностью и очередностью.
Оказывается, чем более типичен данный представитель для данного класса, тем
выше вероятность того, что соединяющие их пути занимают одно из первых мест
в списке очередности. Если допустить, что оценки типичности, или близости, основываются
на отношениях очередности, то эта модель позволит без труда объяснить причины
различий в оценках.
Не удивительно, что близость влияет на ВР в задачах попроверке истинности утверждений
(Smith, 1967; Wilkins, 1971). Чем теснее связаны S и Р, тем быстрее проверяется
истинность утверждений типа "некоторое S есть Р". Так, например, испытуемые
проверяют истинность того, что "голубь — птица", быстрее, чем того, что "курица
— птица". Удивительно другое: эффекты близости позволяют предсказать ситуации,
в которых эффект величины класса не будет проявляться. Рассмотрим следующий
пример (Rips а. о., 1973). Класс ".млекопитающие" входит в класс "животные",
так что класс "животные" больше по своему объему. Однако по оценкам испытуемых
некоторые млекопитающие (например, "медведь" или "кошка") более типичны для
класса "животные", чем для класса "млекопитающие". И если сравнить ВР для проверки
утверждений "медведь — млекопитающее" и "медведь — животное", то окажется, что
во втором случае оно короче. Это расходится с предсказанием о влиянии величины
класса (поскольку класс "животные" более обширен, ВР при его проверке, казалось
бы, должно быть больше), но соответствует оценкам типичности. Такой результат
опятьтаки создает затруднение для модели ОСПЯ (но не для модели АПЧ, которая
позволяет объяснить его на основе очередности при поиске: чем теснее близость
между S и Р, тем раньше начнется обследование соответствующих путей и тем быстрее
утверждение может быть проверено).
ТЕОРЕТИКО-МНОЖЕСТВЕННАЯ МОДЕЛЬ ДП
До сих пор мы рассмотрели лишь один тип моделей семантической ДП — сетевые
модели. Существуют, однако, модели иного типа, и мы сейчас рассмотрим одну из
них, известную под названием "теоретико-множественной" (Meyer, 1970). В основе
ее лежит предположение, что семантические классы представлены в ДП как множества,
или совокупности, элементов информации. Это могут быть множества представителей
какого-либо класса (например, к классу "птицы" относятся малиновки, соловьи,
воробьи и т. д.). Это могут быть также множества атрибутов или свойств данного
класса (например, птицы имеют крылья, имеют перья, могут летать и т. д.). Иными
словами, та или иная категория представлена в ДП в виде некоторого набора информации.
Мейер (Meyer, 1970) использовал теоретико-множественную модель, чтобы объяснить
различия во времени, затрачиваемом испытуемыми для проверки утверждений типа
"все S суть Р" или "некоторые S суть Р" (например, "все камни — рубины" или
"некоторые камни — рубины"). Для объяснения данных относительно ВР он предложил
двухфазную модель, описывающую процесс выполнения такой задачи. Согласно этой
модели, испытуемый, которому предъявили такого рода утверждение, сначала перебирает
названия всех множеств, которые пересекаются (т. е. перекрываются, имеют общих
членов) с классом Р. Например, в случае утверждения типа "все S суть писатели"
испытуемый начнет искать множества, перекрывающиеся с множеством "писатели".
Он может обнаружить такие множества, как "женщины", "мужчины", "люди", "профессора"
и т. д., в каждом из них имеются члены, которые суть писатели. Если в этих множествах
будут обнаружены элементы класса S (будет выявлен факт пересечения этих множеств
с классом S), то первая стадия завершится установлением соответствия. Если же
при поиске не будет обнаружено соответствия с классом S, то результатом первого
этапа будет отрицательный ответ.
Если на первом этапе проверки будет обнаружено соответствие, то это означает,
что классы S и Р имеют некоторых общих членов. Этого было бы достаточно, чтобы
убедиться в истинности утверждения типа "некоторые S суть Р", но недостаточно
для проверки утверждения типа "все S суть Р". В последнем случае необходимо
провести второй этап: сравнение всех атрибутов Р с атрибутами S. Если каждый
атрибут Р является также одним из атрибутов S, то утверждение можно признать
истинным. Если же нет, то испытуемый дает отрицательный ответ.
Возьмем конкретный пример. Допустим, что Р — это "драгоценные камни". Рассмотрим
теперь утверждение "некоторые минералы суть драгоценные камни". На первом этапе
проверки просматриваются множества, которые пересекаются с множеством "драгоценные
камни" (т. е. имеют с ним общих членов). К их числу относятся такие классы,
как "алмазы", а также "минералы", поскольку многие минералы суть одновременно
и драгоценные камни. Таким образом, истинность утверждения может быть проверена.
Если бы слово S было "птицы" ("некоторые птицы суть драгоценные камни"), первый
этап привел бы к отрицательному ответу, поскольку ни один из членов класса "птиц"
не является членом также и класса "драгоценных камней". Если же проверяется
истинность утверждения "все рубины суть драгоценные камни", то тогда на первом
этапе будет обнаружено соответствие. Однако наличие слова "все" потребует проведения
также и второго этапа. Для этого придется сравнить все атрибуты драгоценных
камней (они дорого стоят, используются в ювелирном деле и т. д.) с атрибутами
рубинов. Если атрибуты тех и других совпадают — а в данном случае это так и
есть, ибо рубины тоже стоят дорого, используются в ювелирном деле и т. д., —
то истинность утверждения установлена. Если же нет, как в случае "все писатели
— женщины", то утверждение будет отвергнуто. В последнем случае на первом этапебудет
обнаружено соответствие, поскольку множество "писатели" пересекается с множеством
"женщины", но на втором этапе будет получен отрицательный ответ.
Теоретико-множественная модель типа мейеровской позволяет объяснить эффекты
величины класса, подобные тем, которые были рассмотрены выше. Чтобы это понять,
мы должны сначала указать на принятое в этой модели предположение о неслучайности
поиска пересекающихся классов, производимого на первом этапе. Классы, пересекающиеся
с Р, обследуются в порядке, соответствующем степени пересечения, причем наиболее
сильно пересекающиеся классы проверяются в первую очередь. Это означает, что
чем меньше число членов, не являющихся общими для S и Р, тем быстрее будет обнаружен
на первом этапе факт пересечения S и Р, так как он выявится на более ранней
стадии обследования всех тех .классов, которые пересекаются с Р. Тем самым получает
объяснение эффект величины класса: чем больше Р по сравнению с S, тем меньше
они будут пересекаться и тем больше потребуется времени для нахождения S на
первом этапе поисков. Например, если S — "канарейки", а Р — "птицы", то пересечение
S и Р сильнее, чем в том случае, если Р — "животные" (этот класс больше, чем
класс "птицы"). Таким образом, если Р — "птицы", то при обследовании пересекающихся
с Р классов "канарейки" будут обнаружены быстрее и время реакции будет меньше,
чем если Р — "животные". Это и приведет к обычному эффекту величины класса.
Однако модель Мейера не объясняет нарушения эффектов величины, наблюдаемого
в тех случаях, когда величина не соответствует близости (см. Rips а. о" 1973);
почему, например, в случае "кошка — млекопитающее" проверка занимает больше
времени, чем в случае "кошка — животное"?
МОДЕЛЬ ДП, ОСНОВАННАЯ НА СЕМАНТИЧЕСКИХ ПРИЗНАКАХ
Одна из моделей, порожденных теоретико-множественным подходом, — это модель
Смита, Шобена и Рипса, основанная на семантических признаках (Rips а. о., 1973;
Smith а. о., 1974). Преимущество ее состоит в том, что она может объяснить обсуждавшиеся
выше эффекты близости, т. е. позволяет понять, почему степень близости лучше
коррелирует с временем реакции, наблюдаемым при проверке, чем величина класса,
и почему "типичность" различных представителей для данного класса, измеряемая
по реакции испытуемых, может варьировать. В модели, основанной на семантических
признаках, тот или иной семантический класс может быть представлен в ДП как
набор атрибутов, или признаков. Кроме того, предполагается, что набор признаков
очень обширен и включает как признаки, существенные для определения данного
класса, так и относительно маловажные признаки. Скорее всего признаки данного
класса образуют непрерывный ряд от очень важных для его определения до несущественных.
Возьмем, например, слово "малиновка". Оно может быть представлено в ДП в виде
совокупности следующих признаков: "двуногие", "имеют крылья", "имеют красную
прудку", "сидят на деревьях", "не приручены". Первые три признака, вероятно,
более важны для определения понятия "малиновка", чем два последних. (Конечно,
этот перечень неполон, но в принципе мы могли бы иметь исчерпывающий набор признаков,
характеризующих значение слова "малиновка".)
Обычно на такой непрерывной шкале признаков можно выбрать произвольную точку,
отделяющую более важные (определительные) признаки от менее важных
(всего лишь характерных). В модели, основанной на признаках, определительным
признакам придается большее значение в задачах проверки истинности, чем характерным
признакам. (В нашем примере с "малиновкой" первые три признака можно считать
определительными, а остальные-характерными.)
Рассмотрим теперь, как могли бы изменяться наборы признаков при переходе от
названия такого класса, как "малиновки", к стоящему над ним классу "птицы".
Поскольку понятие "птица" более абстрактное, более общее, у него будет меньше
определительных признаков. В самом деле, поскольку все малиновки относятся к
птицам, все определительные признаки понятия "птица" должны быть также приложимы
к понятию "малиновка", а у малиновки должно быть, кроме того, еще много своих
дополнительных признаков. Вообще чем более абстрактна данная категория, тем
меньше будет у нее определительных признаков.
Выше были указаны главные предположения о структуре ДП, принимаемые в модели,
основанной на признаках. Ее центральная идея -существование семантических признаков,
которые могут в сочетании друг с другом передавать смысл понятий, — не нова
ни для лингвистов, ни для психологов(см., например, Katz a. Fodor, 1963; Miller,
1972; Osgood, 1952). Новое в модели Смита, Шобена и Рипса — это предполагаемый
характер семантических признаков и связанный с ним способ интерпретации данных,
получаемых при изучении семантической памяти. Кроме того, авторы модели попытались
сами получить экспериментальные результаты, подтверждающие мысль о роли признаков.
Рипс и его сотрудники (Rips а. о., 1973) собрали "оценки близости" для групп
понятий, т. е. данные о том, насколько тесно ассоциируютсяразличные представители
некоторого класса (например, курица, утка, воробей и т.п.) с названием этого
класса (птицы) и между собой. Эти оценки можно представить в виде расстояний.
Например, высокие оценки близости между двумя понятиями можно отобразить как
малые расстояния между ними. Существуют даже машинные методы для перевода таких
оценок сходства в расстояния. Эти методы позволяют предста.вить различные понятия
точками в гипотетическом многомерном пространстве. Расстояния между точками
в этом пространстве можно интерпретировать как "психологические" расстояния
между соответствующими понятиями. И действительно, эти расстояния отражают (в
обратном соотношении) первоначальные оценки сходства: чем ближе расположены
точки для двух понятий, тем более сходными кажутся нам эти понятия. Кроме того,
размерность получающегося пространства позволяет судить о психологической основе
оценок близости.
На рис. 8.5 показаны двумерные пространства, построенные на основании оценок
близости понятий "птица" и "млекопитающее". Рипс и его сотрудники интерпретируют
эту схему следующим образом. Они предполагают, что при первоначальных оценках
близости испытуемые опирались на хранящиеся в ДП семантические признаки: о близости
двух понятий они судили по наличию у них общих признаков. А это в свою очередь
означает, что координаты получаемых двумерных пространств могут указывать на
те семантические признаки, которые использовались испытуемыми при оценке близости.
Создается, например, впечатление, что горизонтальная ось нa рис. 8.5 соответствует
величине объекта. В пространстве птиц ястреб и орел — крупные птицы — находятся
у левого края, а такие мелкие птички, как малиновка, у правого края. В пространстве
млекопитающих крупные животные — олень и медведь — тоже оказываются на одной
стороне, а мышь — на другой. Вертикальную ось в обоих пространствах можно связать
с чем-то вроде "хищности", понимая под этим степень, в которой данные животные
используют в качестве пищи других. В пространстве млекопитающих дикие и домашние
животные находятся на противоположных концах этой оси; в пространстве птиц хищные
виды отделены от домашних. Поскольку эти два пространства были получены независимо
одно от другого, их однотипность — факт весьма примечательный; он говорит в
пользу того, что соответствующие координаты служат неизменной основой для оценок
близости. В данном случае эти оценки, очевидно, базировались на семантических
признаках, связанных с величиной и хищничеством.
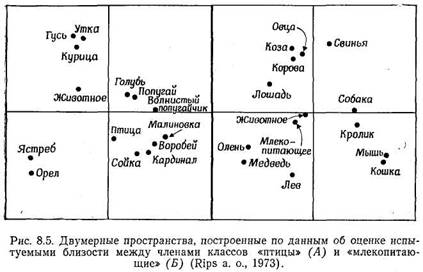
Модель, основанная на признаках, позволяет объяснить многие из упоминавшихся
нами данных о семантической памяти. Для того чтобы понять это, нужно рассмотреть
предполагаемые в этой модели процессы, с помощью которых проверяется истинность
утверждений. Сначала, однако, следует напомнить о постулируемой структуре
информации в ДП. В модели предполагается, что каждое понятие представлено перечнем
признаков. Эти признаки образуют непрерывный ряд от самых важных до наименее
существенных. Положение признака в этом ряду мы будем называть его весом (таким
образом, вес показывает, насколько важен тот или иной признак для определения
данного понятия; его значение тем больше, чем выше вес). На шкале весов можно
произвольно выбрать какую-то точку и считать все признаки с большим весом "определительными",
а с меньшим — "характерными". Согласно модели, проверка истинности утверждения
типа "все S суть Р" происходит следующим образом. Первый этап процесса распадается
на три подэтапа. Сначала из ДП извлекаются перечни признаков, соответствующих
классам S и Р, хотя эти перечни не обязательно должны быть полными, они содержат
как определительные, так и характерные признаки. Затем признаки, входящие в
эти два перечня — один для S, а другой для Р, — сравниваются между собой; число
совпадающих признаков служит основой для выведения меры общего сходства — назовем
ее х. И наконец, х используется для того, чтобы решить, каков результат этого
первого этапа. Если значение х очень велико — превышает определенную пороговую
величину, — то, значит, S и Р настолько сходны, что система сразу же дает ответ
"утверждение истинно". Если значение х очень мало (что говорит об отсутствии
сходства между S и Р), модель дает ответ "ложно". Если же х имеет промежуточную
— не низкую и не высокую — величину, то проводится второй этап процесса.
На втором этале используются только определительные признаки понятий S и Р.
Это как бы вторая проверка; она основана на предположении о частичном сходстве
между S и Р, и ее цель состоит в выяснении природы этого сходства. Если определительные
признаки Р совпадают с определительными признаками S, то может быть выдан положительный
ответ; в противном случае ответ будет отрицательным. Из всего этого следует,
что средние значения времени реакции для ответов в задачах на проверку истинности
утверждений на самом деле складываются из смеси малых (при очень сходных или
очень несходных S и Р) и больших (когда необходима вторая стадия) величин.
Одно из преимуществ модели, основанной на признаках, состоит в том, что она
позволяет объяснить зависимость ВР от типичности или близости. Согласно этой
модели, чем более типичен данный представитель для данного класса, тем больше
у них общих признаков. Следовательно, значение х — меры сходства, основанной
на числе общих признаков у S и Р, — возрастает с увеличением типичности. При
высоких значениях х повышается вероятность того, что уже на первом этапе сравнения
будет получен положительный ответ. Это означает, что с увеличением типичности
ВР будет уменьшаться.
Эта модель объясняет также эффекты величины класса нужно лишь .предположить
вторичность их по отношению к эффектам близости. В большинстве случаев увеличение
размеров класса Р приводит к уменьшению близости между S и Р и к удлинению времени
реакции (ВР). Если, например, S — "воробей", то при переходе от значения Р-"птица"
к значению "животное" сходство между S и Р уменьшится и соответственно ВР возрастет.
В других же случаях, например при увеличении Р с переходом от значения "млекопитающее"
к значению "животное", такое же изменение величины класса приведет, наоборот,
к сближению S и Р; в этом случае ВР сократится. В связи с этим Смит, Шобен и
Рипс приходят к выводу, что эффект величины класса выражен не так сильно, как
это предполагалось. Он варьирует довольно значительно, и его скорее можно приписать
изменениям близости S и Р, сопровождающим изменения величины класса.
Итак, мы рассмотрели три типа моделей семантической памяти: сетевые модели,
теоретико-множественные модели и модель, основанную на семантических признаках.
Каждый тип был рассмотрен в связи с двумя интенсивно изучавшимися явлениями
— эффектом величины класса и эффектом близости. Как можно было убедиться, эти
модели во многих отношениях сходны. Например, во всех этих моделях любое понятие
приобретает определенный смысл в результате своих отношений с другими понятиями,
будь то ассоциации, включение одних понятий в другие в качестве подмножеств
или же использование их в качестве признаков. Все эти модели позволяют объяснить
многие из представленных здесь данных о семантической памяти, хотя каждая из
них обладает своими специфическими возможностями. Должно быть также ясно, что
между сетевыми и теоретико-множественными моделями есть ряд существенных различий;
одно из самых важных различий касается того, что эти модели пытаются объяснить.
Теоретико-множественная модель Мейера и модель Смита, Шобена и Рипса предназначены
для истолкования данных, полученных в определенного рода экспериментах по изучению
семантической памяти. Сетевые же модели могут быть связаны с гораздо более обширным
кругом данных. Например, модель АПЧ пытается объяснить результаты, относящиеся
к столь разнообразным областям, как лингвистические способности, забывание,
восприятие, распознавание образов, научение и другие. Ввиду столь широкого охвата
проблем сетевые модели могут быть полезны при изучении многих явлений не только
семантической, но и эпизодической памяти; поэтому такие модели будут использованы
при обсуждении многих проблем в последующих трех главах.
Теоретико-множественные модели в данный момент не позволяют объяснить явления
эпизодической памяти. Оговорка "в данный момент" весьма существенна. Дело в
то.м, что исследования в области семантической памяти развиваются необычайно
быстро. Обсуждая исследования или модели, подобные описанным в этой главе, невозможно
учесть все изменения, которые происходят непрерывно. Кроме того, все время разрабатываются
и ставятся новые эксперименты, результаты которых требуют объяснения с помощью
моделей. Все это делает проблему семантической памяти одной из самых динамичных
и увлекательных областей психологических исследований.
Глава 9
Долговременная память: забывание
Что имеют в виду, когда говорят о забывании какой-либо информации, хранившейся
в ДП? Ответить на этот вопрос не так-то просто, отчасти потому, что забывание,
очевидно, может принимать очень разнообразные формы. Вы, например, не можете
вспомнить, что происходило в тот день, когда вам исполнился год, хотя возможно,
что день вашего рождения праздновался. Человек вообще не помнит всего того.
что с ним происходило в младенчестве и раннем детстве. Поскольку в этом возрасте
человек еще не обладает развитой речью, у него нет вербальных кодов, которые
могли бы храниться в ДП; поэтому забывание событий, происходивших в ранний период
жизни, может в корне отличаться от забывания, наблюдаемого в зрелом возрасте.
Но и у взрослого человека забывание может носить весьма различный характер.
Существует, например, так называемое "обыкновенное" забывание, когда человек
забывает купить что-то в магазине, не приходит на свидание или не может заполнить
один из пунктов во время какого-либо теста. Существует забывание в результате
физической травмы — амнезия. Известно также явление репрессии — намеренного
забывания событий, воспоминание о которых причиняет душевную боль.
Ввиду такого многообразия значений мы попытаемся,
прежде чем перейти к рассмотрению забывания, дать ему какое-то
определение. Назовем забыванием то, что происходит, когда материал,
который был когда-то закодирован и который затем нужно отыскать, не удается
извлечь из памяти. (Необходимо уточнить, что искомый материал был когдато закодирован,
чтобы исключить из понятия "забывание" неспособность припоминать события, восприятие которых не
дошло даже до
стадии распознавания образов.) Это довольно широкое определение, однако
широта необходима для того, чтобы в него можно
было включить все разнообразные типы забывания, которые можно наблюдать.
Иногда забытый материал не удается извлечь даже частично (как, например,
в тех случаях, когда человек не может вспомнить французское слово,
означающее "книга", после того как он заучил его для последующей
проверки); забывание может быть также частичным (как в тех случаях, когда
забытые слова "вертятся на кончике языка"); иногда забывание
принимает даже форму искажения (когда человек припоминает не то, что произошло на самом деле; например, один из водителей, участников уличного
происшествия, может "вспоминать" после аварии, что другой водитель
допустил грубейшее нарушение, хотя свидетели могут с ним не соглашаться).
Подобные случаи также соответствуют нашему общему определению забывания, поскольку и здесь то, что может быть извлечено из
ДП, не
совпадает с тем, что нужно было вспомнить.
ПРОАКТИВНОЕ И РЕТРОАКТИВНОЕ ТОРМОЖЕНИЕ
Забывание из долговременной памяти изучалось обычно при помощи двух методов,
описанных в гл. 6, — методов ПТ и РТ. Здесь эти методы будут рассмотрены более
подробно. Напомним, что о проактивном торможении (ПТ) говорят в случае забывания
какого-либо материала в результате интерференции со стороны другого материала,
заученного ранее. Ретроактивным торможением (РТ) называют забывание, вызванное
материалом, заученным позже. Эти два вида интерференции изучались главным образом
в экспериментах с использованием парных ассоциаций.
Прежде чем продолжить наше обсуждение, необходимо договориться о некоторых
обозначениях. Назовем список парных ассоциаций, в котором стимулы берутся из
множества А, а реакции — из множества В, "списком А — В". Если, например, А
— компонентами служат трехбуквенные слоги (согласная — гласная — согласная),
а В — компонентами-цифры, то список А — В будет состоять из таких элементов,
как, например, ДАК-7 или СЕВ-3. Подобным же образом А — С означает список парных
ассоциаций, в котором стимулами служат те же компоненты (А), что и в списке
А — В, а реакциями — другие, взятые из множества С. Например, если С — компонентами
служат буквы алфавита, то в списке А возможны такие элементы, как ДАК-Б или
СЕВ-X. Используя эти обозначения, можно представить методы ПТ и РТ так, как
это сделано на рис. 9.1.
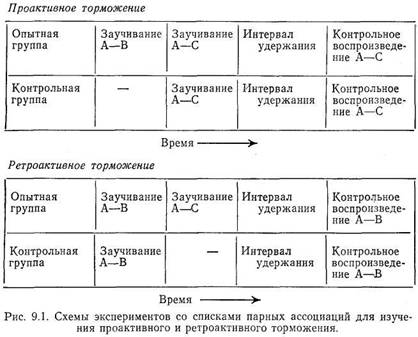
При обоих методах, как ПТ, так и РТ, опытная группа испытуемых заучивает список
парных ассоциаций А — В, пока не будет достигнут определенный уровень запоминания
(обычно критерием служит несколько безошибочных воспроизведений списка). Затем
они заучивают список А — С; в нем стимулы представлены теми же компонентами,
что и в первом списке, а реакции — другими компонентами. По прошествии интервала
удержания испытуемые снова воспроизводят один из списков. При изучении проактивного
торможения (ПТ) контрольное воспроизведение триводится по списку А — С. Контрольная
группа испытуемых заучивает только список А — С (или иногда заучивает перед
списком А — С несходный с ним список Х — Y), а затем по прошествии такого же
интервала удержания воспроизводит список А — С. ПТ определяется как интерференция,
проявляющаяся у испытуемых опытной группы в результате заучивания списка А —
В. В этом случае можно выразить ПТ количественно, установив, насколько воспроизведение
в опытной группе было хуже, чем в контрольной. В соответствии с этим ПТ определяют
как разность между средним /процентом верных воспроизведений по списку А — С
в контрольной группе ,и средним процентом верных воспроизведении в опытной группе,
деленную на процент верных воспроизведений в контрольной группе (деление позволяет
учесть трудность воспроизведения данного списка А — С; благодаря этому оценка
ПТ становится сравнимой с оценками по другим опискам). Если, например, правильное
воспроизведение в контрольной группе составляет в среднем 75%, а в опытной —
50%, то
ПТ=(75-50)/75= 1/3=33%.
Метод измерения ретроактивного торможения отличается от описанного для ПТ лишь
тем, что при контрольном воспроизведении опытная группа должна припоминать первый
заученный список вместо второго, поскольку нас интересует ухудшение воспроизведения
первого списка под влиянием заучивания второго списка. Поэтому опытная группа
заучивает список А — В, а затем список А — С, после чего приступает к контрольному
воспроизведению списка А — В. Контрольная группа заучивает список А — В, а затем
не делает ничего (или в некоторых экспериментах заучивает совершенно несходный
список Х — Y), после чего приступает к контрольному воспроизведению списка А
— В. В этом случае испытуемые опытной группы, воспроизводя список А — В, также
допустят больше ошибок, чем испытуемые контрольной группы; соответственно РТ
количественно определяют как разность между средними процентами верных воспроизведений
в контрольной и опытной группах, деленную на процент верных воспроизведений
в контрольной группе.
Самая главная особенность экспериментов с ПТ и РТ — то, что
в обоих случаях снижается эффективность воспроизведения у испытуемых опытной
группы. Поэтому мы можем рассматривать обе процедуры как средства, позволяющие
вызывать забывание: многие теоретики полагают даже, что забывание, вызываемое
в лабораторных условиях, в основе своей не отличается от забывания той или иной
информации в повседневной жизни. Другая важная особенность ПТ и РТ состоит в
том, что степень интерференции зависит от числа проб, проводимых по интерферирующему
списку (Briggs, 1957; Underwood a. Ekstrand, 1966) (интерферирующий список —
это список, который предъявляют опытной, но не контрольной группе). Иными словами,
степень ПТ или РТ варьирует в зависимости от числа проб, проводимых с опытной
группой по интерферирующему списку. В случае ПТ это список А — В, а в случае
РТ — список А — С.
ИНТЕРФЕРЕНЦИЯ И ЗАБЫВАНИЕ
Гипотезы относительно механизма проактивного и ретроактивного торможения обычно
считают приложимыми к забыванию любого типа. Их объединяют под общим названием
интерференционной теории забывания. Существует несколько таких гипотез, и в
этой главе мы рассмотрим некоторые из них. Однако, прежде чем заняться этим,
следует указать на два момента, которые необходимо иметь в виду. Во-первых,
эти гипотезы в большинстве случаев основаны на традиционном подходе "стимул
— реакция", и некоторые из них пытаются трактовать забывание в плане "прочности
навыка". Поэтому они иногда будут казаться чуждыми нашему понимацию. Это, однако,
не означает, что представление об интерференции ничего не дает для объяснения
процессов забывания из ДП. Это лишь значит, что используемая в теориях интерференции
терминология иногда может показаться неподходящей; в тех случаях, где возможна
путаница, мы попытаемся привести эту терминологию в соответствие с нашим информационным
подходом. Во-вторых, важно помнить, что большинство экспериментов, которые нам
предстоит рассмотреть, относятся к забыванию из эпизодической памяти. Тульвинг
(Tulving, 1972) высказал мнение, что семантическая информация забывается не
так легко. Поэтому следует все время иметь в виду, что забыть слово "лягушка"
в качестве реакции на стимул ДАК — это, вероятно, нечто совсем иное, чем забыть,
что представляет собой лягушка.
КОНКУРЕНЦИЯ РЕАКЦИЙ
Одной из первых гипотез относительно забывания информации, хранящейся в ДП,
была гипотеза Мак-Гоха о конкуренции реакций (McGeoch, 1942). В ней забывание,
связанное с проактивным и ретроактивным торможением, довольно прямолинейно интерпретировалось
в терминах концепции "стимул — реакция". По сути дела эта гипотезы сводилась
к тому, что при заучивании списка А — В и списка А мы создаем ассоциации разной
прочности для каждого компонента-стимула образуется по две ассоциации, одна
из которых прочнее другой. Когда испытуемому предъявляют при контрольном воспроизведении
компонент — стимул, две реакции вступают в конкуренцию и более прочная ассоциация
побеждает, препятствуя проявлению более слабой. Например, если в списке А —
В имеется парная ассоциация ДАК-7, а в списке А — С — ассоциация ДАК-8, то может
возникнуть внутренняя структура такого типа:

В этом случае при воспроизведении, когда испытуемому предъявляют ДАК-?, он ответит
"8". В экспериментах с проактивным или ретроактивным торможением более прочной
может оказаться реакция, относящаяся к интерферирующему, а не к контрольному
списку.
Основное возражение против гипотезы Мак-Гоха связано с вытекающим из нее предсказанием,
что ошибки испытуемых должны выражаться в форме "вторжений" из интерферирующего
списка; если испытуемый ошибается, то на стимул ДАК он ответит "8" (хотя верным
ответом было бы "7"), потому что в интерферирующем описке был элемент ДАК-8.
Он не ответит "2" или "16" и не назовет еще какоелибо случайное число. Однако
на самом деле ошибки носят другой характер (Melton а. lrwin, 1940). Чтобы убедиться
в этом, взгляните на рис. 9.2. Вы увидите, что ретроактивное торможение (РТ)
(и соответственно число ошибок при воспроизведении контрольного списка) возрастает,
а затем слегка уменьшается с увеличением числа проб по интерферирующему списку.
Однако "ошибки вторжения" изменяются поиному: РТ, которое можно отнести на счет
вторжений, уменьшается с увеличением числа проб по интерферирующему списку,
в то время как суммарное РТ продолжает возрастать.
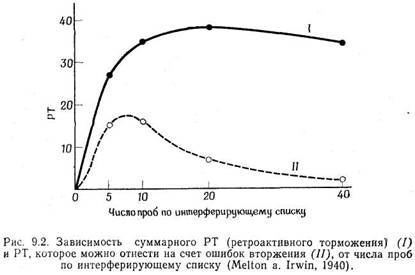
УГАСАНИЕ
Другая
гипотеза, предложенная для объяснения проактивного и ретроактивного
торможения, — это гипотеза угасания (Melton a. lrwin, 1940; Underwood,
1948a, b). Согласно этой гипотезе, важную роль в забывании играет распад
ассоциаций в результате интерференции. Иногда этот распад сравнивают
с угасанием, наблюдаемым в экспериментах с обычными условными рефлексами.
Для того чтобы получить представление о том, что такое угасание, опишем
вкратце классические опыты с выработкой условных рефлексов.
Используя стандартный метод, можно выработать у собаки условнорефлекторное
выделение слюны в ответ на определенный звуковой сигнал. Когда на собаку воздействуют
безусловным раздражителем, он вызывает желаемую реакцию без предварительной
тренировки животного (для слюноотделения таким раздражителем может быть пища).
Такой безусловный раздражитель применяют в сочетании с условным — в данном случае
со звуковым сигналом: сначала сигнал, а затем безусловный раздражитель, после
чего у собаки возникает реакция (подача безусловного раздражителя с последующей
реакцией на него называется подкреплением). Такая процедура, повторяемая несколько
раз, приводит к образованию условного рефлекса: в конечном результате реакция
возникает уже в ответ на один только условный стимул — непосредственно следует
за ним без всякого предъявления пищи. Такую реакцию называют обусловленной.
Но сохраняется ли это состояние навсегда? Допустим, что мы многократно предъявляем
условный раздражитель, не подкрепляя его безусловным. Вначале это по-прежнему
приводит к выделению слюны, но постепенно реакция ослабевает и в конце концов
исчезает. В таких случаях говорят, что произошло угасание в результате неподкрепления.
После этого может наступить третья фаза — спонтанное восстановление условного
рефлекса. Если дать собаке некоторое время отдохнуть, не предъявляя ей ни условного,
ни безусловного стимула, а затем вновь применить звуковой сигнал, то окажется,
что собака опять реагирует на него выделением слюны. По-видимому, угасание на
самом деле не было окончательным. В таких случаях говорят о самопроизвольном
восстановления угасшего условного рефлекса, в результате чего он вновь возникает
в ответ на звуковой сигнал. Рефлекс, однако, может опять угаснуть, если продолжать
предъявление звукового сигнала без подкрепления, или же восстановиться, если
сопровождать сигнал подкреплением.
Эти три фазы — выработка рефлекса, угасание и спонтанное восстановление — используются
для объяснения забывания при заучивании парных ассоциаций. Для того чтобы понять,
как они используются, рассмотрим рис. 9.3, где представлена теоретическая кривая
изменений, происходящих с течением времени в эксперименте с проактивным или
ретроактивным торможением. Сначала испытуемый заучивает не список, некоторый
список А — В; полагают, что у него при этом вырабатываются реакции на стимульные
компоненты этого списка, подобно тому как у собаки вырабатывается реакция слюноотделения
на звуковой сигнал. Затем испытуемый заучивает список А — С; теперь С-реакции
стали для него условными, а заученные ранее В-реакции угасли, так как они не
подкреплялись. Однако во время интервала удержания произойдет спонтанное восстановление
реакций А — В. В результате при проведении проб по списку А — С у испытуемого
будет наблюдаться проактивное торможение: относительное повышение эффективности
реакций то списку А — В на протяжении интервала удержания приведет к относительному
снижению эффективности в пробах по списку А — С. Это снижение, по-видимому,
вызывается конкуренцией между реакциями В и С на стимулы А. Если же проводить
пробы по списку А — В, то при этом, несомненно, будет обнаружено снижение эффективности,
вызванное заучиванием списка А — С, которое приводит к угасанию А — В. Таким
образом, при этом будет наблюдаться ретроактивное торможение.
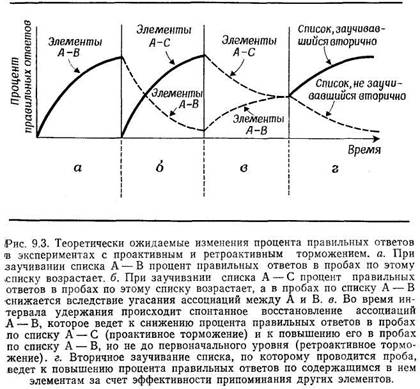
Подводя итоги, можно сказать, что согласно гипотезе угасания, при заучивании
списков А — В и А — С и последующих пробах по этим спискам ассоциации А — В
угасают во время заучивания списка А — С. Как полагают, это происходит в результате
того, что предъявление А — компонентов во время заучивания списка А — С вызывает
припоминание В-реакций, которые, однако, не получают подкрепления. Тем не менее
во время интервала удержания будет наблюдаться некоторое самопроизвольное восстановление
В-реакций. Во время проверочных проб при предъявлении стимула А реакции В и
С будут конкурировать между собой (примерно так, как это предсказывает гипотеза
Мак-Гоха), причем как сама конкуренция, так и ее исход зависят от относительной
прочности тех и других ассоциаций. (Конкуренцию между реакциями рассматривают
как второй — наряду с угасанием фактор, обусловливающий забывание, и соответственно
эту гипотезу иногда называют двухфакторной.)
Двухфакторная гипотеза породила такое огромное количество экспериментальных
работ, что дать их полный обзор было бы непосильной задачей. Не пытаясь охватить
всю эту область исследований в целом, мы здесь рассмотрим лишь некоторые эксперименты
и теоретические построения, ставшие "классическими". (В качестве одного из современных
обзоров можно рекомендовать работу Postman a. Underwood, 1973, где дана также
библиография по данной проблеме.)
Из двухфакторной гипотезы очевидным образом вытекает, что степень проактивного
и ретроактивного торможения, наблюдаемого во время проб, должна зависеть от
интервала удержания. Поскольку прочность ассоциаций А — В в период: удержания
возрастает, это будет приводить ко все большему снижению эффективности ответов
в пробах по списку А — С. Кроме того, чем больше предоставляется времени на
восстановление ассоциаций А—В, тем выше эффективность в последующих пробах по
списку А — В. Это означает, что прибольших интервалах удержания степень проактивного
торможения будет выше, а ретроактивного-ниже (Underwood, 1948а, Ь).
Веские данные в пользу гипотезы угасания были получены также в экспериментах
с МОП — модифицированным свободным припоминанием (Briggs, 1954) и с ДМСП — "дважды
модифицированным свободным припоминанием" (Barnes а. Underwood, 1959). В экспериментах
того и другого типа была сделана попытка непосредственно выявить распад ассоциаций
А — В во время заучивания списка А — С, т. е. проникнуть в сущность процесса
угасания. В обоих случаях использовался метод с заучиванием списков А — В и
А — С, но инструкции, которые получали испытуемые, были различными. В экспериментах
с МСП испытуемые заучивали сначала список А — В, а затем список А — С, после
чего им предъявляли каждый из А-компонентов и просили давать те ответы, которые
им придут в голову; иными словами, их просили не воспроизводить реакции из определенного
списка, а отвечать то, что раньше вспомнится. Предполагалось, что в первую очередь
будут вспоминаться реакции, наиболее прочно ассоциированные с данными стимулами;
таким образом, процент ответов, относящихся к данному списку, будет служить
мерой прочности ассоциации между стимулами и реакциями в этом списке. Результаты
экспериментов Бриггса, представленные на рис. 9.4, убедительно свидетельствуют
в пользу гипотезы угасания. По мере заучивания списка А — В (или А — С), процент
реакций, содержавшихся в списке А — В (или А — С), увеличивался. В завершающей
пробе, проводившейся после короткого интервала удержания, реакций из списка
С было больше, чем из списка В. Однако при удлинении интервала удержания преимущество
списка С уменьшалось, а при интервалах более 24 ч оно переходило к списку В.
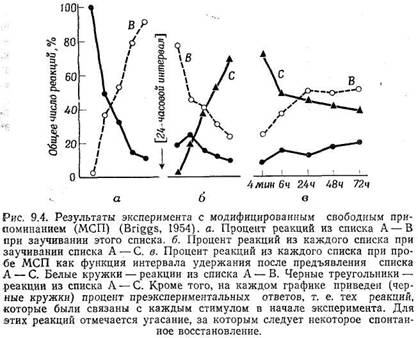
Одна из проблем, возникающих в связи с экспериментами Бриггса, состоит в том,
что хотя они подкрепляют гипотезу распада, в них не показало, что заучивание
списка А — С действительно приводит к распаду В-реакций. Возможно, что В-реакций
все еще сохранялись в памяти, но испытуемый не воспроизводил их просто потому,
что ему раньше приходили в голову С-реакции. Для того чтобы разрешить этот вопрос,
т. е. выяснить, продолжают ли В-реакций сохраняться в памяти, Барнес и Андервуд
(Barnes a. Underwood, 1959) использовали метод ДМСП: испытуемым предъявляли
каждый из стимулов А и просили их постараться вспомнить как В-, так и С-реакции.
Результаты этого эксперимента, представленные на рис. 9.5, позволяют думать,
что реакции действительно угасали. По мере заучивания списка А — C В-реакции
припоминались все реже и реже, несмотря на то что испытуемых просили воспроизводить
их: по-видимому, эти реакции исчезали из памяти.
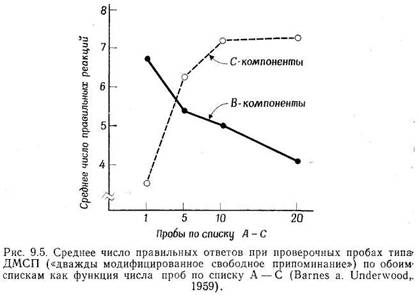
Результаты только что описанных экспериментов как будто бы подтверждают двухфакторную
гипотезу забывания из ДП, однако данные других исследований оказались не столь
убедительными. Рассмотрим два аспекта этой гипотезы, которые не были проверены
экспериментально. Во-первых, эта гипотеза включает предположение, согласно которому
ассоциации А — В угасают потому, что во время заучивания списка А — С реакции
В вызываются из памяти, но не подкрепляются. Это предположение не получило пока
четкого подтверждения. Во-вторых, возникали сомнения относительно спонтанного
восстановления В-реакций во время интервала удержания.
Займемся сначала гипотезой о неподкреплении. Один из ее вариантов мог бы состоять
в том, что если испытуемый во время заучивания списка А — С произносит вслух
ответы В и эти ответы не получают затем подкрепления, то они угасают. Однако
явные (произносимые вслух) ответы из списка А — В во время заучивания списка
А — С относительно редки, поэтому распад ассоциаций не может быть связан только
с этим: мы должны предполагать влияние скрытых, или внутренних, реакций В и
их последующего неподкрепления. Но даже и в этом отношении имеющиеся данные
противоречивы. Вообще следовало бы ожидать, что всякий раз, когда чтолибо вызывает
явные или скрытые вторжения реакций из списка А — В во время заучивания списка
А — С, должно возникать значительное ретроактивное торможение, так как чем больше
будет вторжений, тем сильнее окажется неподкрепление в отношении реакций В,
а тем самым и угасание. Поэтому когда выясняется, что чем больше сходство между
реакциями В и С, тем больше происходит скрытых (если не явных) вторжений из
списка В во время заучивания списка А — С и тем значительнее ретроактивное торможение,
то все это подтверждает нашу гипотезу. По-видимому, сходство способствует вызыванию
В-реакций, что приводит к их еще большему угасанию и более сильному ретроактивному
торможению, создаваемому заучиванием списка А — С (Friedman a. Reynolds, 1957;
Postman a. o., 1965). Возможен, однако, и обратный эффект: если реакции из списка
А — С заучиваются без большого труда, то угасание списка А — В (и ретроактивное
торможение) должно быть незначительным, так как при этом будет меньше возможностей
для вызывания В-ответов во время заучивания списка А — С, а следовательно, и
меньше возможностей для того, чтобы эти ответы не подкреплялись. Эта идея не
получила убедительного экспериментального подтверждения (Postman a. Underwood,
1973), что ослабило гипотезу о неподкреплении.
Та часть гипотезы угасания, которая относится к самопроизвольному восстановлению,
еще меньше подкрепленафактическими данными. Одним из очевидных способов изучения
самопроизвольного восстановления следовало бы считать метод ДМСП. Испытуемым
можно было бы предъявить список А — В, затем список А — С, а по прошествии нескольких
различных интервалов удержания провести контрольноевоспроизведение по методу
ДМСП. Мы могли бы ожидать, что при более длинных интервалах удержания частота
В-реакций будет выше, так как с течением времени ассоциации А — В должны восстанавливаться.
Между тем в экспериментах, проведенных с целью выявить процесс спонтанного восстановления
(Ceraso a. Henderson, 1965; Houston, 1966; Koppenal, 1963), не было обнаружено
никакого улучшения результатов по списку А — В с течением времени. Вероятно,
наиболее удачными (по крайней мере в смысле получения какихто данных в пользу
восстановления) были эксперименты Постмена и его сотрудников (Postman а. о.,
1968, 1969). Эти исследователи наблюдали некоторое восстановление В-реакций
спустя примерно 25 мин, т. е. довольно короткого интервала удержания. Это кажется
особенно странным в сопоставлении с тем фактом, что при 20-минутных интервалах
проактивное торможение (связанное, как полагают, с самопроизвольным восстановлением)
выражено сравнительно слабо (см., например, Underwood, 1949). Согласно рассматриваемой
теории, проактивное торможение (ПТ) обусловлено самопроизвольным восстановлением
В-реакций; как же тогда может возникать сильное ПТ при контрольных воспроизведениях
с интервалами, в течение которых восстановления не происходит, и восстановление
— при коротких интервалах, когда ПТ минимально?
Довольно серьезный удар самому основному предположению двухфакторной гипотезы
— предположению о том, что ассоциации, подавляемые в результате интерференции,
на самом деле угасают, — наносят результаты одного эксперимента, проведенного
Постменом и Старком (Postman а. Stark, 1969). В одном из вариантов этого эксперимента
использовалась проба на узнавание после заучивания списков А — В и А — С: испытуемому
предъявляли набор В-компонентов и просили найти среди них тот, который соответствует
определенному А-компоненту. Испытуемый не должен был припоминать надлежащие
В-компоненты; ему достаточно было узнать их. Результаты оказались совершенно
неожиданными: ретроактивное торможение было незначительным. Создавалось впечатление,
что ответы из списка А — В вовсене подверглись распаду, а были доступны для
проверки методом узнавания. Таким образом, после заучивания списков А — В и
А -С затруднено было воспроизведение В-компонентов, а не связывание их со стимулами
(А). Иными словами, испытуемым было совсем нетрудно вспомнить, что ДАК-7 — это
парная ассоциация из списка А — В; им было трудно припомнить компонент 7 при
предъявлении компонента ДАК.
Мысль о том, что при заучивании парных ассоциаций испытуемый, в частности,
научается воспроизводить компоненты-реакции, сама по себе была не нова. Однако
вытекавшее из эксперимента Постмена и Старка представление о том, что проактивное
и ретроактивное торможение зависит от неспособности вспоминать реакции, а не
от утраты ассоциативных связей, — это нечто относительно новое. Сами компоненты-реакции,
по-видимому, тоже не утрачиваются. Просто в то время, когда происходит припоминание,
они недоступны. Если бы они действительно исчезали из памяти, то вряд
ли пробы на узнавание дали бы такие удивительные результаты.
ИНТЕРФЕРЕНЦИЯ НАБОРОВ РЕАКЦИЙ
Последняя гипотеза,
которую мы здесь рассмотрим, гипотеза об интерференции наборов реакций
(Postman а. о., 1968)-совместима с результатами, полученными Постменом и
Старком. Согласно этой гипотезе, интерференция представляет собой род
конкуренции между реакциями, но не между отдельными реакциями, а между
целыми их группами; например, весь набор В-компонентов списка А—В
конкурирует со всем набором С-компонентов списка А—С.
Предполагается,
что события в экспериментах с А—В и А—С протекают следующим образом. Сначала
заучивание списка А—В активизирует набор В-реакций; при этом включается какой-то селекторный механизм, который обеспечивает их большую
доступность за счет других реакций. Затем, во время заучивания списка А—С,
этот механизм переключается и активизирует С-реакции, одновременно
подавляя В-реакций. Кроме того, селекторный механизм обладает некоторой инерцией, так что переключение с одного набора на другой
занимает некоторое время. Поэтому при проведении контрольных проб по списку
А—В вскоре после заучивания списка А—С наблюдается ретроактивное торможение:
селектор еще продолжает активизировать набор С-реакции.
Сущность гипотезы об интерференции наборов реакций состоит в том, что интерференция
происходит на уровне це-лых систем реакций, а не на уровне отдельных ассоциаций.
Наряду с этим главным утверждением гипотеза содержит также другие предположения.
Во-первых, предполагается, что при надлежащих условиях, например таких, которыепозволяют
"обойти" селекторный механизм, ретроактивного торможения наблюдаться не будет.
Быть может, применение пробы с узнаванием (как в работе Postman a. Stark, 1969)
приводит именно к этому — создает возможность обойти селектор, поскольку реакции
предъявляются во время самой пробы и тем самым доступны непосредственно. Во-вторых,
согласно этой гипотезе, в течение интервала удержания степень ретроактивного
торможения должна снижаться, так как инерция селекторного механизма будет наибольшей
сразу после заучивания списка А—С. Через некоторое время, однако, этому механизму
будет легче вновь переключаться на систему А—В (с этим связано самопроизвольное
восстановление). В-третьих, эта гипотеза позволяет объяснить возрастание ретроактивного
торможения по мере увеличения сходства между наборами реакций (т. е. более сильную
интерференцию при большем сходстве между С-компонентами и В-компонентами). Этот
факт объясняют, постулируя чувствительность селекторного механизма к сходствам
в пределах списка. В частности, предполагается, что механизм, отбирающий реакции,
будет эффективным лишь в том случае, еслиимеется четко обособленный набор реакций,
к которому он может быть приложен, т. е. если имеются четкие критерии для выбора.
Переключение механизма должно направляться какими-то новыми критериями, определяющими
принадлежность реакций к данному набору. Таким образом, если два набора реакций
различаются не очень сильно, селектор может включать в текущий набор как те,
так и другие реакции.
Гипотезу о наборах реакций не следует резко противопоставлять двухфакторной гипотезе, так как обе они содержат ряд общих
идей, как, например, идею о конкуренции реакций (хотя и предполагается, что
эта конкуренция происходит на, разных уровнях). Настало вре.мя задать
вопрос: в какой мере теория интерференции в целом позволяет объяснить забывание из долговременной памяти, если отвлечься от экспериментов со
списками А—В и А—С? Ответ на этот вопрос не слишком обнадеживает, но его в
то же время нельзя считать чересчур обескураживающим.
В некоторых работах, проведенных с целью выяснить этот вопрос, делались попытки
исследовать, как забывается вне лаборатории информация, приобретенная в лаборатории.
Например, испытуемым давали заучивать списки часто встречающихся слов (употребительных
в повседневной жизни) и слов, встречающихся редко (Underwood a. Postman, 1960).
Предполагалось, что
забывание списков обычных слов будет выражено
сильнее, так как вероятность повседневного использования испытуемыми этих
слов больше. Внелабораторные ассоциации, соответствующие привычному
употреблению этих часто встречающихся слов, должны были бы создавать
интерференцию и приводить к забыванию списков, заученных в лаборатории.
Полученные результаты до некоторой степени подтверждали это предположение,
хотя их ни в коей мере нельзя было считать решающими.
В других экспериментах (Slamecka, 1966) была поставлена прямо противоположная
задача — вызвать у испытуемых распад ассоциаций, выработавшихся вне лаборатории.
Сначала у них вызывали реакции на стимулы в пробах на свободные ассоциации (в
этих пробах испытуемому предъявляют какой-нибудь элемент, например КОШКА, и
просят его назвать первое пришедшее в голову слово, например "собака"). Затем
стимулы, использованные для вызывания ассоциаций, были внесены в списки парных
ассоциаций в сочетании с новыми реакциями (например, КОШКА — БУДЬТЕ УВЕРЕНЫ
вместо КОШКА — СОБАКА); при этом интерференции почти не наблюдалось. В контрольных
пробах на свободные ассоциации оказалось, что испытуемые ничего не забыли. Если
они пришли в лабораторию с ассоциацией "кошка — собака", то несколько проб с
ассоциацией "кошка — будьте уверены" не заставят их забыть, что собаки и кошки
связаны друг с другом.
Возможно, что некоторые результаты, получаемые при попытках
заставить испытуемых забыть лабораторный материал, оказавшись в обстановке
реального мира, или наоборот, можно объяснить, обратившись к гипотезе
интерференции наборов реакций. Можно предполагать, что реакции,
характерные для повседневной жизни, могут сохраняться в ином наборе
реакций, нежели лабораторные реакции, и как только испытуемый выходит из
лаборатории, они легко восстанавливаются. Поэтому для того, чтобы получить
какое-то представление о роли интерференции в объяснении явления
забывания в реальной жизни, необходимо имитировать условия реального
мира в лаборатории. Мы должны использовать все возможности,
предоставляемые лабораторией (в чем бы они ни состояли), для того чтобы
управлять производимыми процедурами, но в то же время нам хотелось бы имитировать забывание в том виде, в каком оно происходит вне
рамок
эксперимента. Кроме того, мы не можем расчленить наш эксперимент, проводя
его частично в лабораторной обстановке, а частично вне лаборатории, так
как при этом возникли бы осложнения, обусловленные различающимися
наборами реакций.
ЗАБЫВАНИЕ И ЕСТЕСТВЕННЫЙ ЯЗЫК
В литературе можно найти ряд экспериментальных работ, проливающих
свет на главную интересующую нас проблему: какова природа забывания в
реальном мире? Нередко такие эксперименты выходят за пределы метода парных
ассоциаций: они проводятся на материале естественного языка. Под
естественным языком мы понимаем просто слова, связанные между собой
таким образом, чтобы получился фрагмент естественной речи на языке, родном
для испытуемого. Предполагается, что, используя такого рода материал,
удастся подойти к изучению забывания более естественным путем-создать условия, действительно имитирующие реальность. Рассмотрим
некоторые типичные исследования такого рода.
Знакомясь с этими работами, мы
прежде всего увидим, что забывание английского текста чаще всего изучают в
рамках слегка замаскированного эксперимента типа А—В, А—С, т. е.
применяют метод, близкий к методу заучивания списков. Например, испытуемым
зачитывают ряд последовательных прозаических отрывков, а затем проверяют
запоминание с помощью теста на заучивание общего смысла этих отрывков
(Slamecka, 1960а, Ь); при этом почти никакого забывания обнаружить не
удается. Такой результат очень далек от того, что наблюдается при
заучивании списков А—В, А—С. Однако, используя в качестве стимульного
материала фрагменты английского текста в условиях, более близких к
заучиванию списков А—В, А—С, можно наблюдать явления интерференции.
Например, Краус (Grouse, 1971) давал испытуемым заучить отрывок из биографии
какого-нибудь вымышленного персонажа; этот отрывок содержал такие конкретные данные, как место и время рождения этого персонажа, род
занятий его отца, сведения о смерти родителей и т. п. Затем испытуемым
зачитывали два других отрывка, близких к первому по содержанию. Они также
носили биографический характер — фактически они были изложены примерно теми же словами, что и первые два отрывка, если не считать
некоторых различий в деталях: разные имена и даты рождения, несколько иные
обстоятельства смерти родителей и т. п. Затем проверяли запоминание
первого отрывка, задавая испытуемым вопросы относительно конкретных фактов, которые были изменены в двух последующих текстах по сравнению с
первым. В этих экспериментах испытуемые припоминали гораздо меньше
сведений, чем контрольная группа, которой между предъявлением первого
отрывка и его припоминанием зачитывали два совершенно не сходных с ним
отрывка. Таким образом, в данном случае ретроактивное
торможение возникло в обстановке естественного языка (английской
прозы). По-видимому, такого рода метод можно
считать эффективным, поскольку
отрывок, подлежащий припоминанию, и измененные отрывки излагаются в общем
в одних и тех же словах (подобно А-компонентам в списке А—В) и
различаются только по ряду специфических слов (что очень похоже на переход к
списку А—С). Таким образом, эффекты интерференции выявляются только в
ситуациях, сходных с типичными экспериментами на проактивное и ретроактивное торможение, но не в других условиях.
Какой же можно сделать вывод из
того, что для демонстрации интерференции в экспериментах с подлинным
языковым материалом необходимо использовать этот материал таким же
образом, как и списки А—В и А—С? Может быть, забывание во внелабораторных
условиях не отличается от забывания, наблюдаемого в традиционных
экспериментах с интерференцией? Мы не вправе делать столь определенное
заключение. Вместо этого рассмотрим более подробно, что представляет
собой забывание в реальном мире.
Один из наиболее широко известных экспериментов по забыванию на материале естественного
языка был проведен Бартлетом (Bartlett, 1932). (Сам Бартлет не считал свою работу
специально направленной на изучение забывания, однако это не означает, что мы
не можем рассматривать ее в связи с обсуждаемой здесь темой.) Бартлет просил
испытуемых попытаться воспроизвести рассказ, который они перед этим прочитали.
Это была легенда одного из племен североамериканских индейцев под названием
"Война духов" (эта легенда и пересказ ее одним из испытуемых приведены на рис.
9.6 (курсивом ниже)).
Рис. 9.6. Легенда "Война
духов" и ее пересказ, сделанный испытуемым.
Ниже дается перевод обоих
текстов.
Предъявленный текст
The War of the Ghosts
One night
two young men from Egulac went down to the river to hunt
seals, and while
they were there it became foggy and calm. Then they heard
war-cries, and
they thought: "Maybe this is a war party". They escaped
to the shore, and
hid behind a log. Now canoes came up, and they heard
the noise of paddles,
and saw one canoe coming up to them. There were five
men in the canoe, and
they said:
"What do you think? We wish to take you along. We are going up the
river to make war on the people".
One of the young men said: "I heve no arrows".
"Arrows are in the canoe", they said.
"I will not go along. I maght be killed. My relatives do not know where
I have gone. But you", he
said, turning to the other, " may go with them".
So one of the young
men went, but the other returned home.
And the warriors went on up the river
to a town on the other side of
Kalanna. The people came down to the water,
and they began to fight, and
many were killed. But presently the young man
heard one of the warriors
say: "Quick, let us go home: thet Indeam has been hit." Now he thought:
"Oh,t hey are ghosts ". He did not feel sick, but they
said he had been shot.
So the canoes went back to Egulac, and the young man
went ashore
to his house, and made a fire. And he told everybody and said:
" Behold I accompanied the ghosts, and we went to fight. Many of our
fellows were killed, and many of those who attacked us were killed. They
said I was hit,
and I did not feel sick".
He told it all, and then he
became quiet. When the sun rose he fell
down. Something black came out of
his mouth. His fase became contorted.
The people jumped up and cried.
He
was dead.
Пересказ испытуемого
Two youths were standing by a
river about to start seal-catching, when
a boat appeared with five men in
it. They were all armed for war.
The youths were at first frightened, but
they were asked by the men
to come and help them fight some enemies on the
other bank. One youth
said he could not come as his relations would be
anxious about him; the
other said he would go, and entered the boat.
In
the evening he returned to his hut, and told his friends that he had
been in
a battle. A great many had been slain, and he had been wounded
by an arrow;
he had not felt any pain, he said. They told him that he must
have been
fighting in a battle of ghosts. Then he remembered that it had
been queer
and he besame very excited.
In the morning, however, he became ill, and his
friends gathered round;
he fell down and his face became very pale. Then he
writhed and shrieked
and his friends were filled with terror. At last he
became calm. Something
hard and black came out of his mouth, and he lay
contorted and dead.
Война духов
Однажды ночью двое молодых мужчин из
Эгулака отправились к реке,
чтобы поохотиться на тюленей; пока они были на
реке, опустился туман
и стало очень тихо. Вдруг они услышали боевые кличи и
подумали:
"Должно быть, это отряд воинов". Они взбежали на берег и
спрятались
за каким-то бревном. На воде появилось несколько каноэ; охотники
услышали шум весел и увидели, что одно каноэ приближается к ним. В этом
каноэ было пять мужчин, которые обратились к ним со словами:
- Не
поедете ли вы с нами? Мы хотели бы взять вас с собой. Мы
идем вверх по реке
воевать с тамошним народом.
Один из молодых охотников сказал:
- У меня
нет стрел.
- Стрелы есть в каноэ, — отвечали прибывшие.
- Я не поеду с
вами. Меня могут убить. Мои домашние не знают,
куда я пошел. Но ты, — он
повернулся к своему спутнику, — ты можешь
отправиться с ними.
И один из
молодых людей уплыл с воинами, а другой вернулся домой.
Воины поплыли вверх
по реке к селению, находившемуся по другую
сторону Каламы. К воде спустились
люди, и началось сражение; было
много убитых. Вдруг молодой охотник услышал,
как один из воинов сказал: "Скорее домой, этого индейца ранили". И
тут он подумал: да ведь
это духи. Он не чувствовал боли, но они сказали,
что в него попала стрела.
Каноэ приплыли назад в Эгулак, и молодой индеец,
сойдя на берег,
направился домой и развел огонь. И он рассказывал всем;
- Вот как было дело. Я справился с духами, и мы вступили в битву.
Многие
из наших были убиты, и многие из тех, кто нападал на нас, были
убиты. Духи
сказали, что меня ранило, но я не почувствовал боли.
Он рассказал все это и
замолк. Когда взошло солнце, он упал на землю. Что-то черное вышло у него
изо рта. Его лицо исказилось. Люди
вскочили и стали кричать.
Он был
мертв.
Пересказ испытуемого
Двое юношей стояли у реки, собираясь
поохотиться на тюленей, как
вдруг появилась лодка, в которой сидело пятеро.
Все они были вооружены.
Юноши сначала испугались, но вновь прибывшие
попросили их отправиться с ними и помочь им сражаться с какими-то врагами
на другом
берегу. Один из юношей сказал, что он не может ехать, так как его
родные
будут беспокоиться; другой сказал, что поедет, и вошел в лодку.
Вечером он вернулся в свою хижину и рассказал друзьям, что участвовал
в сражении. Было очень много убитых, а он был ранен стрелой; он
сказал, что
не почувствовал никакой боли. Друзья сказали ему, что он,
по-видимому,
участвовал в битве духов. Тут он вспомнил, что все было
как-то странно, и
пришел в сильное возбуждение.
Наутро он почувствовал себя плохо, и вокруг
него собрались друзья;
он упал, и лицо его сильно побледнело. Затем он стал
корчиться и вопить,
а его друзей охватил ужас. Наконец он затих. Изо рта у него вышло что-то твердое
и черное, и он лежал, скрючившись, мертвый.
Как видно из приведенных текстов, когда испытуемые Бартлета, которые не были
индейцами, пытались пересказать легенду, они допускали довольно характерные
ошибки. Поскольку исходное повествование не соответствовало привычным для них
представлениям о возможных событиях и об их логическом развитии, ошибки, допускаемые
ими при пересказе и искажавшие легенду, порождались их стремлением переделать
ее и привести в "нормальный", с их точки зрения, вид. По мнению Бартлета, такого
рода ошибки испытуемых были связаны с тем, что при первом прочтении легенды
они создавали себе некую мысленную схему или абстрактное представление относительно
общей темы легенды. Такая схема неизбежно должна была "вписаться" в индивидуальную
систему убеждений, эмоций и т. п. данного испытуемого, а это в свою очередь
приводило к характерным изменениям, которые наблюдались в его пересказе. Короче
говоря, можно сделать вывод, что испытуемые пытались подогнать легенду к имеющейся
у них структуре ДП. Они "забывали" некоторые аспекты легенды, которые не соответствовали
этой структуре, не были с ней совместимы или даже создавали интерференцию.
Продемонстрированное Бартлетом искажение заучиваемого материала в
соответствии с реальным багажом знаний не единственный пример такого рода.
Результаты проведенных за последнее время исследований говорят в пользу
того, что при запоминании текстового материала испытуемые создают себе
мысленное представление об общей "теме", а затем используют это
представление, когда их просят припомнить какие-либо слова, ответить на
вопросы, восстановить в памяти факты и т. п.
Классический пример этого эффекта запоминания общей темы описала Сакс (Sachs,
1967). Она давала испытуемым прослушать записанные на магнитную ленту отрывки.
В какой-то момент после того, как испытуемые выслушивали одно из предложений,
содержащихся в таком отрывке, им предъявляли сходное с ним предложение. Это
новое предложение могло быть идентично тому, которое было в отрывке, или же
слегка изменено. Изменения были либо синтаксическими, не затрагивавшими смысла,
либо семантическими, т. е. смысловыми. Если, например, исходным предложением
было: "Мальчик побил девочку", то после синтаксического изменения оно могло
принять вид "Девочка была побита мальчиком", а семантическое изменение привело
бы к предложению "Девочка побила мальчика". Сакс установила, что если измененное
предложение предъявляли сразу же после исходного, то испытуемые легко обнаруживали
почти любое изменение (по-видимому, это происходило потому, что в этом случае
использовалась информация, находившаяся в КП, где должно было целиком содержаться
исходное предложение). Однако если между предъявлеииями данного предложения
в его исходном и измененном виде испытуемый прослушивал, другой словесный материал,
то смысловые изменения он замечал гораздо легче, чем чисто синтаксические; можно
было исказить предложение по форме, и испытуемый не замечал этого, хотя он сразу
обращал внимание на изменения смысла.
Эксперименты Сакс дают нам еще одну иллюстрацию забывания "естественного" речевого
материала. В данном случае (в отличие от эксперимента Бартлета) забывается не
смысл, а те точные слова, которыми он выражен. Тем не менее забывание у испытуемых
Сакс сходно с наблюдавшимся в экспериментах Бартлета, поскольку и здесь происходит
некоторое искажение первоначального входного сообщения. Создается впечатление,
что у Сакс испытуемые закладывали в ДП какое-то представление о смысле прослушанного
отрывка и забывали о том, в каких словах он был выражен. Этот факт запоминания
смысла, а не точной формы выявлялся, .когда наступало время вспомнить точные
слова. Однако в данном случае не было нужды искажать смысл (как это делали испытуемые
Бартлета), потому что он не противоречил структуре ДП. Можно ли считать это
интерференцией в принятом смысле? Едва ли. Мы могли бы, пожалуй, рассматривать
такого рода забывание как интерференцию, но лишь в той мере, в какой лингвистические
познания испытуемого могут "мешать" (to with) сохранению в его памяти
точных формулировок. Иными словами, испытуемые могли бы знать, что в общем формулировка
того или иного предложения не столь существенна, пока сохраняется смысл. Знание
этого обстоятельства побуждает их сохранять в памяти смысл, а не точные формулировки.
Есть некоторые дан:ные в пользу этой идеи, так как нетрудно показать, что ис.пытуемые
способны хранить в памяти точную формулировку какого-либо предложения, если
им это нужно (Anderson а. Bower, 1973; Wanner, 1968).
Как показывают рассмотренные нами до сих пор результаты, забывание "естественного"
текста, по-видимому, очень мало связано с забыванием, вызванным интерференцией,
которое наблюдается в экспериментах с проактивным и ретроактивным торможением.
Описанное здесь забывание предложений и отрывков можно отнести на счет каких-то
явлений, близких к интерференции, но лишь в том случае, если существенно расширить
это понятие. То, к чему мы при этом приходим, имеет мало общего с гипотезами
угасания, конкуренции реакций и конкуренции наборов реакций. Против интерференционной
теории забывания говорит и то, что в некоторых случаях "забывающие" что-то испытуемые
на самом деле помнят, по-видимому, больше, а не меньше по сравнению с первоначально
предъявленным материалом. Такого рода "забывание" дает основу для конструктивного
подхода к изучению памяти па естественный речевой материал — подхода, который
был предпринят Брэнсфордом, Барклеем, Фрэнксом и их сотрудниками.
Как уже говорилось (гл. 4), Фрэнке и Брэнсфорд (Franks .a. Bransford, 1971)
показали, что при зрительном предъявлении испытуемым ряда сложных фигур они,
по-видимому, мысленно сводили эти фигуры к какому-то абстрактному прототипу,
который и использовали затем для распознавания. Таким образом, они распознавали
контрольные фигуры по их близости к прототипу независимо от того, предъявлялись
ли раньше именно эти фигуры. Аналогичный эффект был обнаружен и в отношении
памяти на предложения (Bransford a. Franks, 1971). Исходным материалом в этих
экспериментах служила группа из четырех простых предложений, например: 1) "На
кухне были муравьи"; 2) "На столе стояло желе"; 3) "Желе было сладкое"; 4) "Муравьи
съели желе". Комбинируя их по два, по три или все четыре вместе, можно получать
новые предложения. Например, сочетание 1-го и 4-го дает: "Муравьи на кухне съели
желе". Сочетание 3-го и 4-го — "Муравьи съели сладкое желе". Из 2-го, 3-го и
4-го можно получить: "Муравьи съели сладкое желе, которое стояло на столе".
А все четыре дадут: "Муравьи на кухне съели сладкое желе, которое стояло на
столе". Последнее предложение соответствует фигурам-прототипам в экспериментах
Фрэнкса и Брэнсфорда со зрительной памятью, так как оно содержит всю информацию,
которая заключалась в четырех исходных предложениях.
Затем Брэнсфорд и Фрэнке предъявляли испытуемым некоторую часть того множества
предложений, которое можно было создать из четырех простых исходных предложений.
В эту часть входили: два предложения из четырех исходных; два предложения, каждое
из которых было составлено из каких-то двух исходных; два, составленные из трех
исходных. Эти предложения подбирались таким образом, чтобы здесь в той или иной
комбинации были представлены все четыре исходных простых предложения, а предъявляли
их вперемежку с предложениями из других множеств, которые не имели отношения
к муравьям, кухням и желе, но были созданы таким же способом. Затем проводили
пробу на распознавание и просили испытуемых указать, в какой мере они были уверены
в правильности высказанных ими суждений. Полученные результаты были аналогичны
результатам эксперимента со зрительным предъявлением фигур: испытуемые с наибольшей
уверенностью "узнавали" как якобы виденное раньше прототипическое предложение-то,
в котором сочетались все четыре простых предложения. Между тем его никогда им
не предъявляли! Кроме того, испытуемые, по собственным оценкам, более уверенно
узнавали предложения, в которых сочетались по три основные формы, чем сочетания
по две, а сочетания по два — более уверенно, чем каждое из исходных предложений
в отдельности. Короче говоря, для "распознавания" предложения было несущественно,
видели его испытуемые на самом деле или нет. Важно было число исходных предложений,
входивших в состав предъявляемого предложения: чем больше было это число, тем
выше была вероятность "узнавания".
По мнению Брэнсфорда и Фрэнкса, эти
результаты были обусловлены тем, что испытуемые абстрагировали и хранили
в памяти комбинированное содержание предъявлявшихся им предложений. Они
"создавали" себе мысленное представление из предъявленного им сырья,
и это представление строилось на первоначально предъявленной информации,
но не ограничивалось ею. Здесь мы опять встречаемся с неспособностью
запомнить специфические особенности предъявленной информации. И снова
можно видеть искажение этой информации; в данном случае оно ведет к
созданию "прототипического" семантического представления из более
изолированных фактов.
В других сходных экспериментах (Barclay, 1973; Bransford а. о., 1972) были
получены данные, указывающие на то, что испытуемые могут выходить за пределы
информации, сообщенной им в предложении, и сохранять информацию не только о
самом этом предложении, но и о вытекающих из него следствиях. Например, Брэнсфорд
и его сотрудники предъявили испытуемому предложение "На плавучем бревне отдыхали
три черепахи, а под ними проплыла рыба", а он распознал его как "На плавучем
бревне отдыхали три черепахи, а под ним проплыла рыба", 3амена "под ними" на
"под ним" представляет собой вывод, следующий из исходного предложения: мы знаем,
что если черепахи сидят на бревне, то проплывающая под черепахами (ними) рыба
проплывает под бревном (ним). Если же в исходном предложении дать "Три черепахи
отдыхали возле плавучего бревна, а под ними проплыла рыба", а в контрольном
заменить "ними" на "ним", то аналогичной ошибки узнавания не наблюдается: слово
"возле" не допускает такой интерпретации. Если рыба проплыла под черепахами,
находившимися возле бревна, тонет гарантии, что рыба при этом проплыла и под
бревном. Эти результаты снова показывают, что испытуемые, прослушивая то или
иное предложение, закладывают в память нечто большее, чем просто слова, из которых
оно состоит. В их памяти, по-видимому, сохраняется содержание (но не точная
формулировка) предложения и даже следствия, которые можно вывести из этого содержания.
Воспользовавшись терминологией Бартлета, можно сказать, что они хранят в памяти
"схему" предложения. Поэтому забывание, когда речь идет о предложении, мало
похоже на ПТ и РТ. "Забывание" не выражается здесь просто в утрате части информации;
напротив, предложение хранится в памяти с каким-то добавлением.
ИНТЕРФЕРЕНЦИЯ: НЕКОТОРЫЕ ИТОГИ
Теперь настало время еще раз обозреть все, что нам известно об интерференционной
теории забывания. Прежде всего мы знаем, что эта теория в той или иной ее форме
в состоянии объяснить большую часть типичных явлений, наблюдаемых в экспериментах
со списками А—В и А—С. Нам известно также, что если несколько расширить эту
теорию, используя термин "интерференция" в весьма общем смысле, то она позволит
в какой-то мере понять забывание связного вербального материала, хотя она лучше
всего подходит в тех случаях, когда в экспериментах с таким материалом используется
в слегка замаскированном виде метод А—В, А—С. Наконец, нам известно, что некоторые
явления, связанные с запоминанием и воспроизведением такого материала, создают
затруднение для интерференционной теории. Так. например, интерференция не позволяет
объяснить, почему испытуемые, прослушивая предложения, запоминают вытекающие
из этих предложений следствия, а не те слова, в которых они были сформулированы.
Короче говоря, можно сказать, что хотя и было показано, что интерференционная
теория объясняет ряд специфических форм забывания, она не в состоянии справиться
со многими результатами, полученными в экспериментах с естественным речевым
материалом.
Можно, пожалуй, сказать,
что интерференционная теория забывания в своих обычных формах больше всего
пригодна для объяснения тех данных, которые укладываются в рамки теории
"стимул — реакция". Например, парные ассоциации первоначально должны
были использоваться как средство прямого изучения связей между стимулом и
реакцией. Не удивительно поэтому, что исследования с применением парных ассоциаций
составляют большую часть основы интерференционных
теорий, порожденных традиционными представлениями о таких связях. Однако
эти теории гораздо менее пригодны для объяснения памяти на предложения и
отрывки текста. Такого рода память лучше поддается объяснению при
помощи теорий, имеющих лингвистическую основу, как, например,
рассмотренные нами теории семантической памяти.
В частности, такая модель, как АПЧ с ее ассоциативносетевой структурой, может
послужить основой для одного из видов интерференционной теории (Anderson a.
Bower, 1973). В модели АПЧ ретроактивное торможение проистекает из природы процесса
сопоставления (рассмотренного в гл. 8). С помощью этого процесса осуществляется
поиск в ДП структуры высказывания, соответствующей некоторой входной информации,
— это главный компонент процесса извлечения информации из ДП. Сканирование ДП
начинается с ячеек, соответствующих терминальным узлам входного дерева; пути,
отходящие от этих ячеек, различаются по очередности обследования (приоритету).
Процесс поиска от каждой ячейки начинается по тем путям, которым предоставлен
высший приоритет, и продолжается в соответствии с порядком очередности либо
до тех пор, пока не будет найдено соответствующее предложение в ДП, либо пока
не пройдет определенное время, после чего поиск прекращается. Произвести поиск
по всем путям невозможно, так как это заняло бы слишком много времени. Если
мы предположим, что очередность зависит от относительной давности использования
тех или иных путей, то тем самым мы получим механизм ретроактивного торможения.
Пути, соответствующие недавно полученной информации, будут иметь высший приоритет,
и поиски таких путей будут приводить к нахождению более удачных соответствий,
чем поиски путей, которые использовались в более давние сроки (эти пути "погребены"
под более свежими путями). Это означает, что приобретение новой информации ухудшает
память на информацию, приобретеннуюранее, и создает таким образом ретроактивное
торможение. С добавлением этого и сходных механизмов интерференции модель АПЧ
становится совместимой с результатами традиционных экспериментов, касающихся
интерференции. Кроме того, эта модель может лучше объяснить кодирование и удержание
в памяти естественного речевого материала, так как главную роль в ней играют
формы, сходные с предложениями.
Итак, параллельно с изменениями в характере проводимых экспериментов (от заучивания
парных ассоциаций до исследования памяти на наборы предложений) происходили:
изменения и в теориях забывания. Многие из этих изменений приводят к тому, что
теории приобретают более "когнитивный" характер, и если оценивать с тех позиций,
с которых написана данная книга, то можно сказать, что эти теории становятся
более пригодными для объяснения многих сторон познавательных процессов.
Глава 10
Запоминание. Процессы кодирования
В
предшествующих главах, посвященных долговременной памяти, мы рассматривали
модели ее структуры и процессов, происходящих в рамках этой структуры, как
ту основу, на фоне которой производится проверка истинности утверждений и происходит забывание информации, приобретенной ранее. В этой и
последующих главах мы обсудим ряд других процессов, связанных с ДП.
Как уже говорилось в гл. 1, для того чтобы память могла выполнять свою роль,
необходимы три процесса: кодирование. хранение и извлечение. Прежде всего информация
должна быть закодирована. Вообще закодировать" означает привести в форму, подходящую
для внутреннего хранения. Например, буквы кодируются в иконические образы в
результате процессов, которые изолируют зрительно воспринимаемые признаки и
отделяют фигуры от фона. Кодирование вербальной информации при внесении ее в
КП может состоять в присвоении "метки" (например, когда буква Я превращается
в звук "йа"); при этом может также использоваться процесс структурирования.
Таким образом, кодирование иногда представляет собой весьма сложную операцию.
После кодирования материал поступает в память, где он хранится Пока материал
находится на хранении, с ним могут происходить разные вещи, в результате чего
его впоследствии иногда не удается припомнить. Нередко слово "хранение" употребляют
в более широком смысле, включающем и процесс закладки на хранение, т. е. понимая
под ним не только само хранение, но и кодирование. Поскольку само по себе хранение
можно рассматривать как довольно пассивное явление — подобно хранению зимних
вещей в стенном шкафу в летнее время, — представляется разумным включать е этот
термин также и кодирование; если он используется здесь иногда в этом смысле,
то из контекста ясно, что имеется виду.
Наконец, существует и третий аспект функции памяти — извлечение информации.
Нередко случается, что хотя человек закодировал какую-то информацию и "положил
ее на хранение", он позже будет не в состоянии ее припомнить. Информация может
все еще находиться в памяти, по до нее не удается добраться. В этом случае просто
не срабатывает процесс извлечения информации. Извлечение означает получение
доступа к информации, хранящейся в памяти.
"Кодированием" часто называют процессы, происходящиев сенсорных регистрах
или в кратковременной памяти, а о "хранении" и "извлечении" чаще всего говорят,
имея в виду долговременную память. Вероятно, это обусловлено тем, чтони в сенсорных
регистрах, ни в КП информация долго не хранится, а поэтому извлечь ее из этих
хранилищ либо очень легко, либо невозможно: материал или находится в них, и
тогда добраться до него не составляет труда, или он уже утрачен. Применительно
же к ДП и "кодирование", и "хранение", и "извлечение" — вполне осмысленные термины.
В настоящей главе в центре внимания будут находиться процессы кодирования —
операции, сопровождающие хранение информации в ДП. Мы займемся здесь процессами
опосредования и организации с помощью естественного языка, а в гл. 11 рассмотрим
теории процесса извлечения информации.
ОПОСРЕДОВАНИЕ С ПОМОЩЬЮ ЕСТЕСТВЕННОГО ЯЗЫКА
Одно из явлений, в котором кодирование играет важную роль, — это процесс опосредования
с помощью естественного языка. Вообще опосредованием называют определенные процессы,
играющие роль промежуточных звеньев между предъявлением стимула и внешней реакций
на него; эти процессы нельзя предсказать исходя из самого стимула (Hebb, 1958).
В теории "стимул —
реакция" понятие опосредования имеет существенное значение, когда надо
объяснить, почему данный стимул может вызывать реакции, к которым он не имел
прямого отношения в прошлом. Например, в задаче на свободные
ассоциации компонент-стимул СЕМЬ может вызвать у испытуемого реакцию
"поле". Такая реакция станет понятной, если мы выясним, что между
стимулом и реакцией есть ещеопосрдующее звено. Слово "семь" вызвало
внутреннюю реакцию "семя", которая в свою очередь привела к слову
"поле", ставшему явной реакцией. Короче говоря, внутренняя реакция
была опосредующей: она позволила трансформировать
стимул таким образом, что последний приобрел способность вызывать побочные
ассоциации.
Рассмотрим другой пример опосредующего процесса. Представьте себе, что вы придерживаетесь
теории "стимул реакция" и пытаетесь выяснить, каким образом у испытуемых формируются
ассоциации при запоминании тех или иных элементов. Следуя по стопам Эббингауза,
вы могли бы подобрать элементы, которых испытуемый никогда раньше не видел,
— бессмысленные слоги (типа согласная-гласнаясогласная, или С-Г-С), — чтобы
исключить возможность того, что испытуемый будет использовать прежние ассоциации,
а не те, которые он должен сформировать заново. При этом в качестве С-Г-С испытуемому
можно было бы предъявить, наряду с другими, слог КОШ. Вы просите испытуемого
повторять про себя предъявленные ему слоги и попытаться запомнить их. При проверке
выясняется, что он запомнил слог КОШ лучше, чем остальные С-Г-С. Откуда бы вам
знать, что испытуемый при предъявлении ему слога КОШ подумал о "кошке" и таким
образом видоизменил предъявленный ему описок?
В этом примере испытуемый прибегнул к опосредованию, чтобы заучить С-Г-С. Это
означает, что в процессе кодирования предъявленной информации он использовал
информацию, хранящуюся в ДП (а именно — сведения о том, что слог КОШ совпадает
с тремя первыми буквами в слове "кошка") , для того чтобы модифицировать предъявленный
ему стимул. Такого рода опосредование производится очень часто. Например, когда
испытуемых просят заучивать списки элементов чисто механически, путем простого
повторения, они вместо этого нередко прибегают к опосредованию. Позже они воспроизводят
стимул в опосредованной форме и способ, который они использовали для его модификации,
после чего декодируют эту опосредованную форму, переводя ее в исходную. Это
по существу тот же процесс, который мы рассматривали при обсуждении структурирования
в КП. В частности, только что приведенный пример иллюстрирует использование
вербальных посредников, заимствованных из естественного языка (ПЕЯ). Название
ПЕЯ отражает тот факт, что полученная из ДП информация касалась естественного
языка — особенностей правописания, значений слов и т. п. (в отличие, например,
от перекодирования чисел, о котором говорилось в гл. 5 и которое не связано
с естественным языком).
Хотя использование вербальных посредников может создать затруднение для экспериментатора,
который хочет, чтобы его испытуемые заучивали материал путем механического повторения,
такие посредники интересны сами по себе. Как происходит опосредование? Помогает
ли оно памяти? В каких случаях оно наиболее эффективно? В чем состоят обычные
механизмы опосредования? Эти и некоторые другиевопросы будут рассмотрены ниже.
Следует начать с того, что вербальные посредники иногда действительно помогают
памяти. Испытуемый, использовавший "кошку" для того, чтобы запомнить слог КОШ,
поступил правильно, так как слово "кошка" он помнил лучше, чем мог бы запомнить
простой слог КОШ. Нужно, однако, сделать оговорку: использование посредников
в процессе кодирования мало что даст вам, если вы забудете, что применили этот
прием. Опосредованные элементы удастся безошибочно воспроизвести лишь в том
случае, если в памяти сохранится а их видоизмененная форма, и использованный
способ видоизменения. Какая будет польза от того, что мы запомним "кошку" и
воспроизведем наш слог как КОТ? Этому вопросу был посвящен ряд экспериментов.
ИСПОЛЬЗОВАНИЕ ВЕРБАЛЬНЫХ ПОСРЕДНИКОВ
ПРИ ЗАУЧИВАНИИ ПАРНЫХ
АССОЦИАЦИЙ
Монтегю, Адаме и Кисе (Montague, Adams a. Kiess, 1966) изучали использование
ПЕЯ в заданиях с парными ассоциациями. Заучивая список парных элементов, испытуемые
должны были записывать все такого рода элементы-посредники, которые у них возникали,
хотя их не обязывали создавать такие элементы. Например, при виде пары РАВ —
LOM испытуемый мог написать . Во время проверки, когда испытуемому
предъявляли компоненты-стимулы, он должен был вспомнить для каждого стимула
не только реакцию, но и элемент-посредник, который у него возник в связи с этим
стимулом (если он вообще возник). Затем авторы определили частоту верного воспроизведения,
разделив парные ассоциации на группы в соответствии с тем, создавался ли для
данной пары посредник и помнил ли его испытуемый. Оказалось, что в тех случаях,
когда посредники не возникали, испытуемые правильно воспроизводили в среднем
только" 6% компонентов-реакций. Когда сообщалось о формировании посредников,
частота верного воспроизведения заметно" возрастала (в среднем до 73%), но только
в тех случаях, когда испытуемый мог вспомнить, какие это были посредники; если
же он этого не помнил, правильные ответы составляли вего лишь 2%.
Помимо различий в воспроизведении Монтегю и его сотрудники обнаружили, что
в одних случаях использовалось больше вербальных посредников, чем в других.
Во-первых, посредники возникали чаще, если парные ассоциации предъявлялись для
заучивания медленно (30 с на каждую пару), а не быстро (15 с на пару). Во-вторых,
они формировались чаще, когда слоги (С-Г-С) были относительно более "осмысленными".
Осмысленность слогов (Noble, 1961) означает число ассоциаций, которые в среднем
возникают для данного слога в течение ограниченного времени у определенной группы
испытуемых. Высокие значения СО (степени осмысленности) соответствуют большому
числу ассоциаций. Такой слог, как WIS, например, может ассоциироваться со словами
whiskey, Wisconsin, whisper, whistle и т. п. он обладает высокой осмысленностью.
Примером слога с низким значением СО может быть что-нибудь вроде GOQ. Таким
образом, создается впечатление, что чем легче данный слог ассоциируется с какими-нибудь
словами, тем больше для него вероятность формирования вербальных посредников
в задачах на парные ассоциации. И чем больше предоставляется времени на опосредование,
тем вероятнее использование посредников. Эти результаты по существу означают,
что образование посредников требует известного времени и определенной "работы";
оно не может происходить автоматически и без затраты усилий. Испытуемый должен
придумать какое-нибудь опосредование для данного слога, и хотя сделать это легче,
если слог вызывает много ассоциаций (так что есть много кандидатов на роль посредника),
на все это требуется время.
"Т-СТЭКОВАЯ" МОДЕЛЬ ИСПОЛЬЗОВАНИЯ
ВЕРБАЛЬНЫХ ПОСРЕДНИКОВ, СОЗДАННАЯ ПРИТУЛАКОМ
Только что описанный эксперимент обладает одним недостатком: он не
позволяет выяснить, как формируется посредник. Мы знаем, что посредники
повышают частоту верного воспроизведения .и .что их создание требует
известных усилий, Однако нам совершенно ничего не известно о механизме
их образования. Притулак (Prytulak, 1971) попытался выяснить эти
вопросы, предприняв с этой целью обширные исследования. Он решил
расчленить процесс создания вербальных посредников-разделить его на этап
кодирования (первичное образование и приложение посредника) и этап
декодирования (преобразование посредника в первоначально предъявленный стимул при воспроизведении последнего). Для этого он разработал
весьма детальную систему классификации различных типов посредников,
которые испытуемые создавали из слогов типа С-Г-С.
Притулак начинал с того, что показывал испытуемым несколько таких слогов и
просил их написать для каждого "любые имеющие смысл вещи, какие придут в голову",
будь то слово, фраза, акроним или же сам слог, если он имел какой-либо смысл.
Затем Притулак классифицировал различные элементы-посредники, созданные испытуемыми,
в соответствии с типом "операций", которые следовало произвести над слогом,
чтобы получился посредник. Одна из таких операций-замещение: например, слог
FET можно превратить в "pet", заменив "f" на "р". Другая операция — внутренняя
вставка, добавление буквы в середину слога. Например, вставив "u" в FEL, можно
получить "fuel". Возможно и удаление одной буквы из слога; при этом GОН, например,
превращается в "go". Притулак установил, что образование посредников его испытуемыми
можно было свести к семи различным операциям. Эти семь операций могли использоваться
либо поодиночке, либо в сочетании друг с другом. Например, комбинация замещения
с приставкой (добавлением буквы к концу слова) может превратить слог HOZ в "hose".
Последовательность операций,
используемых для превращения какого-либо слога в посредника, Притулак
назвал "трансформацией". Трансформация может состоять из одной или
нескольких операций; Притулак обнаружил 272 различные трансформации (272
сочетания операций), применявшиеся его испытуемыми.
После формирования
посредников каждому из испытуемых Притулака снова предъявляли их и просили
декодировать, т. е. восстановит те слоги (С-Г-С), из которых он их
создал. Притулак использовал эти восстановленные испытуемыми слоги,
чтобы расположить трансформации в определенном порядке в зависимости от
того, в каком проценте случаев созданные с их помощью слова-посредники
удается декодировать. Например, добавление окончания заняло бы более
высокое положение по сравнению с удалением буквы, если бы оказалось, что
посредники, получившиеся при добавлении, легче декодируются в исходные
слоги, чем полученные в результате выпадения буквы. Таким образом, все
трансформации были расположены в порядке своей, так сказать,
"полезности". Притулак назвал составленный список Т-стэком (Т —
от слова "трансформация").
Наконец, Притулак использовал концепцию Т-стэка для создания модели опосредования
при помощи естественного языка. Согласно этой модели, испытуемый, заучивающий
слог, кодирует его, проходя по Т-стэку сверху, от самой полезной трансформации,
и продолжая перебор до тех пор, пока он не найдет трансформации подходящего
типа -такой, с помощью которой из данного слога можно образовать какое-либо
значащее слово. Чем дальше в списке стоит найденная трансформация, тем менее
удачным будет образованный в результате посредник, так как в конце списка стоят
наименее полезные трансформации. Когда придет время воспроизвести исходный слог,
испытуемый декодирует слово-посредник. Для того чтобы сделать это, он должен
помнить как это слово, так и ту трансформацию, в результате которой оно было
получено. Какой-либо один из этих элементов или оба могут быть забыты, и можно
предполагать, что чем дальше испытуемому приходится проходить по стэку в поисках
подходящей трансформации, тем больше будет неудач при воспроизведении исходного
слога.
Притулак высказал предположение, что запоминание выбранной трансформации должно
зависеть от ее сложности, которая измеряется числом составляющих ее операций.
Трансформацию, требующую лишь одной операции, вероятно, легче запомнить, чем
трансформации, состоящие из нескольких операций. Кроме того, некоторые операции,
по-видимому, забываются легче, чем другие. В частности, ту или иную операцию
скорее можно запомнить, если в полученном посреднике содержится какой-то намек
на то, как он был получен. Так, например, если испытуемый вспомнил слово-посредник
"locomotion", это большая длина этого слова и тот факт, что его начальный слог
представляет собой С-Г-С, могут указывать на то, что оно было получено в результате
добавления к С-Г-С окончания, и тогда испытуемый может догадаться, что исходный
слог был "lос", и сообщить об этом.
Притулак испытывал модель Т-стэка и разными другими способами. Он охарактеризовал
большое число слогов типа С-Г-С по тому расстоянию, которое нужно пройти по
Т-стэку, чтобы создать для них посредника (их "стэковую глубину"). Он находил
слоги, лежащие на верхних уровнях стэка, т. е. такие, из которых очень легко
получить посредника, а также слоги, которые лежали на более глубоких уровнях.
Он установил, что концепции Т-стэка и глубины стэка позволяли хорошо предсказывать
такие разнообразные данные, как скорость заучивания парных ассоциаций, удержание
их вкратковременной памяти и время, необходимое для получения посредников из
С-Г-С.
ПРЕДЛОЖЕНИЯ И ОБРАЗЫ КАК ПОСРЕДНИКИ
Мы обсуждали здесь опосредовапие применительно к слогам типа С-Г-С; однако
образование слов из бессмысленных слогов-отнюдь не единственная форма опосредования
пример, на заучивание парных ассоциаций может заметно повлиять использование
опосредующих предложений (Bobrow a. Bower, 1969; Rohwer, 1966). Опосредующее
предложение превращает парные ассоциации в предложения. Например, слова МАЛЬЧИК-ДВЕРЬ
можно связать с помощью -фразы "мальчик закрывает дверь". Если сделать это,
то позже, когда будет предъявлено слово МАЛЬЧИК, вспомнить "дверь" окажется
гораздо легче, чем без опосредующего предположения. Другой пример опосредования
можно найти в эксперименте, который провела Шварц (Schwartz, 1969). Она давала
испытуемым заучивать списки типа К-СОБАКА, С — КРАН и т. п. После того как испытуемым
объясняли, что эти пары могут быть опосредованы при помощи привычных ассоциаций
для компонентов-реакций, они стали заучивать списки быстрее, чем раньше. При
этом К-СОБАКА можно было превратить в "кошка — собака", С — КРАН в "стоп-кран"
и так далее. Позднее, при предъявлении К-? испытуемый вспоминал: "К-кошка",
"кошка-собака" и отвечал: "собака".
Мы упомянем здесь еще об одной форме опосредования, несколько иного типа. Все
рассмотренные нами факторы опосредования были вербальными-это были слова, предложения
или фразы. Однако посредниками могут служить также мысленные картины или образы.
В гл 12 роль мысленных образов в ДП рассматривается гораздо более подробно,
поэтому здесь мы ограничимся кратким описанием одного экспериментального метода,
1В котором используется такого рода опосредование. Боуэр (Bower, 1972b) просил
испытуемых, запоминавших пары существительных, создавать мысленные картины,
в которых объекты, образующие каждую пару, взаимодействовали бы друг с другом.
Например, при предъявлении пары СОБАКА—ВЕЛОСИПЕД испытуемые могли представить
себе собаку, которая едет на велосипеде. Контрольной группе испытуемых не давали
такой специальной инструкции, а просто просили научиться при предъявлении стимула
воспроизводить реакцию. Этот эксперимент дал очень четкие результаты: у пруппы,
создава1вшей мысленные картины, припоминание было в полтора раза эффективнее,
чем в контрольной группе. Таким образом, специальная инструкция, видимо, значительно
облегчала заучивание парных ассоциаций. Согласно одной из гипотез, эффективность
мысленных образов объясняется тем, что в результате формирования картины два
предъявляемых существительных хранятся в памяти вместе, как элементы одного
взаимодействия. При последующем предъявлении слова-стимула вспоминается вся
картина, а поскольку эта картина содержит не только компонент-стимул, но и компонент-реакцию,
последняя может быть легко воспроизведена. Например, слово СОБАКА вызывает образ
собаки, едущей на велосипеде, что ведет к припоминанию слова-реакции "велосипед".
Такая интерпретация эффекта мысленных образов получила название гипотезы "концептуальной
вешалки" (Paivio, 1963), так как предполагается, что стимулы играют роль крючков,
на которые при формировании мысленной картины как бы навешиваются реакции.
Мы рассмотрели несколько процессов кодирования: структурирование, опосредование
при помощи элементов естественного языка (в отношении С-Г-С и в других случаях
формирования парных ассоциаций) и образное опосредование. Следующий процесс
кодирования, который мы обсудим, — это организация, изучаемая в задачах
на свободное припоминание.
ОРГАНИЗАЦИЯ ПРИ СВОБОДНОМ ПРИПОМИНАНИИ
Прежде всего следует отметить, что термин "организация" по существу охватывает
все перечисленные выше процессы кодирования. Всякий раз, когда испытуемый оказывает
на входную информацию какое-то воздействие с целью ее систематического видоизменения,
можно говорить о том, что он организует эту информацию. В этом смысле организация
может происходить и на уровне восприятия. Когда испытуемый отделяет букву Ф
от окружающей ее страницы текста он тем самым организует зрительное поле: когда
он расчленяет ряд букв ФРГООН на "ФРГ" и "ООН" (процесс, рассмотренный под рубрикой
"структурирование"), он производит организацию материала: когда он пользуется
словом "Висконсин" как посредником для ВИС-это снова организация, и так далее.
Однако метод свободного припоминания создает одну из самых естественных ситуа;ций
для изучения процессов организации. Для свободного припоминания характерны:
1) наличие всей нужной информации в одном месте — в ДП (припоминая списки слов,
мы используем следы памяти, находящиеся за пределами сенсорных уровней); 2)
свобода перераспределения слов списка в соответствии с организационными наклонностями
испытуемого (поскольку это свободное припоминание; 3) обычно достаточное
число слов в списке, т. е. достаточно обширный материал, который можно было
бы организовать. Все эти условия весьма благоприятны для изучения процессов
организации. Согласно обычному определению, организация при свободном припоминании
возникает в тех случаях, когда наблюдаются систематические различия
между последовательностью элементов в предъявленном списке и их последовательностью
при воспроизведении. Как полагают, такие различия определяются внутренней модификацией
(организацией) входного материала, производимой испытуемым.
ОРГАНИЗАЦИЯ, ОПРЕДЕЛЯЕМАЯ ЭКСПЕРИМЕНТАТОРОМ
Очень часто при изучении организации методом свободного припоминания на нее
оказывает влияние выбор слов, включаемых в список экспериментатором. Так, в
ряде экспериментов (Jenkins а. о., 1958; Jenkins a. Russell, 1952) списки создавались
с учетом степени ассоциации между парами слов. (Степень ассоциации между двумя
словами измеряют частотой случаев, когда испытуемый в ответ на предъявление
одного слова в задании на свободные ассоциации воспроизводит другое слово. Например,
БАБОЧКА и МОТЫЛЕК ассоциированы в высокой степени, БАБОЧКА и САД — в меньшей,
а БАБОЧКА и КНИГА не ассоциированы вовсе.) В одном из экспериментов Дженкинс
и Рассел подобрали 24 пары сильно ассоциированных слов, таких, как МУЖЧИНА-ЖЕНЩИНА,
СТОЛ-СТУЛ и т. п. Затем они разъединили пары, перемешали все слова и предъявляли
их в случайном порядке как список из 48 слов для свободного припоминания. Оказалось,
что при воспроизведении парные слова обнаруживают тенденцию вновь объединяться:
слова, ассоциированные в высокой степени, чаще воспроизводились вместе. Слова
стол и стул в списке могли быть разделены 17 другими словами,
однако испытуемые очень часто называли их одно за другим. Кроме того, Дженкинс,
Минк и Рассел нашли, что чем выше степень ассоциации между парами слов в таком
списке, тем выше общий процент верного воспроизведения и тем чаще ассоциированные
слова вспоминаются вместе. Таким образом, мы видим, что взаимоотношения слов
влияют как на эффективность припоминания, так и на его способ. Создается впечатление,
что испытуемый "организовал" список — модифицировал его таким образом, чтобы
использовать ассоциации между словами. Мы располагаем вескими данными в пользу
того, что список кодируется не в том виде, в каком он был предъявлен, подобно
тому как предъявленный С-Г-С может храниться в памяти не в исходной форме, а
в виде слова-посредника.
Теперь можно поставить вопрос: справедливо ли говорить об организации списка
для свободного припоминания как о процессе кодирования? Вполне может быть, что
испытуемый никак не изменяет список во время его предъявления: структура ДП
могла бы влиять на его припоминание каким-то иным путем — помимо кодирования.
Возможно, например, что слова, ассоциированные в высокой степени, воспроизводятся
вместе потому, что они вместе хранятся в ДП, так что при извлечении
испытуемый находит их одновременно. Этот вопрос представлял определенный интерес
для сторонников теории организации, и, как мы увидим в дальнейшем, во время
кодирования скорее всего действительно происходит известная организация.
Мы видели, что ассоциации между парными словами, разбросанными в списке для
свободного припоминания, могут привести к "организованному" воопроизведению
слов списка. Но мы могли бы пойти еще дальше — включить в наш список уже не
пары, а группы ассоциированных слов. Примером удачного использования
этой идеи служит включение в список слов, означающих объекты одного и того же
класса — по нескольку таких слов для каждого из представленных в списке классов.
Так, например, можно включить несколько членов класса "животные": СОБАКА, КОШКА,
ПТИЦА, РЫБА и т. п. или несколько представителей одного из подклассов этого
класса, например рыб: ФОРЕЛЬ, ТУНЕЦ, КАРП, КОРЮШКА, САРДИНА и т. п., перемешав
их при составлении списка с представителями других классов. Как показали эксперименты,
такой состав списков для свободного припоминания оказывает воздействие, очень
сходное с эффектом парных ассоциаций.
Боусфилд (Bousfild, 1951,
1953) использовал списки, поддающиеся разбивке на классы, в экспериментах
на свободное припоминание следующим образом. В одном эксперименте он
включил в список слова, относящиеся к четырем классам, всего 60 слов, по
15 из каждого класса. Слова предъявлялись в случайном порядке для свободного
припоминания. При этом Боусфилд обнаружил явление, которое он назвал
"группировкой по классам"; у испытуемых наблюдалась тенденция
вспоминать представителей данного класса вместе, даже если они были
разбросаны по всему списку. Это очень напоминает данные Дженкинса и Рассела
о том, что при высокой степени ассоциации между парами слов они
припоминаются вместе, т. е. образуют группировки.
Можно думать, что все
слова, которые относятся к данному классу, должны обнаруживать тенденцию
ассоциироваться друг с другом. Мы можем поэтому задать вопрос: отличается ли чем-то группировка по классам от ассоциативных
группировок,
наблюдавшихся в экспериментах Дженкинса, Рассела и Минка? Ответ,
по-видимому, должен быть утвердительным: эффекты, обусловленные принадлежностью к одному классу,
можно отличить от эффектов ассоциативной близости. Об этом говорит то, что
при включении в список слов, принадлежащих к одному классу, но не
ассоциированных друг с другом, группировка по классам тем не менее
происходит (Bousfield a. Puff, 1964; Wood a. Underwood, 1967). Например,
КАТУШКА, БОЧКА и МЯЧ все относятся к классу "округлых предметов". Они
не ассоциированы друг с другом так, чтобы это можно было выявить методом
свободных ассоциаций, но при определенных условиях они будут
вспоминаться вместе. Есть и другие данные в пользу того, что
принадлежность к одному классу вносит независимый вклад в образование
группировок: когда слова, входящие в список, связаны ассоциативно и, кроме
того, принадлежат к одному классу, эффект группировки выражен сильнее,
нежели в том случае, когда связи между ними только ассоциативные (Cofer,
1965). Например, КРОВАТЬ и СТУЛ относятся к одному и тому же классу и
притом в высокой степени ассоциированы, КРОВАТЬ и СНОВИДЕНИЕ
ассоциированы, но относятся к разным классам. При воспроизведении списков,
составленных из пар первого типа, слова чаще вспоминаются парами, чем
при воспроизведении списков, составленных из пар второго типа.
Боусфилд (Bousfield a. Cohen, 1953) объясняет эффект группировки по классам
следующим образом. При заучивании списка, поддающегося разбивке на классы, все
представители какого-либо класса будут ассоциированы в структуру более высокого
порядка, соответствующую этому классу. Впоследствии припоминание всего лишь
одного представителя активизирует всю эту структуру, что в свою очередь облегчит
припоминание других представителей того же класса; таким образом, все они будут
воспроизводиться вместе, образуя группировку. Например, если список содержит
несколько названий животных, то припоминание слова ЛЕВ может активизировать
класс "животные", что облегчит воспроизведение слов СОБАКА, ЗЕБРА и т. п.
Работы, проведенные после открытия Боусфилдом явлений группировки по классам,
способствовали разъяснению организации этого типа. По-видимому, запоминание
и воспроизведение списка, поддающегося разбивке на классы, связано по крайней
мере с тремя основными процессами (Bower, 1972а): 1) с выяснением того, какие
классы представлены словами, имеющимися в списке; 2) с выработкой особых ассоциаций
между названием класса и теми его представителями, которые содержатся в списке,
3) с припоминанием названий классов.
Прежде
всего испытуемый должен определить, классы представлены в данном списке. Эту
задачу ему можно было бы облегчить, предъявляя сначала всех представителей одного класса, затем другого и так далее-в виде блоков, а не в
виде случайной смеси. И действительно, такое предъявление усиливало эффект
группировки и улучшало припоминание (Cofer а. о., 1966).
Затем
испытуемый должен установить для каждого класса, какие его члены
представлены в списке. Он должен каким-то образом сохранить в памяти факт
наличия в списке определенных представителей каждого класса и ассоциировать их с названием класса, чтобы в дальнейшем, вспомнив
название
класса, иметь возможность припомнить и тех его представителей, которые
содержались в списке. Следует ожидать, что более высокая степень
ассоциации между какими-то членами данного класса и его названием будет
способствовать этому второму этапу и тем самым облегчать запоминание
и воспроизведение. И это действительно так. Например, при изучении частоты
приведения испытуемыми различных примеров, когда их просят назвать объект
данного класса, оказалось, что для класса "металлы" чаще всего
называют железо, а свинец — относительно редко, для класса "четвероногие животные" наиболее частый пример-собака, а мышьредкий, и так
далее (Battig a. Montegue, 1969). И если список для свободного
припоминания составлен из часто называемых примеров соответствующих
классов, то припоминание бывает более эффективным, чем тогда, когда список
состоит из примеров, называемых редко (Bousfield а. о., 1958; Cofer а.
о., 1966).
Наконец, мы предполагаем, что припоминание начинается с
извлечения из памяти названий классов, а эти названия в свою очередь служат
ключом для извлечения тех их представителей, которые содержались в списке.
Поэтому можно ожидать, что факторы, повышающие эффективность извлечения названий классов, должны улучшать припоминание списка. Например,
когда испытуемым при контрольном воспроизведении сообщали, какие классы
были представлены в списке, эффективность припоминания существенно
повышалась (Tulving a. Pearlstone, .1966; Lewis, 1972).
Эксперименты со списками, поддающимися разбивке на классы, помогают понять,
каким образом действует организация материала. По-видимому, заучивание таких
списков — это сложный процесс, в ходе которого из элементов организуются более
сложные единицы, а эти последние могут быть затем декодированы в первоначальные
входные сообщения. В эту схему укладывается все, что мы рассмотрели под общей
рубрикой "организационных процессов". Хотя специфические свойства более крупных
единиц, образующихся в результате организации, могут быть в разных случаях различными
(например, в результате организации классов могут получаться структуры, отличные
от тех, которые просто объединяют близкие слова), построение единиц высшего
порядка с последующим процессом извлечения — сначала этих единиц, а затем и
их компонентов — по-видимому, составляет суть "организации" вообще. Таким образом,
организация включает в себя структурирование, использование вербальных посредников,
группировку по ассоциативной близости и по принадлежности к одному классу и,
как мы увидим далее, "субъективную организацию".
СУБЪЕКТИВНАЯ ОРГАНИЗАЦИЯ
Субъективная организация представляет
собой прямую противоположность только что рассмотренному типу организации, при котором экспериментатор придает списку определенную
структуру. При субъективной организации сам испытуемый придает структуру
списку, который с точки зрения экспериментатора был лишен какой-либо
организации. Это похоже на то, что происходит, когда стимул КОШ наводит
испытуемого на мысль о "кошке". Хотя субъективная организация
может отличаться от организации списка, поддающегося разбивке на классы, в
обоих случаях происходят сходные процессы.
Субъективную организацию (термин, предложенный Tulving, 1962) выявить труднее,
чем намеренно индуцированную организацию вроде создаваемой в рассмотренных выше
списках. Как можно установить, что испытуемый создает определенную организацию
в списке, предъявленном для свободного припоминания? Один из способов состоит
в том, чтобы наблюдать, в каком порядке припоминаются слова. Мы уже знаем, что
если в списке содержатся тесно ассоциированные слова, то они часто вспоминаются
вместе и что члены одного и того же класса, содержащиеся в списках, поддающихся
разбивке, тоже припоминаются вместе. Поэтому можно думать, что при субъективной
организации должен проявляться тот же эффект, т. е. слова, организованные в
такого же рода структуры, должны припоминаться вместе или образовывать группировки
— независимо от того, в каком порядке они предъявляются; поэтому если собрать
данные по ряду проб, проведенных с одним и тем же списком, то скорее всего окажется,
что слова, организованные в ту или иную структуру, всякий раз припоминались
вместе. Короче говоря, следует ожидать, что организация будет проявляться в
припоминании испытуемым слов в какой-то устойчивой последовательности, хотя
в разных пробах слова предъявляются в различном порядке. Именно из таких рассуждений
может быть выведена мера субъективной организации.
Следует упомянуть о двух мерах субъективной организации — мере СО (субъективная
организация; Tulving, 1962) и мере ППП (постоянство от пробы к пробе; Bousfield
a. Bousfield, 1966). Обе они основаны на постоянстве последовательности припоминания:
чем более постоянна эта последовательность у испытуемого от пробы к пробе, чем
больше пар словон припоминает в разных пробах в одинаковом порядке, тем выше
будет мера СО или ППП. Предполагается, что эти меры отражают степень организации,
производимой испытуемым. Таким образом, мы считаем, что чем более выраженнуюорганизацию
он создает, тем более постоянной должна быть последовательность слов при воспроизведении
и соответственно тем выше мера субъективной организации.
Можно ли как-то использовать эти меры? И если можно, то как? На основании того,
что нам известно о влиянии организации, определяемой экспериментатором, следовало
бы ожидать, что субъективная организация списка тоже повысит эффективность припоминания.
Таким образом, можно ожидать, что СО будет коррелировать с припоминанием, т.
е. чем выше мера СО, тем выше окажется эффективность припоминания. Результаты
экспериментов в общем подтверждают это (см., например, Tulving, 1962, 1964).
Вместе с тем, по мнениюнекоторых теоретиков, такая корреляция недостаточно постоянна.
В ответ на это сторонники наличия корреляции высказали предположение, что ошибочна
не сама идея о том, что организация ведет к припоминанию: просто нам следовало
бы использовать более точную меру организации (Postman, 1972; Wood, 1972).
Другие данные о существовании субъективной организации и о ее влиянии на припоминание
получены в экспериментах, в которых было обнаружено, что можно одновременно
повлиять как на организацию материала, так и на его воспроизведение. Например,
испытуемые в задаче на свободное припоминание получают инструкцию, что они должны
группировать определенные элементы вместе. Такая инструкция; приводит к повышению
меры как организации, так и припоминания (Mayhew, 1967). И наоборот, инструкции,
в которых подчеркивалась необходимость кодировать каждый элементотдельно, снижают
и то и другое (Alien, 1968). Эти результаты подтверждают представление о роли
субъективной организации.
Субъективная организация, создающаяся при свободном припоминании, во многом
сходна с организацией, определяемой экспериментатором. Оценка СО служит показателем
того, что на субъективном уровне соответствует группировке по классам; так,
данные о величинах СО говорят о том, что испытуемые создают субъективно детерминированные
группировки. Другая общая черта субъективной организации и организации, определяемой
экспериментатором, — их положительное влияние на припоминание. Как группировка
по классам, так и оценки СО положительно коррелируют с припоминанием. Все это
показывает, что оба типа организации действуют по существу одинаково.
Дальнейшие данные о существенном сходстве между группировкой по классам и субъективной
организацией получили Мэндлер и Пирлстоун (Mandler a. Pearlstone, 1966). В их
эксперименте испытуемым давали стопку из 52 карт, на каждой из которых было
напечатано какое-нибудь слово. Испытуемые должны были разбить эти карты на классы
(от двух до семи классов). Карты перетасовывали, а затем испытуемый многократно
разбивал их на классы, продолжая это до тех пор, пока он не распределял их два
раза подряд одинаковым образом. Важная особенность эксперимента состояла в том,
что одна группа испытуемых была вольна разбивать карты так, как ей вздумается,
тогда как другая должна была следовать определенной инструкции о порядке разбиения
карт. (Для того чтобы обеспечить контроль с учетом различий между разными способами
классификации, каждого испытуемого второй группы просили производить разбивку
так, как это сделал один из испытуемых первой, "свободной" группы.) После выполнения
задания на разбивку каждый испытуемый должен был припоминать как можно больше
слов.
Как и можно было ожидать, Мэндлер
и Пирлстоун обнаружили, что испытуемым второй, "несвободной" группы
требовалось гораздо больше проб для того, чтобы два раза подряд
разбить карты на классы одинаковым образом. Однако эффективность
припоминания в обеих группах была примерно одинакова. Это означает, что
главную роль играла не степень знакомства со словами (поскольку у
"несвободной" группы проб было больше): припоминание определялось
уровнем достигаемой организации. Другим важным результатом было
выявление сильной положительной корреляции между числом классов, на
которое испытуемые разбивали карты, и эффективностью припоминания.
Испытуемые воспроизводили в среднем по пяти слов из каждого созданного ими
класса; поэтому чем больше классов они создавали, тем больше припоминали слов. Это очень похоже на то, что было
отмечено при заучивании списков, поддающихся разбивке на классы (Cohen,
1966; Tulving a. Pearlstone, 1966): если испытуемым удается вспомнить
каких-нибудь представителей данного класса, то обычно они довольно хорошо
припоминают и другие относящиеся к этому классу слова. Поэтому в экспериментах с такими списками суммарная оценка воспроизведения тем выше,
чем больше число классов, из которых вспоминаются хотя бы какие-то
элементы. Это общее сходство между субъективной организацией и организацией,
определяемой экспериментатором, говорит в пользу того, что оба — типа
организации действуют одинаковым образом.
После того как мы до известной степени установили, что субъективная организация,
группировка по классам, ассоциативная группировка, подбор слов-посредников и
структурирование действуют сходным образом, следует разъяснить один момент,
касающийся соотношения между структурированием в кратковременной памяти
(гл. 5), и организацией, обсуждаемой здесь в связи с долговременной
памятью. Характер этого соотношения должен быть ясен, но мы все же остановимся
на нем несколько подробнее. Как уже отмечалось, структурирование — это одна
из форм организации...В сущности структурирование и организация представляют
собой один и тот же процесс. Просто в некоторых случаях используются разные
термины, соответствующие разным методам исследования этого процесса. Если, например,
испытуемый организует набор КОШКА, СОБАКА, РЫБКА в класс "комнатные животные",
выполняя задачу на непосредственное припоминание короткого списка элементов,
то можно считать, что мы изучаем структурирование, так как речь идет о функции
КП, а структурирование-это название для процессов организации, происходящих
в КП. Если же список элементов более длинный и между предъявлением и воспроизведением
проходит довольно много времени, то можно предполагать здесь участие ДП. В этом
случае объединение испытуемым слов КОШКА, СОБАКА, РЫБКА в группу "комнатных
животных" будет называться организацией. Где же происходит организация? Поскольку
она осуществляется во время кодирования, мы вправе локализовать ее в "рабочем
отделе" КП, как это говорилось в главах 5-7. Но поскольку происходящее в КП
кодирование, как мы пола.г.аем, .оказывает влияние и на то, что хранится в КП,
и на то, что переносится в ДП, можно думать, что одни и те же организующие процессы
свойственны обоим видам памяти. Следует подчеркнуть, что термины "организация"
и "структурирование" связаны главным образом с методом исследования, используемым
для изучения этих процессов, и соответственно относятся к тому хранилищу памяти,
функция которого, как нам кажется, преобладает в том или ином случае.
КОГДА ПРОИСХОДИТ ОРГАНИЗАЦИЯ
ПРИ КОДИРОВАНИИ ИНФОРМАЦИИ ИЛИ ПРИ ЕЕ ИЗВЛЕЧЕНИИ?
Итак, мы получили общее представление о том, что такое организация: это формирование
единиц высшего порядка из совокупностей входных элементов. Впоследствии эти
единицы могут быть "декодированы", что ведет к извлечению первоначальных элементов.
Такая схема пригодна независимо от того, удерживается ли информация на короткое
время (как при структурировании) или хранится дольше, и от того, имеет ли вход
какую-либо формальную структуру (как в случае списков, поддающихся разбивке
на классы) или же структуру, воспринимаемую только тем лицом, которое производит
организацию (субъективная организация). Мы говорили об организации как о процессе
кодирования, и только что приведенное описание организации, по-видимому, соответствует
такому представлению. Таким образом, организация может быть процессом, происходящим
во время хранения и направленным на то, чтобы связать несколько элементов в
одну единицу. Согласно этому представлению, организация облегчает кодирование
и хранение информации; при этом предполагается, что разные элементы, хранящиеся
вместе, взаимозависимы. В результате для хранения элементов, входящих в списки
для свободного припоминания, требуется меньше места. Тем самым организация облегчает
припоминание. Она способствует также припоминанию элементов целыми группами,
так как в этом случае достаточно декодировать единицу высшего порядка, чтобы
одновременно извлечь и воспроизвести все относящиеся к ней элементы.
Такой концепции противопоставляется идея независимого хранения и извлечения
(Slamecka, 1968, 1969), согласно которой испытуемый при заучивании списка элементов
прежде всего обращает внимание на общую структуру списка во время его предъявления.
Он удерживает в памяти эту общую структуру. В то же время он запоминает входящие
в список элементы по отдельности и хранит их независимо друг от друга. Согласно
этому представлению, эффект организации выявляется во время извлечения. Когда
приходит время воспроизвести список, испытуемый приводит в действие план извлечения,
которым он руководствуется при поиске в памяти элементов, входивших в список.
Этот план основан на общей структуре списка, которую испытуемый заложил в память
на этапе запоминания. Ввиду такого планового поиска вполне вероятно, что испытуемый
будет находить близкие друг другу элементы примерно в одно и то же время. Он
будет вспоминать их вместе, что приведет к образованию выходных группировок.
Использование плана увеличит и число припоминаемых элементов, так как планируемый
поиск эффективнее случайного поиска.
Два только что изложенных представления различаются в отношении этапа, на котором
создается организация. Согласно первому, организация происходит во время кодирования,
согласно второму — во время извлечения (хотя здесь учитываются также эффекты
кодирования и хранения, поскольку предполагается запоминание общей структуры
списка). Между этими представлениями есть и другое различие: согласно первому
из них, организованные элементы хранятся вместе, а согласно второму — независимо
друг от друга. Однако возможность противопоставления этих двух схем вообще вызывает
сомнения (Postman, 1972). Действительно, есть достаточно оснований рассматривать
организацию как процесс, включающий в себя и кодирование, и извлечение информации;
данные об этом получены в результате исследований, касающихся принципа "специфичности
кодирования" (Thomson a. Tulving, 1970).
СПЕЦИФИЧНОСТЬ КОДИРОВАНИЯ
Принцип специфичности кодирования гласит: "То, что закладывается на хранение,
определяется тем, что воспринимается, и тем, как оно кодируется, а то, что хранится
в памяти, определяет, какие признаки могут быть использованы дляполучения доступа
к тому, что хранится" (Tulving a. Thomson, 1973, р. 353). Другими словами, припоминание--это
результат довольно сложного взаимодействия между процессами кодирования (или
хранения) и извлечения. Для наилучшего доступа к хранящемуся в памяти материалу
нужно, чтобы при его извлечении использовалась та же самая информация, которая
имелась во время кодирования. Это означает, что кодирование входной информации
должно соответствовать признакам, используемым для ее извлечения.
Мы уже упоминали об одном примере специфичности кодирования в связи с изложением
работы Тульвинга и Пирлстоуна (Tulving a. Pearlstone, 1966). Эти авторы предъявляли
испытуемым список, в котором все представители каждого класса были сгруппированы
вместе и каждой такой группе? предшествовало название класса. Затем при контрольном
воспроизведении одной группе испытуемых сообщали названия классов в качестве
признаков для припоминания, а конт.рольной группе этих названий не сообщали.
Оказалось, что группа, получившая такие признаки, припоминала больше слов, чем
контрольная группа. Эти результаты показывают, что предоставление испытуемым
во время проверки той информации, которой они располагали во время заучивания
(в данном случае — названий классов), облегчает припоминание. Эти результаты
согласуются с принципом специфичности кодирования: припоминание было наиболее
эффективным в тех случаях, когда условия при кодировании соответствовали условиям
при контрольном воспроизведении (т. е. при извлечении).
В ряде экспериментов Тульвинга и Ослера (Tulving а. Osier, 1968) и Томсона
и Тульвинга (Thomson a. Tluving, 1970) были получены дополнительные данные по
этому вопросу. Испытуемым предъявляли список слов для свободного припоминания.
В опытах с одной группой испытуемых каждое подлежащее запоминанию слово сопровождалось
другим ассоциированным словом; например, слово ОРЕЛ могло сопровождаться словом
ПАРИТЬ (списки составлялись таким образом, что испытуемый знал, какое из двух
слов ему следовало запоминать, и ему сообщали, что второе слово может помочь
при вспоминании первого). Другой группе испытуемых не давали таких ассоциированных
слов. Во время контрольного воспроизведения некоторым испытуемым в каждой группе
предоставляли ассоциированные слова из списка, а другие не получали таких слов.
В результате испытуемые делились на четыре группы: 1) получавшие ассоциированные
слова на входе и при воспроизведении; 2) получавшие их только на входе, 3) получавшие
их только при воспроизведении, 4) без ассоциированных слов. Результаты были
совершенно четкими. Первая группа превзошла по эффективности припоминания все
остальные, а у второй и третьей эффективность оказалась ниже, чем у четвертой.
Эти результаты служат веским доводом в пользу принципа специфичности кодирования.
Припоминание наиболее эффективно при наибольшем сходстве условий кодирования
и извлечения информации.
Принцип специфичности кодирования изучался главным образом в плане использования
ключевых признаков для припоминания отдельных элементов. Однако этот принцип
поможет нам завершить нарисованную здесь картину свободного припоминания и организации,
так как этот же принцип, по-видимому, вполне приложим и к припоминанию оргашизованных
групп слов. Мы можем теперь попытаться описать "организацию" следующим образом:
когда испытуемому предъявляют список слов, ои при кодировании стремится организовать
их. Это означает, что он будет формировать из нескольиих элементов единицы высшего
порядка. Позже, во время пробы, извлечение из памяти части списка приведет к
припоминанию остальной его части. Процесс извлечеяия включает декодирование
единиц высшего порядка, которые были сформированы во время организации, а это
должно приводить к группировке объединенных при кодировании элементов на выходе,
что также будет облегчать извлечение. Все это будет (происходить так, пока условия
извлечения совместимы с организацией, произведенной во время кодирования и хранения.
Кроме того, извлечение может быть облегчено предъявленнем ключевых признаков,
помогающих восстановить условия, в которых происходило кодирование. Наконец,
следует сказать, что сам процесс извлечения заслуживает гораздо более подробного
анализа; поэтому в следующей главе мы специально сосредоточим внимание на извлечении
информации из долговременной памяти.
Глава 11
Процессы извлечения информации
В предыдущей главе рассматривались процессы кодирования — операции, которые
производятся над входным материалом и облегчают его запоминание. При этом выяснилось,
что, обсуждая запоминание, необходимо рассмотреть также процессы извлечения
информации, на которых и будет сосредоточено внимание в настоящей главе. Для
этого придется вспомнить экспериментальную процедуру, называемую тестом на узнавание,
а также узнать кое-что новое о свободном припоминании. Все это приведет нас
к построению моделей, описывающих процессы извлечения информации из памяти.
УЗНАВАНИЕ
Начнем с метода, при помощи которого изучают узнавание. Типичный эксперимент
состоит в следующем. Сначала испытуемый знакомится со списком элементов — просматривает
его или прослушивает. Затем производится проверка: испытуемому предъявляют некоторые
из элементов списка с добавлением нескольких других, не входивших в список.
Последние называются дистракторами. Испытуемый должен выбрать элементы, содержавшиеся
в списке, отбросив все те, которых в списке не было. Процедура проверки может
быть несколько иной, хотя в общем метод соответствует этому описанию. Например,
можно использовать метод "да — нет" или метод вынужденного выбора (подробнее
см. в гл. 1).
ЭФФЕКТИВНОСТЬ УЗНАВАНИЯ
ПО СРАВНЕНИЮ С ПРИПОМИНАНИЕМ (ВОСПРОИЗВЕДЕНИЕМ)
Одна из важных
особенностей проверки методом узнавания состоит в том, что испытуемый, как
правило, узнает элементы предъявлявшегося ему списка гораздо лучше, чем он
их может припомнить. Если испытуемому сначала предлагают вспомнить элементы списка, а затем проводят тест на узнавание, то
обычно оказывается, что он узнает многие из тех элементов, которые не мог
припомнить.
Шепард (Shepard, 1967) очень убедительно продемонстрировал способность испытуемых
узнавать большое число элементов. Он провел ряд опытов с использованием элементов
трех типов: слов, предложений и картинок. В одном эксперименте испытуемым предъявили
540 слов, каждое из которых было напечатано на отдельной карточке. Испытуемые
просмотрели все эти карточки одну за другой. Затем было проведено 60 проб на
узнавание слов методом двухальтернативного вынужденного выбора. И Шепард обнаружил,
что доля правильных ответов составляет в среднем 88%! Испытуемые, которым было
предъявлено 612 цветных картинок, показали еще лучший результат — 97% правильных
ответов. В третьем эксперименте, в котором предъявляли 612 предложений, верные
ответы составили 89%. Шепарду удалось также уговорить двух приятелей провести
эксперимент с 1224 предложениями; в пробе на узнавание было получено 88% правильных
ответов.
Результаты Шепарда
ясно показывают чрезвычайно высокую эффективность узнавания по сравнению с
припоминанием. Уместно задать вопрос: всегда ли это бывает так? Оказывается, не всегда: можно создать такие условия проверки, при которых
эффективность узнавания будет довольно низкой. Например, можно
использовать в качестве дистракторов элементы, которые сильно ассоциированы
с элементами списка или очень сходны с ними. Мы могли бы, скажем, включить
в список слово КОШКА, а в качестве дистрактора использовать слово
СОБАКА. Такого рода условия снижают эффективность узнавания (см.,
например. Underwood, 1965; Underwood a. Freund, 1968). Или же можно
использовать большое число дистракторов-скажем, предъявлять при проверке
вместе со словами, содержавшимися в списке, 90 альтернативных слов. В
таких условиях трудно узнавать слова из списка (Davis а. о., 1961).
Другая особенность узнавания состоит в том, что его эффективность остается
высокой даже при длительных интервалах удержания. Иными словами, при оценке
методом узнавания создается впечатление, что элементы забываются очень медленно.
В одном эксперименте с короткими списками С-Гили слов при проверке на узнавание,
произведенной через два дня, эффективность оставалась на уровне, близком к 100%
(Postman a. Rau, 1957). Шепард (Shepard, 1967) в одном из упомянутых выше экспериментов
проверял удержание в памяти предъявленных картинок на протяжении 120 дней. Он
подвергал группы испытуемых проверке сразу после предъявления элементов и по
прошествии 2 часов, 3 дней, 7 дней и 120 дней. Как видно из графика на рис.
11.1, забывание имело место, но оно происходило очень медленно.
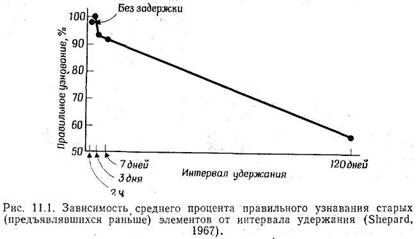
Видимый уровень забывания в течение коротких промежутков времени тоже зависит
от способа проверки. Забывание представляется заметно более медленным, когда
его оценивают методом узнавания (по сравнению с методом припоминания). Узнавание
после коротких интервалов изучали Шепард и Техтсуньян (Shepard a. Teghtsoonian,
1961). Испытуемым давали большую стопку карточек, на каждой из которых было
написано какое-нибудь трехзначное число. Испытуемые должны были просмотреть
все карточки, отмечая относительно каждой из них, встречалось ли данное число
раньше. Конечно, числа, стоявшие на нескольких первых карточках, испытуемый
видел впервые. Но карточки были расположены в стопке таким образом, что после
нескольких первых карточек "старые" карточки (с числами, которые испытуемый
уже видел) и "новые" (с числами, которых, он еще не видел) были расположены
случайным образом и попадались с одинаковой частотой. За исключением нескольких
карточек в основании стопки, встречавшихся только однажды (для того чтобы обеспечить
равную вероятность появления старых и новых карточек), каждое число встречалось
на карточках дважды.
Шепарда и Техтсуньяна особенно интересовал вопрос о том, как изменяется эффективность
узнавания в зависимости от промежутка между первым и вторым появлением данного
числа. Если, например, в каком-то месте последовательность карточек имела вил:
147, 351, 362, 211, 111, 147, то можно ожидать, что испытуемый произнесет "новая"
при первом появлении числа 147 и "старая" — при втором его появлении. В данном
случае промежуток равен четырем, так как число карточек между двумя появлениями
числа 147 равно четырем. Если построить график зависимости правильных ответов
по старым элементам от величины такого промежутка, то получится кривая, представленная
на рис. 11.2. Как показывает эта кривая, процент правильных ответов вплоть до
таких больших промежутков, как 60 элементов, был выше того, который можно было
бы отнести на счет случайности (т. е. правильных ответов было больше, чем если
бы испытуемый отвечал просто наугад). Поскольку в каждом случае вероятность
случайного совпадения составляет 0,5 (элемент либо новый, либо старый), то при
простом угадывании правильные ответы составляли бы 50%. Поэтому, когда процент
правильных ответов выше 50%, мы вправе подозревать, что испытуемый не просто
угадывает, а использует содержащуюся в его памяти информацию, которая помогает
ему достигнуть лучших результатов, чем при случайных ответах. Таким образом,
мы видим, что промежуток, на протяжении которого в подобной ситуации происходит
забывание, составляет около 60 элементов.
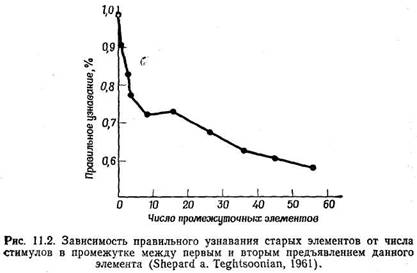
Эти результаты можно сравнить с данными, полученными в сходном эксперименте,
в котором проверялось не узнавание, а воспроизведение: речь идет о результатах
эксперимента Во и Нормана с щифрой-зондом (Waugh a. Norman, 1965), описанных
в гл. 6. Там тоже был промежуток, определявшийся как число цифр между первым
и вторым появлением "зонда", и тоже был показатель сохранения следа в памяти
— припоминание цифры, непосредственно следовавшей за "зондом". Во и Норман установили,
что эффективность припоминания снижалась до уровня угадывания, когда этот промежуток
соответствовал примерно 12 цифрам. Таким образом, несмотря на сходство кривых
забывания, отражающих постепенное снижение сохранности следов по мере увеличения
числа промежуточных элементов, число этих элементов, необходимое для того, что
представляется полным забыванием, совершенно различно. При узнавании какая-то
память о данном элементе еще выявляется даже после 60 промежуточных элементов,
тогда как воспроизведение становится невозможным после 12 промежуточных элементов.
Итак, в той мере, в какой эти опыты можно считать сравнимыми, забывание на протяжении
коротких периодов, измеряемое методом узнавания, очевидно, выражено слабее,
чем при измерении методом припоминания, — точно так же как и на протяжении более
длительных периодов.
ТЕОРИЯ ОБНАРУЖЕНИЯ СИГНАЛА И УЗНАВАНИЕ
Теперь, когда мы знакомы с некоторыми основными фактами относительно узнавания,
настало время заняться теоретической моделью узнавания элемента, хранящегося
в памяти. Это в сущности первая модель извлечения информации, которую мы рассмотрим,
модель процесса узнавания, основанная на теории обнаружения сигнала. Эта модель
позволит нам оценить количество содержащейся в памяти информации, на которой
испытуемый основывает свои суждения при узнавании. Кроме того, она откроет подход
к очень важной проблеме, связанной с тестами на узнавание, — проблеме искажения
результатов из-за угадывания.
Рассмотрим в качестве иллюстрации воображаемый опыт, в котором двум группам
испытуемых предъявляют описок элементов, а затем проверяют узнавание методом
"да — нет". Этот метод состоит в том, что испытуемому при проверке предъявляют
вперемежку элементы, содержавшиеся в списке, и дистракторы и просят его отвечать
"да", если он полагает, что данный элемент был в списке, и "нет", если он думает
что это дистрактор. Допустим теперь, что одной группе испытуемых ("свободной"
группе) говорят, что эффективность узнавания будет оцениваться на основе точности
всех ответов "да" и "нет" — и что за попытки к угадыванию никакие штрафы налагаться
не будут. Другая группа испытуемых ("консервативная") получает несколько иную
инструкцию. Им указывают, что эффективность узнавания будет оцениваться по правильности
ответов "да" и что всякий раз, когда дистрактор будет ошибочно принят за элемент
списка, это повлечет за собой большой штраф. Ясно, что после таких инструкций
разумная стратегия этих двух групп будет совершенно различной. Поскольку испытуемых
первой группы не штрафуют за угадывание, они будут прибегать к нему. Всякий
раз, когда они не будут уверены, старый перед ними элемент или новый, они будут
отвечать наугад. Вторая же группа должна быть очень осмотрительна в отношении
ответов "да"; поэтому в тех случаях, когда у этих испытуемых нет абсолютной
уверенности в том, входит ли данный элемент в состав списка или же это дистрактор,
они будут отвечать, что это дистрактор.
Ввиду такого различия в стратегии эффективность узнавания в этих двух группах
должна быть различной. Прежде всего, если говорить о правильности узнавания
элементов списка, т. е. о проценте случаев, когда испытуемый отвечал "да" при
предъявлении ему такого элемента, то, вероятно, окажется, что у "свободной"
группы этот процент выше. Ведь испытуемые этой группы могли без опасений высказывать
догадки "да", и некоторая доля этих догадок могла оказаться верной. Что касается
испытуемых "консервативной" группы, то они проявляли большую осторожность при
выборе ответа "да". Хотя в значительной части случаев ответ "да" мог бы оказаться
верным, они были вынуждены отвечать "нет" в отношении многих элементов списка.
В результате при проверке на узнавание элементов списка они получают более низкие
оценки. Кроме того, доля верных ответов у испытуемых "свободной" группы может
быть в целом выше, так как им разрешено "угадывать". А поскольку испытуемые
"консервативной" группы во многих случаях, когда им казалось, что предъявленный
элемент входил в список, вынуждены были отвечать "нет", чтобы не рисковать,
они поневоле допускали ошибки.
Смысл описанного эксперимента очевиден. Хотя нет никаких оснований
считать, что эти две группы испытуемых сохраняют в памяти разное
количество информации относительно списка элементов, их оценки в тесте на
узнавание различны. Если бы мы вздумали на основе этих оценок делать
выводы о памяти испытуемых на элементы списка, то мы впали бы в ошибку. Ибо
различия в эффективности узнавания элементов между двумя группами
испытуемых вызваны определенной
тенденцией в их ответах, которая в свою очередь обусловлена инструкциями.
Значит, если мы хотим использовать метод узнавания для оценки запоминания
элементов списка, мы должны найти какой-то способ, позволяющий
учитывать влияние такого рода тенденций и догадок.
Существует несколько способов внесения "поправок на угадывание", позволяющих
получить довольно точные оценки эффективности памяти. Один из них состоит в
том, что используют метод двухальтернативного вынужденного выбора ("да — нет")
и дают скорректированную оценку ответов испытуемого, вычитая из числа верных
ответов число неверных. При этом предполагают, что результаты угадывания распределяются
случайно (т. е. что при угадывании число верных ответов равно числу неверных)
и что всякий раз, когда испытуемый дает неверный ответ, он отвечает наугад.
В таком случае следует ожидать, что число неверных ответов будет отражать только
половину всех тех случаев, когда он отвечает наугад, потому что другая
половина его догадок должна оказаться верной просто по закону случая. Значит,
из числа верных ответов данного испытуемого надо вычесть число догадок, оказавшихся
верными. При двухальтернативном выборе число верных догадок должно быть равно
числу неверных догадок, поэтому скорректированная оценка будет равна общему
числу верных ответов минус число неверных. Если, например, испытуемый, отвечая
на 100 вопросов, прибегал к угадыванию 10 раз, то он в среднем угадает 5 раз
верно и 5 раз неверно. Поэтому из общего числа данных им 95 верных ответов следует
вычесть 5, так как в пяти из своих верных ответов он не помнил, а угадывал.
Однако такой метод внесения поправки некоторые психологи считают неточным.
Дело в том, что, предполагая равное число верных и неверных ответов при угадывании,
мы не учитываем возможную склонность испытуемого чаще давать ответ определенного
типа или его способность лучше узнавать старые элементы, чем дистракторы. Как
мы увидим, теория обнаружения сигнала создает более разумную основу
для внесения поправки на угадывание. Мы рассмотрим этот подход довольно подробно,
так как он используется и для многих других целей. Его можно также рассматривать
как одну из теорий узнавания.
Теория обнаружения сигнала была разработана в связи с задачами обнаружения
звуковых сигналов (Green a. Swets, 1966). В типичном случае такая задача состоит
в следующем. Испытуемый прислушивается к какому-то сигналу (например, тону)
на фоне белого шума (например, шипения или атмосферных помех). Если в определенный
период времени этот сигнал появляется, то испытуемый нажимает на кнопку. При
таких условиях в течение заданного интервала возможны четыре различные ситуации:
1) если сигнал возникает и испытуемый нажимает на кнопку, то регистрируется
попадание; 2) если сигнал возникает, но испытуемый не замечает его и не
нажимает на кнопку, то регистрируется промах; 3) если сигнала нет и
испытуемый не нажимает на кнопку, регистрируется оправданный отказ;
4) если сигнала нет, но испытуемый тем не менее нажимает на кнопку, регистрируется
ложная тревога. Таким образом, в случае попадания или оправданного
отказа реакции испытуемого правильны, а в случае промаха или ложной тревоги
он допускает ошибку.
Задача на обнаружение звукового сигнала непосредственно сопоставима с пробой
на узнавание, проводимой по методу "да — нет". Рассмотрим эксперимент, в котором
испытуемому сначала показывают список элементов, а затем проверяют узнавание;
проверка состоит в том, что ему последовательно предъявляют различные элементы
и он всякий раз должен произнести "да" (или "старый"), если он считает, что
этот элемент уже был в исходном списке, и "нет" (или "новый") , если он считает,
что это дистрактор. В этом случае предъявление старого элемента (такого, который
действительно содержался в списке) подобно появлению тона в задаче на обнаружение
звукового сигнала, а предъявление нового элемента (дистрактора) подобно отсутствию
сигнала. Другое сходство состоит в том, что всякий раз, когда испытуемому предъявляют
для проверки узнавания какой-то элемент, возможен один из четырех случаев (рис.
11.3). Во-первых, элемент может быть старым (т. е. таким, который уже был в
списке) и испытуемый может сказать о нем: "старый"; в этом случае он дает правильный
ответ и, так же как и в задаче со звуковым сигналом, это называется попаданием.
Во-вторых, элемент может быть старым, но испытуемый может ошибочно назвать его
"новым" — это будет промах. В-третьих, элемент может быть действительно
новым и испытуемый так и скажет, что он "новый"; и это, так же как и в задаче
со звуковым сигналом, будет оправданный отказ. И наконец, в-четвертых,
испытуемый может сказать "старый", когда элемент на самом деле новый; это будет
ложная тревога. Таким образом, обнаружение сигнала и проверка узнавания
— задачи аналогичные, и именно поэтому теория, первоначально созданная применительно
к первой из них, была использована для анализа второй.
Обратите внимание на то, что на рис. 11.3 четыре клетки, соответствующие возможным
исходам, не независимы. Поэтому, зная частоту лишь некоторых исходов, можно
вывести частоту остальных. Предположим, например, что испытуемого проверяют
по списку из 20 элементов методом "да — нет". При проверке ему предъявляют 40
элементов — 20 старых и 20 новых. Пусть нам известно, что в отношении 15 старых
элементов испытуемый дал верные ответы, т. е. из тех 20 раз, когда ему предъявляли
старые элементы, он 15 раз ответил "старый". Это означает, что его частота попаданий
равна 75%. Теперь мы можем заполнить клетку, обозначенную "промах", поскольку
нам известно, что он ошибся в отношении 5 из 20 старых элементов — назвал их
"новыми"; значит, частота промахов составляет 25%. (Вообще частота
попаданий и частота промахов в сумме должны давать 100%.) Рассуждая подобным
же образом, мы можем, если нам известно, что частота оправданных отказов у испытуемого
равна 40%, сделать вывод, что он ответил "новый" при предъявлении ему восьми
новых элементов. В таком случае он должен был ответить "старый" при предъявлении
остальных 12 новых элементов, и, следовательно, частота случаев ложной тревоги
составит 12 из 20, или 60%. Таким образом, если известны частоты для одной из
клеток в каждом столбце, то тем самым становятся известны частоты для всех клеток.
Поэтому чаще всего приводятся величины только для двух клеток — по одной из
каждого столбца. Обычно это клетки, соответствующие частоте попаданий и частоте
ложной тревоги.

Ознакомившись с системой классификации ответов при проверке узнавания по методу
"да — нет" (рис. 11.3), рассмотрим основные предположения соответствующей модели.
Первое предположение состоит в том, что любая содержащаяся в ДП информация характеризуется
некоторой степенью сохранности — аналогично предположению об определенной сохранности
(четкости) следа в К.П (гл. 6). Ради удобства мы будем в дальнейшем называть
это "прочностью" информации в памяти. Мы не будем сейчас уточнять, что именно
означает "информация", а сосредоточим свое внимание на хранении в ДП отдельных
элементов, которые могут быть предъявлены в виде списка. Прочность данного элемента
в памяти можно представить себе как степень возбуждения в той ячейке ДП, где
находится этот элемент. Прочность может соответствовать также степени "знакомости"
— чем выше прочность данного элемента в памяти, тем более знакомым он будет
казаться.
Второе предположение состоит в том, что значения прочности элементов, представленных
в списке, распределены нормально. Рассмотрим это предположение несколько подробнее.
После предъявления испытуемому списка каждый элемент в его ДП характеризуется
определенной прочностью. Все элементы по прочности распределяются в соответствии
с так называемой нормальной кривой: большая часть элементов обладает средней
прочностью, несколько элементов обладают очень высокой, а несколько других —
очень низкой прочностью. Рассмотрим также те элементы, которые не предъявлялись
испытуемому, но которые будут использоваться при проверке в качестве новых элементов,
или дистракторов. Мы будем предполагать, что каждый из этих новых элементов
также имеет некоторую собственную прочность и что по своей прочности элементы
тоже распределяются нормально (рис. 11.4). Кроме того, мы предполагаем, что
изменчивость старых элементов в отношении прочности так же велика, как и изменчивость
дистракторов. Поэтому следует учитывать два нормальных распределения-распределение
по прочности элементов, входящих в список, и распределение по тому же признаку
дистракторов.
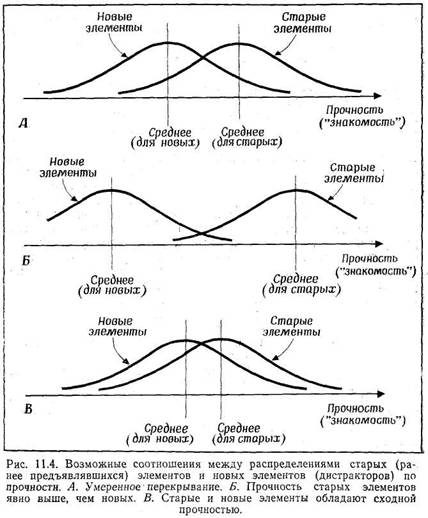
Третье предположение состоит в том, что предъявление какого-либо элемента в
составе списка повышает его прочность в ДП испытуемого. Это означает, что предъявление
элемента повышает его исходную прочность (или "знакомость"), переводя ее с некоторого
начального уровня на какой-то новый, более высокий уровень. Это означает также,
что элементы, не предъявленные испытуемому, будут оставаться на исходном уровне
прочности. Это третье предположение весьма существенно, так как из него следует,
что распределения для старых элементов и для дистракторов будут различаться
по среднему значению прочности. Обычно средняя прочность для старых элементов
выше, поскольку они были только что предъявлены. Прочность новых элементов будет
более низкой — такой же, как у старых элементов до того, как они предъявлялись
в составе списка. Если построить соответствующие кривые, то окажется, что предъявление
списка привело к скачкообразному сдвигу всего распределения для старых элементов
— к смещению его в сторону от распределения для дистракторов.
Относительное положение этих двух кривых — для старых элементов и для дистракторов
— будет варьировать в зависимости от их исходных значений прочности (возможные
варианты представлены на рис. 11.4). Если, например, исходная прочность элементов,
выбранных для предъявления испытуемым, была высокой (элементы эти были очень
привычными или же неоднократно предъявлялись раньше), то теперь прочность их
может сильно возрасти, оставив далеко позади прочность дистракторов. Чаще, однако,
следует ожидать некоторого перекрывания двух распределений. Хотя средняя прочность
старых элементов будет выше, чем средняя прочность новых, все же некоторые из
новых элементов будут обладать более высокой прочностью, чем некоторые из старых.
Рис. 11.4 ясно показывает, что разность между средними значениями этих двух
распределений представляет собой меру расстояния между ними по оси их "знакомости"
или прочности. Чем дальше друг от друга располагаются средние, тем выше прочность
старых элементов по сравнению с новыми. В модели обнаружения сигнала это расстояние
служит мерой, обозначаемой d' — показателем того, насколько сильно
разделены старые и новые элементы. Точнее, d' — это расстояние между
средними двух распределений, выраженное в единицах стандартного отклонения (т.
е. разность между двумя средними, деленная на общее стандартное отклонение этих
распределений). Кроме величины d', необходимо рассмотреть еще одну теоретическую
величину — β. В рамках описываемой модели величину р используют испытуемые при
принятии решения; это тот критерий прочности, на котором испытуемый основывает
свое решение. Для того чтобы понять, как это делается, рассмотрим, что происходит
в эксперименте.
Мы предполагаем, что в результате предъявления испытуемому списка элементов
прочность каждого элемента повышается по сравнению с исходной, причем прочности
всех элементов, независимо от их исходных значений, возрастают на одну и ту
же величину, в результате распределение элементов, предъявленных в составе списка
(теперь мы их называем "старыми"), смещается по оси прочности на некоторую достоянную
величину. Между тем элементы, используемые при проверке в качестве дистракторов
(называемые "новыми" элементами), сохраняют свою прежнюю прочность. Можяо полагать,
что среднее значение прочности этих новых элементов будет меньше, чем среднее
для старых элементов.
Посмотрим теперь, что происходит при проверке испытуемого по этому списку.
Ему предъявляют ряд элементов, из которых одна половина — старые, а другая половина
— новые. Он рассматривает каждый элемент и решает, старый он или новый. Для
того чтобы принять решение, испытуемый выбирает (бессознательно) определенную
величину прочности ( и использует ее в качестве критерия. При предъявлении каждого
элемента во время проверки он оценивает его прочность в ДП (или определяет,
насколько "знаком" ему этот элемент). Допустим, например, что испытуемый оценивает
прочность данного элемента как 100 по принятой им шкале прочности. Назовет ли
он этот элемент "старым" или "новым", зависит не только от прочности элемента,
но и от величины β. Если прочность элемента больше β, то испытуемый
отвечает "старый"; если же она меньше β, то он ответит "новый". Так, например,
если β=90, то наш элемент с прочностью 100 будет назван "старым". Короче
говоря, здесь действует некое правило для принятия решения, которое гласит:
вычислить прочность данного элемента и отвечать "старый", если эта прочность
больше β, в противном же случае отвечать "новый".
Объединим теперь эти представления относительно распределений по прочности
и величин d' и β с различными исходами опыта: "попадание", "промах",
"ложная тревога", "оправданный отказ". Это сделано на рис. 11.5, где представлены
оба распределения прочности и отмечены значения d' и β. Всю область,
лежащую под двумя кривыми, можно разбить на четыре подобласти, представляющие
для нас интерес. Смысл каждой из них зависит от того, под какой кривой она лежит
— под кривой для старых или для новых элементови находится ли она слева или
справа от β. Рассмотрим, например, подобласть, лежащую под кривой для старых
элементов и справа от β. Эта подобласть соответствует тем случаям, когда
при проверке предъявляется один из старых элементов и испытуемый говорит "старый",
— короче говоря, площадь этой подобласти отражает частоту попаданий. Аналогично
этому область, лежащая под кривой для старых элементов, но слева от β, соответствует
частоте промахов. В сумме эти две подобласти образуют всю область, лежащую под
кривой распределения для старых элементов (соответственно на рис. 11.3 эти две
частоты в сумме дают 100%). Под кривой распределения для новых элементов можно
найти подобласти ложной тревоги (справа от β) и оправданных отказов (слева
от β). Таким образом, вся область, лежащая под двумя кривыми распределения,
делится на четыре подобласти, которые соответствуют четырем возможным результатам
проверки по методу "да — нет".
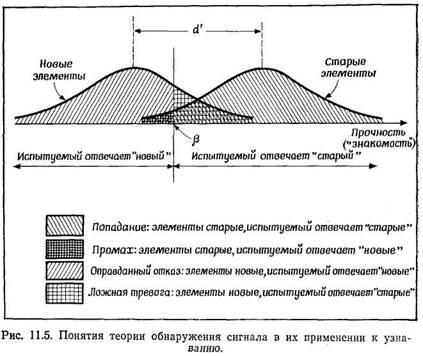
Теперь наша частичная модель процесса узнавания уже содержит представления
о прочности следов памяти, их распределении по этому признаку и правилах принятия
решения. Для того чтобы понять, каким образом это дает нам возможность определять
эффективность узнавания, исключив влияние угадывания, мы должны рассмотреть,
что происходит при изменении величин d' и β. На рис. 11.6 представлены
различные возможности. На рис. 11.6,A можно видеть, как изменяется эффективность
узнавания при изменении d'. Возрастание d' означает увеличение
разницы в прочности старых и новых элементов. При очень больших d'
эта разница очень велика и испытуемый без труда может отличить старые элементы
от новых. Если же d' невелико, то различать эти элементы становится
трудно. Таким образом, величина d' — это по существу мера нашей чувствительности
к различию между старыми и новыми элементами, и ее нередко называют даже "истинной"
чувствительностью. Она отражает информацию, содержащуюся в памяти, — различную
прочность в ДП предъявлявшихся элементов и дистракторов. Именно для того, чтобы
получить оценку величины d' в чистом виде, мы стремимся исключить
влияние угадывания. Обратите внимание, что на рис. 11.6, А при постоянстве р
и возрастании d' (которое соответствует подлинному возрастанию того,
что можно извлечь из памяти, т. е. подлинному повышению "чувствительности" к
старым элементам) частота попаданий, но не частота случаев ложной тревоги —
будет возрастать. Это обусловлено тем, что по мере того как испытуемый становится
более чувствительным, ему становится легче отличить старый элемент (при его
появлении) от новых.
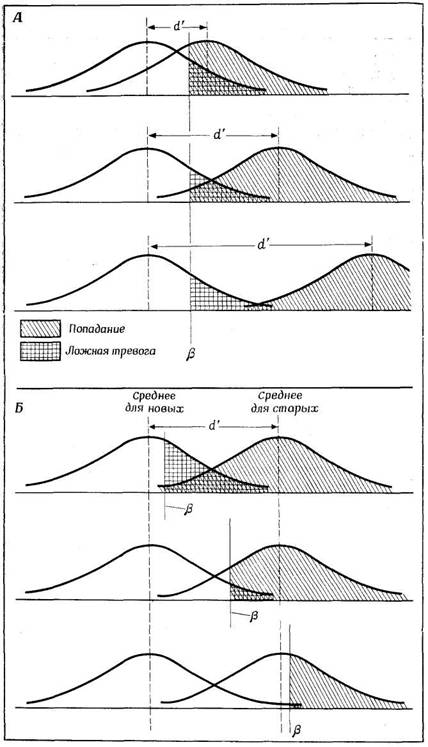

Рассмотрим теперь рис. 11.6, .Б. Здесь показано, что происходит, когда величина
β изменяется, а d' остается постоянной. В этом случае испытуемый
изменяет критерий, на основании которого он принимает решения, хотя количество
информации в его памяти не изменилось-его истинная чувствительность к старым
элементам осталась прежней. В сущности, изменяется стратегия угадывания. При
очень низких значениях β элементу достаточно обладать весьма небольшой прочностью,
чтобы испытуемый назвал его "старым". Соответственно он будет произносить "старый"
очень часто, правильно оценивая почти все те элементы, которые и в самом деле
старые, но допуская много ошибок в отношении новых элементов. Короче говоря,
у него будет большая частота попаданий, но при этом и большая частота случаев
ложной тревоги. При высоких значениях β наблюдается обратная картина. Испытуемый
действует очень осмотрительно и говорит "старый" редко — только в тех случаях,
когда он вполне уверен в правильности ответа, а это возможно только в отношении
очень хорошо знакомых элементов. Частота попаданий сравнительно небольшая, так
как испытуемый часто отвечает "новый" при виде старых элементов просто из осторожности;
вместе с тем редки будут и случаи ложной тревоги, поскольку он нечасто будет
отвечать "старый" в отношении новых элементов. Таким образом, мы видим, что
если величина d' остается постоянной, то сдвиги р приводят к изменению
частоты как попаданий, так и случаев ложной тревоги, и притом в одном и том
же направлении. При возрастании β обе эти частоты снижаются.
Характер изменения частот попаданий и ложной тревоги при изменениях d'
и β дает возможность использовать модель обнаружения сигнала для внесения
поправок на угадывание. Для каждой пары значений этих частот есть соответствующее
значение d'. Именно это и позволяет исключать эффекты угадывания.
При любом изменении β частоты как попаданий, так и случаев ложной тревоги
изменяются, однако их новые значения будут связаны с тем же самым d',
что и прежде; иными словами, испытуемый может изменить свою стратегию угадывания
(например, если начать штрафовать его за случаи ложной тревоги), и это может
привести к новой частоте попаданий и к новой частоте случаев ложной тревоги,
но эта новая пара значений будет соответствовать прежнему значению d'.
В отличие от этого при изменении истинной чувствительности к старым элементам
(например, в случае вторичного предъявления списка, которое приводит к повышению
прочности старых элементов) изменяется частота попаданий без одновременного
изменения частоты случаев ложной тревоги. При этом новое сочетание этих частот
будет соответствовать новому значению d'. Короче говоря, оценка прочности
следов памяти определяется парой величин — частотой попаданий и частотой случаев
ложной тревоги, а не какой-либо из этих частот в отдельности. И по характеру
изменения этих парных величин можно судить о том, что изменилось — истинная
чувствительность (d') или же критерий β.
Экспериментаторы, применяющие метод обнаружения сигнала, пользуются специальными
таблицами, в которых приведены величины d' для каждой пары частот
попадания и ложной тревоги. С помощью такой таблицы экспериментатор может установить,
действительно ли та или иная процедура, которая могла бы изменить частоты попадания
и ложной тревоги, изменяет d'. Если изменилась лишь стратегия угадывания,
то эти две частоты изменятся одновременно, а величина d' будет для
новых значений этих частот такой же, как и для старых. Таким образом, используя
d', вместо того чтобы просто выражать число верных ответов в процентах,
можно вносить поправки на угадывание теоретически обоснованным способом.
Более того, теория
обнаружения сигнала позволяет представить проблему узнавания в таком
плане, что ее можно, в сущности, рассматривать как теорию памяти. Смысл ее
сводится к следующему: предъявление элемента ведет к повышению его
прочности или, если угодно, к повышению степени его "знакомости" или к
возбуждению соответствующей ячейки в памяти (выбор того или иного из этих
выражений не имеет большого значения: все они использовались в то или
другое время). Теория эта утверждает также, что испытуемый в состоянии
оценить степень "знакомости" любого предъявляемого ему элемента, а
затем использовать эту оценку для того, чтобы решить, входил ли данный
элемент в состав списка. Если элемент кажется достаточно знакомым, чтобы
можно было думать, что он входил в список, то испытуемый оценит его как
"старый". В зависимости от различных обстоятельств его критерий
"достаточной знакомости" может изменяться.
Воспользуемся этой теорией для того, чтобы объяснить некоторые результаты экспериментов
по узнаванию. Рассмотрим, например, что произойдет, если использовать как дистракторы
слова, ассоциативно связанные со словами, входящими в список. Так, можно было
бы предъявить в качестве дистрактора слово СОБАКА при наличии в списке слова
КОШКА. Как мы знаем, результаты узнавания в таких случаях снижаются. Это довольно
легко объяснить с помощью нашей модели: достаточно предположить, что предъявление
списка косвенным образом повышает прочность слов, сходных или ассоциированных
с его элементами. Ко времени проверки их прочность окажется поэтому выше прочности
большинства других элементов, которые могут быть использованы в качестве "новых",
и перекрывание распределений соответственно увеличится. Более сильное перекрывание
означает меньшую величину d'; поэтому при сходных или ассоциированных
дистракторах результаты проб на узнавание будут хуже.
Рассмотрим еще один известный факт-то, что редко встречающиеся слова обычно
узнаются лучше, чем слова встречающиеся часто (Shepard, 1967; Underwood a. Freund,
1970). Здесь имеется в виду частота использования данного слова в естественном
языке, например в литературе. Существуют таблицы частот различных слов (см.,
например, Thorndike a. Lorge, 1944), и в экспериментах с использованием слов
их частоту нередко произвольно варьируют. Влияние "частоты" слов на эффективность
узнавания можно объяснить с помощью теории обнаружения сигнала примерно так
же, как объясняется влияние ассоциированных дистракторов (Underwood a. Freund,
1970). Мы можем предположить, что при предъявлении того или иного слова прочность
других слов, в высокой степени ассоциированных с ним, в силу этой ассоциации
несколько возрастает. Для часто встречающихся слов, входящих в список, таких
ассоциированных слов, прочность которых возрастает, будет довольно много, и
большая часть их тоже будет относиться к весьма употребительным словам. Некоторые
из слов, прочность которых будет таким косвенным путем повышена, сами окажутся
в списке, тогда как другие могут встретиться среди дистракторов. Если предположить,
что этот косвенный эффект сильнее скажется на элементах-дистракторах, обладающих
сравнительно низкой прочностью, чем на элементах списка, прочность которых и
так уже достаточно высока, то из этого следует, что увеличение прочности дистракторов
(соответственно сдвигающее кривую их распределения) должно перевешивать любые
влияния на другие элементы списка. В итоге это приведет к значительному перекрыванию
распределении старых и новых элементов при предъявлении часто встречающихся
слов вследствие косвенного повышения прочности слов, ассоциированных с этими
последними.
Рассмотрим теперь список, состоящий из слов, встречающихся редко. Эти слова
вызывают сравнительно мало ассоциаций и поэтому индуцируют повышение прочности
лишь сравнительно немногих слов. Сдвиг прочности элементов-дистракторов будет
при этом очень небольшим, а потому значительного перекрывания распределений
старых и новых элементов не будет. В результате значение d' для редких
слов будет выше, чем для слов, встречающихся часто, что и позволяет объяснить
влияние встречаемости слов на их узнавание.
С помощью модели обнаружения сигнала можно также интерпретировать забывание,
если предположить, что при.рост прочности, обусловленный предъявлением, со временем
постепенно исчезает и распределение старых элементов медленно сближается с распределением
новых элементов, все больше перекрываясь с ним. Таким образом, d'
уменьшается и может в конце концов дойти до нуля.
Как можно видеть, эта теория позволяет объяснить ряд особенностей узнавания
и в то же время дает возможность отделить память испытуемого (d')
от процесса принятия решения (β). Вероятно, некоторые из этих объяснений
покажутся несколько запоздалыми, однако они хорошо укладываются в теорию. Итак,
в целом можно удовлетвориться — по крайней мере временно — моделью обнаружения
сигнала как теорией извлечения. Она описывает, каким образом происходит воспроизведение
информации, хранящейся в памяти; процесс принятия решения включает здесь оценку
прочности предъявленного элемента и внутреннее сравнение ее с некоторым стандартом.
Таким образом, в той мере, в какой эта модель описывает процессы, происходящие
при получении информации из памяти, ее можно рассматривать как модель извлечения
информации.
Может показаться, что для построения модели узнавания, в сущности, не требуется
детально разработанной теории извлечения информации: что, собственно, нужно
еще извлекать, если то, что должно быть извлечено, предъявляется испытуемому
извне? Как мы увидим, информация в самом деле извлекается при узнавании того
или иного элемента. Однако важная роль извлечения информации в смысле поиска
в памяти чего-то определенного особенно четко выступает в случае припоминания
(воспроизведения). Поэтому настало время снова заняться припоминанием и постараться
создать теорию извлечения информации, которая включала бы и этот процесс.
ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ И ВСПОМИНАНИЕ
О припоминании нам уже известно довольно многое. Мы рассматривали,
например, интерпретации кривой зависимости припоминания от места в ряду,
различия, связанные с модальностью, влияние организации, определяемой
экспериментатором, и субъективной организации. Прежде чем продолжить
раос1мотре.ние свободного вопомянания, попытаемся обрисовать основной
характер проблемы. Процедура свободного вспоминания интуитивно
представляется экспериментальным методом, наиболее близким к изучению
того, что мы обычно понимаем под словом "вспоминать".
Боуэр
(Bower, 1972а) обратил внимание на сходство между свободным
воспроизведением списка слов и припоминанием в ситуациях, возникающих вне
лаборатории. Он указывает, что в наиболее общем смысле свободное
припоминание соответствует воспроизведению всех элементов, входящих в
определенное множество. Например, вам могут предложить припомнить
все слова списка, который вам только что показали, назвать всех президентов
США, перечислить всех, кого вы видели на вечеринке, или же вспомнить
длительность интервалов удержания в эксперименте Петерсонов (гл. 6). В
лаборатории, конечно, свободное припоминание обычно заключается в
воспроизведении всех элементов списка, который был предъявлен ранее.
В общей форме припоминание можно описать как процедуру, при которой испытуемому
сначала предъявляют набор подлежащей запоминанию информации, а затем дают тот
или иной "ключ" — признак, помогающий извлечь и воспроизвести нужную, информацию.
Экспериментатор может использовать временной ключ (например: "Припомните список,
который вы заучивали в прошлый понедельник") или порядковый ключ (например,
"Припомните список, который вы заучивали до этого списка"). В повседневной жизни
вспоминание тоже обычно вызывается и направляется тем или иным "ключом". Это
может быть прямой вопрос, как бывает, скажем, на экзамене. Или это может быть
запах, воскрешающий в памяти какое-то событие. Ключи, способствующие извлечению
информации из памяти, могут быть также внутренними, как, например, чувство голода,
заставляющее вспомнить о том, что вы забыли позавтракать. Действующие во всех
этих случаях ключи аналогичны тем, которые дает испытуемому экспериментатор,
когда он говорит: "Припомните предыдущий список".
Тот факт, что припоминание обычно происходит при участии подобного рода ключей,
указывает также на сходство между свободным припоминанием и методом парных ассоциаций.
В некотором смысле свободное вспоминание сходно с припоминанием второго компонента
парной ассоциации: компонент-стимул — это ключ, а компонент-реакция — это некоторое
множество реакций: все элементы, входящие в запоминаемый набор. Если, например,
испытуемый должен заучить два списка, в каждый из которых входит по нескольку
элементов, то результаты этого могут выразиться в том, что стимул ПЕРВЫЙ СПИСОК
будет ассоциироваться у него с одним набором элементов, а стимул ВТОРОЙ СПИСОК
— с другим.
МОДЕЛЬ ПРИПОМИНАНИЯ
Как происходит припоминание? Довольно детальную теорию этого процесса разработали
Андерсон и Боуэр (Anderson a. Bower, 1972, 1973) в рамках своей концепции памяти
как ассоциативной сети (она была описана в гл. 8 при рассмотрении предложенной
этими авторами модели АПЧ), Согласно их модели, при заучивании испытуемым списка
слов для последующего воспроизведения происходит ряд процессов (рис. 11.7).
Прежде всего, когда испытуемому предъявляют одно из слов, входящих в список
(например, КОШКА), он помечает соответствующую этому слову ячейку долговременной
памяти (ДП), ассоциируя ее с определенной "меткой списка" (например, он может
ассоциировать с этой ячейкой высказывание: "В этом списке я заучил слово "кошка").
Он следует также по ассоциативным путям, отходящим от этого слова, в поисках
других слов, которые тоже помечены как входящие в список. Например, идя по одному
из путей в ДП, соединяющему слово "кошка" со словом "собака" (как, например,
в высказывании "Кошки преследуют собак"), он может обнаружить, что "собака"
также ассоциирована с меткой списка. (Например, высказывание, соединяющее слова
"кошка" и "собака", может входить в состав высказывания, отмечающего его связь
с заучиваемым списком.) Итак, при заучивании того или иного слова оно получает
метку, указывающую на его принадлежность к данному списку, и все пути, по которым
следует испытуемый в недолгом поиске, ведущемся от этого слова, получают такую
же метку, если они приводят к другим словам, входящим в список. По сути: дела
это означает, что испытуемый, заучивая список, определенным образом организует
его. Предполагается также, что он отбирает небольшую группу слов, особенно богатых
связями с другими словами списка. Этому "исходному набору" придается особое
значение при образовании ассоциаций со словами, входящими в список, поскольку
слова этого набора будут использоваться в качестве начальных точек при извлечении.
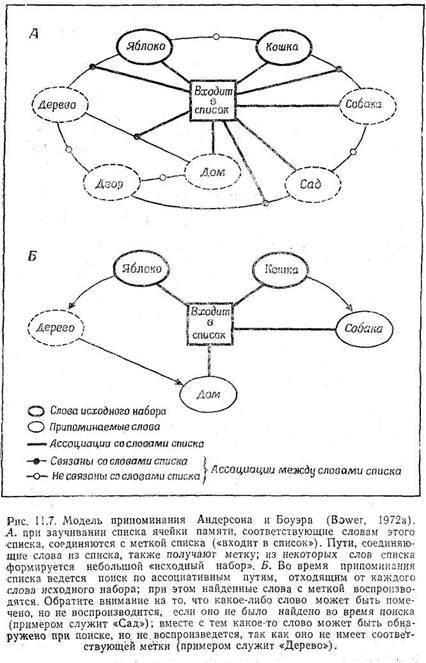
Извлечение, согласно модели Андерсона — Боуэра, начинается (пйсле первоначального
вспоминания всех слов, которые могут оказаться в кратковременной памяти) со
слов, входящих в "исходный набор". Выбирается одно из этих слов, и прослеживаются
ассоциативные пути от ячейки в ДП, соответствующей этому слову, в поисках других
слов, связанных с меткой списка. При этом поиск ведется только по тем путям,
которые были помечены прежде как ведущие к словам из списка, поскольку невозможно
пройти по всем путям, отходящим от данного слова. Если при этом встречаются
слова, несущие метки о принадлежности к списку, то эти слова воспроизводятся.
Если такой процесс приводит наконец к какому-то слову, от которого не идет ни
одного помеченного пути, то испытуемый возвращается к исходному набору; из него
берется какое-нибудь другое слово, и опять начинается обследование путей. Процесс
припоминания заканчивается тогда, когда в исходном наборе не останется ни одного
неиспользованного слова.
Согласно этой модели, ошибки в процессе припоминания возникают вследствие
вероятностного характера пометки ячеек, соответствующих отдельным словам, и
ассоциативных путей. Это означает, что слово не обязательно будет помечено как
входящее в список и что путь, соединяющий два входящих в список слова, тоже
не обязательно будет помечен. Нельзя также твердо рассчитывать на то, что исходный
набор будет достаточно богат связями, чтобы от его слов можно было добраться
до каждого слова, входящего в список. Все это ведет к ошибкам в припоминании.
В общем виде модель Андерсона — Боуэра можно описать следующим образом. Сначала
происходит изучение запоминаемых элементов, в результате которого они подвергаются
организации: ассоциируются с каким-нибудь общим для них названием и друг с другом.
Затем при помощи какого-либо "ключа" (например, инструкции начать воспроизведение
списка) инициируется припоминание. Ключ подает сигнал в ту ячейку ДП, от которой
должен начаться процесс припоминания. Этот процесс состоит в том, чтобы следовать
по ассоциативным путям, отходящим от разных слов, связанных с данным ключом.
Это можно назвать процессом поиска, так как при этом разыскиваются помеченные
элементы из запоминаемого набора. При нахождении таких элементов они воспроизводятся.
Следовало бы отметить, что нахождение ивоспроизведение составляют отдельный,
дополнительный этап. При поиске по различным путям ДП неизбежно будут иногда
встречаться элементы, не входящие в запоминаемый набор. Например, если испытуемого
просят вспомнить президентов США, он может извлечь из памяти имя Эйзенхауэра,
а затем Стивенсона. Но хотя Стивенсон и ассоциируется с Эйзенхауэром, это вовсе
не значит, что он был одним из президентов. Поэтому в отношении элементов, обнаруживаемых
в процессе поиска, приходится принимать определенные решения. Входит ли данный
элемент в заданный набор или нет? (В модели Андерсона — Боуэра этот вопрос формулируется
иначе: "Помечен он соответствующим образом или нет?") Таким образом, припоминание
мыслится как процесс, состоящий из поиска элементов и принятия решений в отношении
находимых элементов.
При такой характеристике процесса припоминания возникает ряд проблем: наше
описание этого процесса не столь полно, как это кажется. Однако ассоциативно-сетевая
модель Андерсона и Боуэра дает довольно много сведений относительно припоминания;
она помогает, например, объяснить эффекты организации, обсуждавшиеся в предыдущей
главе. По-видимому, можно сформулировать следующее общее правило: все, что облегчает
ассоциации между элементами запоминаемого набора, обегчает последующее вспоминание.
Это происходит потому, что любая организация хоть немного, но облегчает процессы
изучения и поиска — пометку элементов и прослеживание отходящих от них путей.
При наличии у списка ассоциативной структуры пути (связи) между его элементами
будут более многочисленны и более "удобны".
СРАВНЕНИЕ ПРОЦЕССОВ УЗНАВАНИЯ И ВОСПРОИЗВЕДЕНИЯ
На данном этапе у нас имеются
две гипотезы или теории "вспоминания". Их можно рассматривать как
теории извлечения информации, поскольку они касаются вопроса о том,
каким образом вновь становится доступной информация, хранящаяся где-то в
памяти. Однако эти две теории совершенно различны. Теория узнавания
основана на представлении о "прочности" следов и о довольно сложном
процессе принятия решения. Теория припоминания основывается на таких
понятиях, как ассоциативные пути и поиск. В извлечении информации,
по-видимому, участвуют различные процессы в зависимости от того, изучаем
ли мы узнавание или припоминание. Но различны ли в действительности
процессы извлечения информации при узнавании и припоминании? И если
различны, то в чем именно?
ГИПОТЕЗА ПОРОГА
Вопрос о том, чем узнавание отличается от припоминания, не нов. Эта проблема
не переставала интересовать психологов с тех самых пор, как понятия узнавания
и припоминания впервые были четко дифференцированы и когда было замечено, что
в тестах на узнавание эффективность памяти оказывается более высокой (McDougall,
1904). Одной из первых лопыток объяснить это различие была "гипотеза порога".
Эта гипотеза очень проста: в ней утверждается, что эффективность как узнавания,
так и припоминания зависит от "прочности" элементов (т. е. эффективности их
следов) в памяти. Согласно этой гипотезе, для того чтобы элемент можно было
узнать, его прочность должна достигать определенной величины, которая называется
порогом для узнавания. Существует также определенная величина прочности,
необходимая для того, чтобы элемент можно было вспомнить; эта величина называется
порогом для припоминания. Предполагается, что порог для припоминания
выше, чем для узнавания; в этом и состоит сущность гипотезы.
Посмотрим, что это означает. Из этого прежде всего следует, что некоторые элементы,
обладающие очень высокой прочностью, будут как припоминаться, так и узнаваться.
Другие, обладающие очень низкой прочностью, не удастся ни вспомнить, ни узнать.
Наконец, третьи — с промежуточной прочностью (выше пороговой для узнавания,
но ниже пороговой для припоминания) — будут узнаваться, но не припоминаться.
Это позволяет объяснить тот факт, что проверка на узнавание дает обычно лучшие
результаты, чем проверка на припоминание.
Кинч
(Kintsch, 1970) провел детальное сравнение процессов узнавания и
вспоминания на основе обзора данных за и против пороговой гипотезы. Он
указывает, что если какая-нибудь переменная влияет на узнавание и
припоминание одинаковым образом, то это можно рассматривать как довод в
пользу гипотезы порога. Но если удастся найти хотя бы одну переменную,
которая действовала бы на эти два процесса по-разному, то это вызовет
сомнение в справедливости гипотезы. Одним из доводов в пользу гипотезы
порога служат упоминавшиеся в этой главе данные о том, что хотя забывание протекает во времени по-разному, оно представляет собой функцию
числа элементов в промежутке между предъявлением и тестированием как при
узнавании, так и при воспроизведении, причем форма кривой забывания в
обоих случаях одинакова. Такие переменные, как скорость предъявления
списка и число предъявлений, тоже оказывают одинаковое влияние; в обоих
случаях наблюдается сходная зависимость от места в
ряду-эффект начала и эффект конца (Shiffrin, 1970; см. также гл. 2). Все это
легко объяснить на основе гипотезы порога (что говорит в ее пользу), если
допустить, что упомянутые факторы повышают или понижают прочность
элементов, так что эффективность узнавания и припоминания соответственно
изменяется в одном и том же направлении.
Предположим теперь, что найдена такая переменная, которая улучшает узнавание,
но ухудшает припоминание. Повышение эффективности узнавания означает, что внесенное
изменение повысило прочность элементов в памяти, однако ухудшение припоминания
говорит о прямо противоположном действии. Но поскольку гипотеза порога пытается
объяснить оба эффекта на основе одной и той же идеи, такие факты, возможно,
заставили бы отвергнуть ее. Ибо если существует лишь какой-то один механизм,
лежащий в основе как узнавания, так и припоминания, то каждый отдельный переменный
фактор сможет вызвать изменение только в одну сторону: узнавание и припоминание
могут или оба улучшиться, .или оба ухудшиться, но они не могут измениться в
разных направлениях.
Существуют ли переменные, влияющие на узнавание и припоминание
по-разному? Оказывается, есть несколько таких переменных (Kintsch, 1970).
Наиболее важная из нихчастоты слов. Напомним, что оценка частоты данного
слова определяется его встречаемостью в естественном языке. Неоднократно указывалось, что широко употребляемые слова
припоминаются
лучше, чем слова, встречающиеся редко. При прочих равных условиях, если
предъявить испытуемым список слов и попросить их воспроизвести эти слова,
эффективность припоминания окажется гораздо выше, когда в этот список
входят часто встречающиеся слова, чем тогда, когда он состоит из
редких слов. Однако при узнавании получаются прямо противоположные
результаты. При включении в список часто встречающихся слов проверка на
узнавание дает худшие результаты, чем при включении редких слов. Редко
встречающиеся слова узнавать легче. Эффект этой переменной (и других
переменных, по-разному влияющих на узнавание и воспроизведение)
показывает, что гипотеза порога не в состоянии объяснить различия между
узнаванием и припоминанием.
ГИПОТЕЗА ДВУХ СЛЕДОВ
Другую гипотезу (Adams, 1967) можно назвать гипотезой двух следов. В отличие
от гипотезы порога она утверждает, что узнавание и припоминание зависят от разных
механизмов. а именно — от разных комплексов информации, содержащейся в памяти.
Согласно этой гипотезе, предъявление какого-либо элемента ведет к образованию
в памяти двух информационных комплексов. (Такой информационный комплекс нередко
называют следом; вообще след того или иного события в памяти — это
то, что в ней остается, после того как само событие миновало.) Существуют лингвистические
(вербальные) следы памяти и образные (перцептивные) следы. Первые представляют
то или иное событие (или объект) в вербальной форме, а вторые — в форме, более
близкой к его сенсорному восприятию. Например, — слово БОЛЬШОЙ после зрительного
предъявления может сохраняться в виде осмысленного вербального элемента или
в образной форме. По этой гипотезе узнавание основывается на перцептивном следе,
тогда как при воспроизведении используется только вербальный след. В гл. 12
образные следы будут рассмотрены более подробно; однако один недостаток этой
гипотезы ДВУХ следов нетрудно увидеть уже сейчас, если рассмотреть, как влияют
на узнавание слова-дистракторы, в высокой степени ассоциированные со словами,
входящими в список. Здесь проявляется отрицательный эффект семантического сходства:
узнавание ухудшается, когда элементы-дистракторы тесно ассоциированы с элементами
списка. Гипотеза двух следов, согласно которой узнавание основано на перцептивных,
а не на вербальных следах, не позволяет объяснить эти наблюдения.
ГИПОТЕЗА ДВУХ ПРОЦЕССОВ
Третья гипотеза, предложенная для объяснения различий между узнаванием и воспроизведением,
— это гипотеза двух процессов (Anderson a. Bower, 1972; Kintsch, 1970). В последние
годы этой гипотезе уделялось много внимания. Преимущество ее в том, что она
не только объясняет упомянутые различия, но и позволяет объединить теории узнавания
и припоминания. Гипотеза двух процессов сглаживает несоответствия между нашими
представлениями о прочности (применительно к узнаванию) и о процессах поиска
(применительно к припоминанию). Это достигается благодаря тому, что припоминание
(воспроизведение), согласно этой гипотезе, включает узнавание в качестве субпроцесса.
Напомним, что по описанной ранее теории припоминание складывается из процессов
поиска (прослеживание путей в ДП и нахождение нужных элементов) и принятия решения
(о том, следует ли воспроизводить найденные элементы). В гипотезе двух процессов
такая последовательность событий принимается в качестве модели для припоминания,
и, кроме того, вводится предположение о том, что узнавание соответствует процессу
принятия решения; иными словами припоминание складмвается из поиска и узнавания.
При этом предполагается, что на стадии принятия решения происходят те же процессы,
которые участвуют в узнавании, — процессы, описываемыетеорией обнаружения сигнала.
Таким образом, мы приходим к выводу, что узнавание — это, по существу, припоминание
(воспроизведение), из которого исключены процессы поиска.
Очевидно, что гипотеза двух процессов обладает немалыми достоинствами. Допуская,
что для узнавания и воспроизведения используются одни и те же виды хранящейся
в памяти информации, она избегает (в отличие от гипотезы двух следов) добавления
еще одного типа памяти к уже имеющемуся перечню. Предполагая участие в припоминании
и узнавании отделимых друг от друга процессов, она позволяет понять, почему
некоторые факторы влияют на эти два проявления памяти по-разному. Кроме того,
сохраняя для узнавания концепцию прочности, она может объяснить все те данные,
которые объясняет модель обнаружения сигнала. И при всем том в ней остается
место для участвующих в припоминания процессов поиска, которые позволяют понять,
почему организация материала облегчает его воспроизведение (см. гл. 10). Таким
образом, создается впечатление, что гипотеза двух процессов, объединяя наши
самостоятельные теории узнавания и припоминания, сочетает в себе достоинства
обеих этих теорий.
Какого рода данными в пользу модели двух процессов мьг располагаем — помимо
той способности объяснять уже известные факты, которой она, по-видимому, обладает?
Эта модель получила бы новое подкрепление, если бы оказалось, что какие-то факторы
по-разному влияют на два компонента процесса припоминания-на поиск и на принятие
решения. Такие данные, если бы их удалось получить, по крайней мереподтверждали
бы возможность разделить эти два этапа, обособленность которых, безусловно,
составляет важную черту обсуждаемой модели. Один из экспериментов в этом направлении
провел Кинч (Kintsch, 1968). Он определял запоминание списков, поддающихся разбивке
на классы, применяя как метод узнавания, так и метод припоминания. В его экспериментах
использовались списки двух типов: списки, которых каждое из слов было сильно
ассоциировано с названием своего класса, и списки с невысокой степенью таков
ассоциации. Благодаря такому подбору слов Кинч по существу варьировал уровень
структурированности списков. Как и следовало ожидать, оказалось, что при низкой
структурированности свободное припоминание менее эффективно, чем при высокой
структурированности, однако эффективность узнавания для обоих списков была одинаковой.
Эти результаты совместимы с представлением о том, что структура списка оказывает
влияние на этап поиска в процессе припоминания, но не влияет на этап принятия
решения ни в случае припоминания, ни в случае узнавания. Другие авторы также
нашли, что различия в степени организации списка влияют на припоминание, не
затрагивая узнавания (см., например, Bruce a. Pagan, 1970).
Хотя модель двух процессов в том виде, в каком мы ее до сих пор описывали,
по-видимому, позволяет объяснить многие важные явления, связанные с воспроизведением
и узнаванием, Андерсон и Боуэр (Anderson a. Bower, 1972) указывают на необходимость
внести в нее одну модификацию. По их мнению, понятие "прочности", используемое
в модели узнавания, основанной на обнаружении сигнала (и тем самым на этапе
принятия решения в модели двух процессов), несостоятельно. Эти авторы указывают,
что простая теория прочности не позволяет объяснить так называемую "дифференциацию
списков". Имеется в виду способность испытуемых различать элементы в зависимости
от того, в каком из иескольких списков они содержались. Эта способность весьма
значительна: испытуемые могут, например, ответить, входил ли данный элемент
в первый и четвертый списки или же он был предъявлен в составе второго и третьего
списков (Anderson a. Bower, 1972). Приведем другой пример. Если список 1 предъявлялся
десять раз, а список 2 — только однажды, то следовало бы ожидать, что при проверке,
проводимой после предъявления списка 2, элементы, входящие в список 1, должны
обладать большей прочностью, чем элементы списка 2. А поэтому если элементы
списка 1 использовать в качестве дистракторов в тесте на узнавание по списку
2, то они должны ошибочно признаваться за элементы этого списка. Между тем в
действительности эффективность различения между элементами списка 1 и элементами
списка 2 в этом случае даже выше, чем в тестах на узнавание, проводимых обычным
методом (Winograd, 1968). Короче говоря, простая теория прочности не позволяет
понять, каким образом испытуемый может установить, что данный элемент входил
в состав какого-то другого списка, если прочность этого элемента столь же высока
или даже выше прочности элементов списка, по которому сейчас идет проверка.
Таким образом, дифференциация списков создает затруднение для теории прочности.
Андерсон и Боуэр (Anderson a. Bower, 1972) высказали мнение, что в дифференциации
списков и узнавании участвуют по существу одни и те же процессы: когда испытуемый
узнает данный элемент в качестве одного из компонентов определенного списка,
это, в сущности, ничем не отличается от того, когда он узнает его как элемент,
входивший в единственный предъявленный ему список. Так как просто "прочность",
согласно этим рассуждениям, не может служить основой для дифференциации списков,
ее нельзя использовать при построении моделей узнавания и воспроизведения. В
качестве альтернативы эти авторы, выдвигают, то, что можно было бы назвать "контекстной
прочностью". Чтобы понять смысл этого термина, нужно начать с того, что предъявление
испытуемому любого списка слов всегда происходит в определенном "контексте",
который складывается из таких разнообразных факторов, как температура, время
суток, состояние желудка испытуемого, цвет волос экспериментатора и т. д. Все
эта факторы в совокупности и создают контекст. Предполагается, что, когда испытуемый
заучивает список, эти контекстуальные факторы ассоциируются с меткой для "данного
списка" в ДП. А эта метка в свою очередь ассоциируется со словами, входящими
в список (точно таким же образом, как в обсуждавшейся ранее модели для свободного
припоминания).
Посмотрим теперь, что происходит, согласно Андерсону и Боуэру, во время проверки.
Испытуемый начинает искать в памяти слова и находит их (или, в случае теста
на узнавание, его прямо подводят к ним предъявляемые элементы), после чего он
должен решить в отношении каждого найденного слова, входило ли оно в список,
по которому производится проверка. Он делает это, оценивая слово не по прочности
или возбуждению его собственного следа, взятого отдельно, а по степени ассоциации
между этим словом и факторами контекста заданного списка. Например, когда испытуемого
просят припомнить слова из списка 2, он извлекает из памяти некоторые слова;
затем он подвергает каждое из них проверке, с тем чтобы выяснить, достаточно
ли оно ассоциируется с факторами контекста списка 2. Если ассоциация достаточна,
он воспроизводит слово, если же нет — отбрасывает его. Нетрудно видеть, как
эта теория предсказывает способность дифференцировать списки: каждый список
имеет свой, отличный от другого контекст, даже если различия невелики. Можно
даже ожидать, что испытуемые будут в состоянии описать тот контекст, в котором
им было предъявлено данное слово, и нередко они действительно могут это сделать.
Такая теория применима и к узнаванию в более простей задаче — к "дифференциации"
списка при наличии всего лишь одного списка.
Для подтверждения своей модели двух процессов Андерсон и Боуэр провели эксперименты,
в которых они варьировали контекст списка, что оказывало различное влияние на
узнавание и воспроизведение. Испытуемые заучивали ряд списков; каждый список
содержал по 16 слов, взятых из некоторого ограниченного "фонда", содержавшего
32 слова, так что эти списки значительно перекрывались. Водном из экспериментов
после предъявления каждого списка испытуемый должен был сначала попытаться вспомнить
как можно больше слов из основного фонда, т. е. он припоминал все предъявлявшиеся
ему ранее слова, к какому бы списку они ни относились. Затем испытуемого просили
указать, какие из этих слов относятся к списку, предъявленному последним. Конечно,
при проверке, производившейся после самого первого списка, все слова, которые
он мог вспомнить, относились именно к этому списку. Однако по мере того, как
число предъявлявшихся списков возрастало, положение изменялось: испытуемый воспроизводил
все больше и больше слов основного фонда. Это не удивительно, поскольку следует
ожидать, что способность к извлечению из памяти всего набора слов (основного
фонда) будет повышаться, по мере того как входящие в него слова будут заучиваться
все чаще и чаще. Однако способность испытуемого узнавать, какие слова входили
в список, предъявленный последним, снижалась с увеличением числа списков. По
мнению авторов, это объясняется тем, что в результате предъявления все большего
числа перекрывающихся списков одни и те же слова оказываются связанными со все
большим числом различных контекстов. В результате все труднее и труднее становится
использовать факторы контекста, чтобы отдифференцировать слова, входившие в
последний список, от остальных, и эффективность "узнавания" этих слов снижается.
Кроме того, этот эксперимент позволил отделить снижение эффективности узнавания
от улуч шения результатов припоминания, что свидетельствует в пользу модели
двух процессов.
Подведем теперь краткие итоги. У нас имеется гипотеза двух процессов, позволяющая
объяснить извлечение информации. Согласно этой гипотезе, припоминание происходит
следующим образом. Соответствующий "ключ" для извлечения информации позволяет
"войти" в долговременную память в надлежащей точке. Из этой точки начинается
поиск, который ведется по заученным прежде ассоциативным путям от одного элемента
к другому. Всякий раз, когда этот поиск приводит к какому-то элементу, вступает
в действие процесс узнавания. Содержится ли этот элемент в наборе, подлежащем
припоминанию? Если да, то он воспроизводится; если нет, поиск продолжается.
Из этой теории извлечения следует общее правило, согласно которому любой фактор,
облегчающий ассоциации между "ключом" и запоминаемыми элементами или между самими
этими элементами (например, удобная для классификации структура или опосредование),
облегчает первоначальную организацию материала и поиск нужных элементов, а тем
самым и их припоминание.
Тульвинг и Томсон (Tulving a. Thomson, 1973) сообщил о результатах, которые
требуют дальнейшего видоизменения нашей модели извлечения информации. Как указывают
эти авторы, согласно модели двух процессов, узнавание никогда не должно быть
хуже припоминания, так как припоминание слагается из узнавания и еще одного
процесса (поиска). Поскольку припоминание зависит от узнавания, оно никогда
не может быть более эффективным, чем узнавание; оно может происходить либо с
такой же, либо с меньшей эффективностью. А между тем Тульвинг и Томсон при помощи
довольно остроумного метода показали, что припоминание может быть более эффективным,
чем узнавание. Испытуемые заучивали списки из 24 элементов. Каждый элемент предъявлялся
одновременно с другим, который был с ним слабо ассоциирован; например, элемент
ХОЛОД предъявлялся в форме "земля, ХОЛОД". После предъявления списка проводили
тест на воспроизведение, в котором элементы, ассоциированные с элементами списка,
играли роль "ключей"; таким образом, испытуемые узнавали, что эти ассоциированные
слова полезны, когда приходит время вспоминать основные слова. Однако после
двух таких списков Тульвинг и Томсон неожиданно изменяли порядок проверки. Они
не предлагали испытуемым обычный тест на воспроизведение с "ключевыми" элементами,
а проводили ряд других проверок. В частности, он предъявляли испытуемым слова,
сильно ассоциированные сэлементами списка, и просили их использовать эти слова
как стимулы для свободных ассоциаций.
Рассмотрим в качестве примера случай, когда вначале испытуемому было предъявлено
слово ХОЛОД как элемент списка со слабо ассоциированным словом "земля". Теперь
же ему предлагают слово ЖАР (сильно ассоциированное со словом ХОЛОД) и просят
создавать с ним свободные ассоциации. В предъявленном ранее списке слова ЖАР
не было, такие слова называют "внесписочными ключами". В этих условиях испытуемые
часто воспроизводят слова, входившие в список, в качестве компонентов, ассоциированных
с внесписочными словами. Например, весьма вероятно, что испытуемый воспроизведет
слово "холод", ассоциируя его со словом ЖАР. После окончания теста на свободные
ассоциации испытуемых просили указать, какие из названных ими в этом тесте слов
входили в первоначальный список. Если в нашем примере испытуемый при предъявлении
слова-стимула ЖАР отвечал "холод, тепло, солнце, огонь", то он должен был бы
указать, что слово "холод" входило в список. Короче говоря, он должен был узнать
слово "холод". Здесь-то и были получены неожиданные результаты: оказалось, что
испытуемые выполняли эту задачу очень плохо. В одном из таких экспериментов
испытуемые воспроизвели в тесте на свободные ассоциации 18 слов из 24, входивших
в описок, однако узнали всего только 4 из них. В другой же задаче они сумели
припомнить 15 из этих 24 слов, когда им предоставили в качестве ключей слабо
ассоциированные компоненты из первоначального списка. Таким образом, их способность
припоминать (при наличии соответствующих ключей) оказалась выше способности
к узнаванию.
Приведенный Тульвингом и Томсоном пример, в котором припоминание превосходит
узнавание, служит еще одной иллюстрацией специфичности кодирования (см. гл.
10). По-видимому, их испытуемые кодировали слова списка в контексте предъявлявшихся
вместе с ними слабых ассоциаций. Поэтому они не могли использовать ключи другого
типа — сильные ассоциации. Это противоречит тому, чего можно было бы ожидать
исходя из гипотезы двух процессов; казалось бы, любые ключи, а особенно сильные
ассоциации, должны облегчать припоминание, помогая в процессе поиска. Видимо,
та ситуация, в которой происходит кодирование элементов и проводится их проверка,
может оказывать сильное влияние на соотношение между узнаванием и воспроизведением
этих элементов. При кодировании может учитываться весьма специфичная информация
об условиях первоначального хранения, в результате чего извлечение оказывается
практически невозможным, если при этом не воспроизводится весь контекст, в котором
осуществлялось кодирование.
ПРОЦЕССЫ ПОИСКА ПРИ УЗНАВАНИИ
В более позднем варианте своей модели двух процессов Андерсон и Боуэр (Anderson
a. Bower, 1974) подчеркивают важность контекста кодирования, описывая его роль
в припоминании в рамках своей модели АПЧ (рассмотренной в гл. 8). Структура
АПЧ, основной единицей которой служит высказывание, позволяет в развернутой
форме представить то, что при рассмотрении предыдущего варианта модели Андерсона
и Боуэра мы назвали "признаками контекста". Признак контекста можно определить
как высказывание, описывающее те специфические условия, в которых предъявлялся
данный список. Андерсон и Боуэр внесли в модель еще одно изменение: они постулировали,
что узнавани, подобно припоминанию, содержит компонент поиска; процесс поиска
при узнавании направлен на то, чтобы открыть доступ к ячейке памяти, соответствующей
элементу, который предъявляется для узнавания. Это предположение очень существенно,
так как оно помогает учитывать влияние специфичности кодирования. В традиционных
экспериментах при проверке на узнавание какого-либо слова ячейку памяти, соответствующую
этому слову, обычно удается найти сразу. Однако, как показывают результаты экспериментов
со специфическими условиями кодирования, эта операция может быть сильно затруднена,
и при проверке на узнавание данного слова доступ к ячейке, в которой хранится
его значение, отнюдь не гарантирован.
Есть и другие данные, указывающие на то, что узнавание не сводится к одному
лишь принятию решения, а содержит также компонент поиска. Подобного мнения придерживаются
Мандлер и его сотрудники (Mandler, 1972; Mandler а. о., 1969). Существенным
подтверждением этого служат результаты некоторых экспериментов, говорящие о
том, что на узнавание влияет степень организации списка. Важно отметить, что
эти данные прямо противоречат результатам рассмотренных ранее экспериментов,
показавших, что организация списка влияет на припоминание, но не на узнавание
(см., например, Kintsch, 1968). Тем не менее, как свидетельствуют довольно многочисленные
данные, особенно в экспериментах с сильно структурированными списками (Bower
а. о., 1969; D'Agostino, 1969; Lachman а. Tuttle, 1965), организация списка
может сказываться и на узнавании. А поскольку принято считать, что организация
списка влияет не на этап принятия решения, а на процессы поиска, то, следовательно,
узнавание содержит некоторые элементы поиска.
Мандлер и сотр. (Mandler а. о., 1969) указали на один из возможных путей влияния
структуры списка на узнавание. Они полагают, что в тесте на узнавание испытуемые
уверенно относят некоторые элементы к "старым" или к "новым", в то время как
остается еще известное число старых и новых элементов, которые они не могут
без колебаний отнести к той или к другой группе. Эти элементы должны быть подвергнуты
"проверке путем извлечения". При этой проверке ставится вопрос, можно ли вспомнить
данный элемент, т. е. можно ли было бы отыскать его в результате процесса поиска,
если бы задача заключалась в припоминании. При утвердительном ответе на этот
вопрос элемент будет назван старым, в противном же случае — новым. Именно эта
проверка путем извлечения, подверженная влиянию организации точно так же, как
процессы поиска при вспоминании, обусловливает то, что организация влияет и
на узнавание.
Сходную модель предложили Аткинсон и Джуола (Atkinson a. Juola, 1973). Они
считают, что если после предъявления списка производится проверка на узнавание,
испытуемые сразу относят некоторые из предлагаемых элементов либо к элементам
списка, либо к дистракторам; однако в отношении других элементов испытуемому
приходится предпринимать обширные поиски в ДП, прежде чем он сможет дать ответ.
Согласно такой модели, этот поиск в ДП аналогичен тому, который предполагается
в экспериментах Стернберга по сканированию КП (см. гл. 7).
В связи с этими данными об участии в узнавании процессов поиска возникла необходимость
внести в гипотезу двух процессов ряд существенных изменений. Андерсон и Боуэр
(Anderson a. Bower, 1974) описали соотношение между узнаванием и припоминанием
с помощью модели, которую можно назвать "гипотезой четырех процессов". Они различают
в процессе извлечения информации четыре подпрoцecca: 1) обследования ассоциотивных
путей в поисках ячеек, соответствующих нужным элементам; 2) изучение контекстной
информации с целью выяснить, действительно ли найденный элемент подлежит припоминанию;
3) воспроизведение слова после извлечения его смысла (нахождения соответствующей
ему ячейки в ДП); 4) нахождение смысла (ячейки в ДП) при предъявлении слова.
Первые три из этих процессов — компоненты припоминания, тогда как второй и четвертый,
по-видимому, участвуют в узнавании. Таким образом, в узнавании и припоминании
имеются общие компоненты, как это постулирует гипотеза двух процессов. Однако
вариант с четырьмя процессами подразумевает более сложные взаимоотношения между
узнаванием и припоминанием, чем это предполагалось ранее.
В двух последних главах мы сделали полный круг. Сначала мы сосредоточили внимание
на процессе кодирования, что заставило нас заняться проблемой извлечения информации
во всей ее сложности. А это в свою очередь вновь привело нас к представлению
о важном значении кодирования. В целом же это обсуждение функций памяти укрепило
наше впечатление о том, что система переработки информации у человека — поразительно
эффективная и гибкая система.
Глава 12
Зрительные представления в долговременной памяти
Роль содержащейся в ДП зрительной информации, составляющая главную тему этой
главы, в какой-то мере уже обсуждалась в предшествующих главах. Рассматривая
распознавание образов, мы увидели, что для понимания того как люди относят сложные
зрительные стимулы к определенным значимым категориям, нам придется допустить,
что в ДП содержится информация о зрительных особенностях различных стимулов.
Мы ознакомились с возможными формами представления этой информации — такими,
как перечни признаков, прототипы или правила для создания внутренней копии.
Обсуждая зрительные представления в кратковременной памяти, мы постулировали
возможность существования в КП хорошо известных зрительных образов (вроде, например,
букв алфавита), воссоздаваемых на основе информации, хранящейся в долговременной
памяти. Мы установили, что такие внутренние зрительные образы можно поворачивать
и использовать для сравнения с другими стимулами. Рассматривая опосредование,
мы выяснили, что у испытуемых, получивших инструкцию использовать при заучивании
пар слов "мысленные картины", эффективность припоминания была выше, чем у испытуемых,
не получивших таких специальных инструкций. А при обсуждении работ Шепарда (Shepard,
1967) по узнаванию мы убедились, что испытуемые способны узнавать большое число
картинок, которые они видели лишь один раз.
В
этой главе основное внимание будет уделено зрительной памяти. В частности,
нам придется уточнить смысл понятия "зрительный образ". Что такое
образ? Как он может быть использован? Действительно ли в ДП хранятся
какие-то картины? Если да, то какой они имеют вид? Все эти вопросы будут
возникать в процессе изложения, но из-за нехватки места мы вряд ли
сможем уделить такому сложному предмету, как образная память, то внимание,
которого он заслуживает.
Хранятся ли в памяти образы? Исходя из чисто субъективных представлений, на
этот вопрос можно ответить утвердительно. Рассмотрим, например, как человек
отвечает на вопрос о том, сколько окон в кухне его квартиры (или какой-нибудь
другой хорошо известной ему квартиры). Как указывает Шепард (Shepard, 1966),
отвечая на такой вопрос, человек, очевидно, воссоздает мысленную картину или
образ кухни, о которой идет речь, а затем обводит ее мысленным взглядом, пересчитывая
имеющиеся в ней окна. В качестве другого примера (описанного в гл. 7) рассмотрим,
что происходит при сравнении букв  и R. Задайте себе вопрос:
одинаковы ли эти две буквы (с тем лишь различием, что одна из них повернута)
или же первая представляет собой зеркальное отображение второй? Отвечая на этот
вопрос, вы можете почувствовать, что вы мысленно поворачиваете наклоненную фигуру
так, чтобы она встала прямо. Поскольку сама фигура остается при этом неподвижной,
очевидно, что должен перемещаться некий мысленный образ. Однако подобные убедительные
демонстрации субъективного впечатления, говорящего как будто о создании
мысленного образа, не обязательно должны означать, что в мозгу хранятся какие-то
картины; а может быть, они и в самом деле свидетельствуют об этом? и R. Задайте себе вопрос:
одинаковы ли эти две буквы (с тем лишь различием, что одна из них повернута)
или же первая представляет собой зеркальное отображение второй? Отвечая на этот
вопрос, вы можете почувствовать, что вы мысленно поворачиваете наклоненную фигуру
так, чтобы она встала прямо. Поскольку сама фигура остается при этом неподвижной,
очевидно, что должен перемещаться некий мысленный образ. Однако подобные убедительные
демонстрации субъективного впечатления, говорящего как будто о создании
мысленного образа, не обязательно должны означать, что в мозгу хранятся какие-то
картины; а может быть, они и в самом деле свидетельствуют об этом?
ПАМЯТЬ НА ОБРАЗНУЮ ИНФОРМАЦИЮ
Содержатся ли в нашей памяти зрительные образы? Хотя этот вопрос еще остается
спорным, нет никаких сомнений в том, что в памяти хранится информация о событиях,
воспринимаемых при помощи зрения. Возьмем хотя бы нашу способность узнавать
лица в самых разных ракурсах и при разных условиях, даже на карикатурах. А наша
способность запоминать сцены? Эти способности человека были исследованы экспериментально;
в частности, Шепард (Shepard, 1967) показал, что люди могут запоминать изображения
обычных предметов. Такого рода эксперименты получили дальнейшее развитие. Стэндинг
и его сотрудники (Standing а. о., 1970) предъявляли испытуемым 2560 слайдов,
в течение 10 с каждый. При последующей проверке на узнавание, проводившейся
с частью этих слайдов, испытуемые в 90% случаев давали верные ответы. Ввиду
такой высокой эффективности узнавания можно думать, что в памяти испытуемых
содержались не словесные описания этих слайдов, а что-то другое — возможно,
какая-то "изобразительная" информация. Ведь сколько понадобилось бы слов для
описания 2560 картинок! (Если считать, что на каждую картинку надо затратить
по тысяче слов, то всего потребовалось бы 2560000 слов!)
Другие данные в пользу существования образной памяти приводят Шепард и Чипмен
(Shepard a. Chipman, 1970). Они давали испытуемым стопку из 105 карточек. На
каждой карточке были написаны названия двух штатов США, взятых из группы в 15
штатов (105 карточек исчерпывают все возможные сочетания из 15 по 2). Испытуемых
просили расположить эти 105. карточек в зависимости от сходства очертаний представленных
на них штатов. На первое место следовало поставить те два штата, которые наиболее
сходны по форме, затем два наиболее сходных из оставшихся и так далее. Таким
образом, наименьшим порядковым номерам соответствовало наибольшее сходство по
форме. Порядковые номера можно также представлять себе как меру расстояния;
тогда наименьший номер (и, следовательно, максимальное сходстро) соответствует
минимальному "расстоянию" между двумя штатами в отношении формы.
Получив такие оценки меры сходства для 105 пар штатов, Шепард и Чипмен обработали
эти данные по программе многомерного шкалирования. Как уже указывалось в гл.
8, многомерное шкалирование использует меры близости между парами элементов
и описывает распределение этих элементов в многомерном пространстве, причем
расстояния между ними в этом пространстве находятся в обратной зависимости от
их сходства. Более того, по размерности образующегося пространства можно судить
о том, на чем основывают испытуемые свои оценки сходства. На рис. 12.1 представлены
двумерные пространства, построенные программой на основании оценок сходства,
которые получили Шепард и Чипмен в своем эксперименте с 15 штатами. Как видно
из этого рисунка, штаты делятся на 4 группы: 1) небольшие, неправильной формы
с волнистыми границами (в нижней части рисунка); 2) прямоугольные и с прямыми
границами (вверху); 3) вытянутые в вертикальном направлении, неправильной формы
(слева); 4) штаты, контуры которых образуют как бы рукоятку (справа). Таким
образом, многомерное решение отражает визуальные особенности этих штатов, хотя
испытуемые при оценке сходства видели перед собой только их названия.
Как показано на рис. 12.1, примерно такие же результаты были получены
и тогда, когда испытуемым давали не названия штатов, а их контуры. Эти данные говорят о
том, что в ДП испытуемых содержалась информация о форме штатов и
поэтому, получив названия штатов, они могли использовать эту информацию для
оценки их сходства по форме.
Шепард (Shepard, 1968; Shepard a. Chipman, 1970) высказал предположение, что
содержащаяся в памяти зрительная информация находится в отношении "изоморфизма
второго порядка" к соответствующей информации реального мира. Изоморфизм — математический
термин, служащий для обозначения взаимоотношений двух объектов, которые в основе
своей идентичны. Изоморфизм второго порядка — в понимании Шепарда — подразумевает
нечто более близкое к сходству. Шепард считает, что две совокупности элементов
находятся в отношении изоморфизма второго порядка, если взаимоотношения между
элементами в одной совокупности соответствуют их взаимоотношениям в другой.
Таким образом, некоторые элементы реального мира будут находиться в отношении
изоморфизма второго порядка к соответствующим элементам в памяти, если взаимоотношения
между нимив памяти таковы же, что и в реальном мире. По-видимому, так обстоит
дело с названиями штатов. Реальное соотношение между Оклахомой и Айдахо (у обоих
имеются "рукоятки") соответствующим образом отразилось в их соотношении в памяти
испытуемых Шепарда и Чипмена (во всяком случае, в той мере, в какой об этом
можно судить по полученным оценкам сходства). Шепард полагает, что содержащаяся
в памяти зрительная информация в общем находится в отношении изоморфизма второго
порядка к соответствующим реальным данным. Иными словами, "мысленные образы"
сходны с их реальными образами в том смысле, что взаимоотношения между мысленными
образами таковы же, что и между теми картинами, которые воспринимает зрение.
Идея о существовании в ДП образного кодирования получила дальнейшее подтверждение
в результате исследований Фрост (Frost, 1972). Фрост составила набор из 16 рисунков,
изображавших обычные объекты (некоторые из них приведены на рис. 12.2). Эти
рисунки можно было систематизировать на смысловой основе, так как на них были
представлены объекты четырех категорий, или классов: животные, одежда, транспортные
средства и мебель. Однако эти жерисунки можно было расклассифицировать и на
визуальной основе, так как они находились в одном из четырех положений: их длинная
ось могла располагаться вертикально, горизонтально, с наклоном вправо или с
наклоном влево. Эти 16 рисунков предъявили двум группам испытуемых, из которых
одна должна была ожидать проверки методом узнавания, а другая — методом свободного
припоминания названий предъявленных объектов. Затем с обеими группами провели
проверку методом свободного припоминания. Результаты показали, что те испытуемые,
которые ожидали теста на свободное припоминание, группировали элементы на семантической
основе, т. е. элементы, принадлежащие к одному и ТОМУ же семантическому классу,
припоминались вместе. В отличие от этого испытуемые, ожидавшие проверки на узнавание,
группировали элементы на основе как семантических, так и визуальных признаков.
Эти результаты позволяли предполагать, что в ДП испытуемых, ожидавших проверки
на узнавание, хранились зрительные представления этих элементов; во время припоминания
они использовали как эти, так и семантические представлениия. Так же как и при
воспроизведении списков, поддающихся разбивке на классы, воспроизведение элементов
испытуемыми отражало организацию исходного набора. Для тех испытуемых, которые
ожидали проверки на узнавание и кодировали рисунки на основе визуальных признаков,
организация состояла в создании классов, основанных именно на этих признаках.
В отличие от этого испытуемые, ожидавшие теста на свободное припоминание, организовали
материал только по семантическим классам и поэтому не создавали группировок,
основанных на визуальных признаках. Другие данные, полученные Фрост, также подтверждают
эту гипотезу. В частности, оказалось, что испытуемые, ожидавшие проверки на
узнавание, лучше узнают рисунки при зрительном предъявлении, а те, кто ожидал
проверки на припоминание, лучше узнают названия изображенных элементов.
Вывод из всех предшествующих рассуждений, очевидно, состоит в том, что человек
способен хранить в ДП информацию о визуальных признаках всего того, с чем ему
приходилось сталкиваться: признаки лиц, которые он видел, карт, которые изучал,
сцен, свидетелем которых был, и т. п. Кроме того, судя по имеющимся данным,
хранящаяся в ДП зрительная информация до некоторой степени сходна с изображением
виденного. Такие "изобразительные" коды следует противопоставлять вербальным
описаниям тех же самых восприятий. Короче говоря, термин "зрительные образы"
может, в частности, означать представление в памяти специфических сведений,
получаемых с помощью зрения.
МЫСЛЕННЫЕ ОБРАЗЫ И ПАМЯТЬ
Развитие
представлений о зрительных образах связано, однако, и с другой проблемой.
Суть ее состоит в том, что образы как способ представления информации
могут служить альтернативой вербальным кодам. Например, человек может
представить себе собаку, едущую на велосипеде, для того чтобы запомнить
парную ассоциацию СОБАКА—ВЕЛОСИПЕД. Такая картина будет выполнять примерно
ту же функцию, что и слова "собака, едущая на велосипеде". Следовательно, образ может служить средством представления информации,
которую легко можно было бы описать при помощи слов. Образные
представления могут быть так же или даже еще более полезны, чем вербальные
представления в ДП, если использовать их в задачах, связанных с обучением
и памятью.
Пайвио (Paivio, 1969, 1971) — один из главных сторонников только что изложенной
точки зрения — выдвинул теорию двух систем, или двух форм, кодирования; эта
теория довольно сильно отличается от той теории памяти, которой мы до сих пор
придерживались в этой книге. Согласно теории двух систем, существует два основных
способа представления информации в памяти, которые можно назвать двумя системами
кодирования. Один из них — это словесное, или вербальное (лингвистическое),
представление, которое мы здесь главным образом и обсуждали, особенно в двух
последних главах. Второй способ — невербальный; его можно было бы назвать изобразительным,
и к нему относятся, в частности, зрительные образы (но не только они). Эти две
системы, несомненно, тесно связаны между собой, что дает возможность извлечь
образ из словесной метки или наоборот. Однако между ними есть и некоторые серьезные
различия.
Во-первых, образная система лучше справляется с конкретными объектами,
которые можно изобразить, каковы, например, "собака" или "велосипед". Но как
можно было бы нарисовать какое-нибудь абстрактное понятие, например "истина"?
А это означает, что некоторые вещи легче кодировать при помощи слов, тогда как
другие можно представить и в вербальной, и в невербальной форме. К последней
категории относятся такие конкретные понятия, как, скажем, "корзина" или "дом",
а к первой — абстрактные, такие, как "справедливость" или "мышление". Во-вторых,
эти две системы различаются по способу переработки информации. В вербальной
системе главную роль играет, по-видимому, последовательная переработка. При
восприятии, например, слов. кз которых слагается устная речь, звуки поступают
на вход один за другим, и смысл их в значительной мере зависит от их последовательности.
Этому можно противопоставить переработку зрительной информации, которая, видимо,
перерабатывается "пространственно-параллельным" способом, т. е. вся сразу в
некоторой области пространства. Например, увидев букву А, мы можем переработать
ее как целое, не разделяя на элементы / \ —.
Одно
из следствий представления о двух системах кодирования состоит в том, что
информация, которая может храниться как в вербальной, так и в образной
форме, должна быть более доступна, нежели информация, хранящаяся толь.ко в одной форме, ибо в первом случае мы можем добраться до нее с
помощью как вербального, так и невербального продесса извлечения. В
известном смысле количество информации об элементе, закодированном дважды,
вдвое больше, чем об элементе, закодированном только в одной форме. Поэтому
названия конкретных вещей должны запоминаться легче, чем слова,
обозначающие абстрактные понятия: первые могут быть представлены и в
образной, и в вербальной форме, а вторые-только в вербальной. Как мы увидим,
это предсказание действительно оправдывается.
Психологические данные, которые могут быть интерпретированы в рамках теории
двух систем, весьма многочисленны. Мы ограничимся здесь рассмотрением некоторых
типичных результатов, свидетельствующих в пользу этой теории. Сюда относятся,
в частности, данные о влиянии "образной представимости" слов на их запоминание;
о влиянии характера стимула (слово это или картина) на результаты различных
экспериментальных процедур; об эффекте использования мысленных образов при опосредовании
(о котором мы уже говорили в гл. 10).
Как мы только что отметили, один из вопросов, при анализе которых может быть
полезной гипотеза о двух формах кодирования, — это вопрос о влиянии "образной
представимости" слов. Мы уже упоминали об одной характеристике слова — о его
"осмысленности" (Noble, 1961). В качестве меры осмысленности данного слова используют
число ассоциаций, которые возникают при его предъявлении в тестах на свободное
ассоциирование за определенный промежуток времени. Таким образом, осмысленность
данного слова отражает степень его взаимосвязанности с другими словами. Попробуем
теперь определить меру того, насколько легко данное слово может вызвать какой-либо
образ. Пайвио (Paivio, 1965) просил испытуемых сообщать о моменте, когда у них
возникал образ, соответствующий предъявленному слову; этот образ мог быть зрительным
(мысленная картина) или даже слуховым. Быстрота, с которой испытуемые сообщали
о возникновении у них образов, использовалась для выведения меры образной представимости
(ОП) этого слова. Чем выше ОП, тем легче данное слово вызывает образ. Вообще
мы могли бы также отметить, что ОП в большой степени зависит от конкретности
значения слова: чем больше данное слово связывается с каким-то конкретным содержанием,
тем выше его ОП. Это, конечно, вполне естественно, поскольку можно ожидать,
что такие слова, как СОБАКА, которые относятся к конкретным объектам, будут
вызывать образы этих объектов, а для такого слова, как МЫШЛЕНИЕ, нет соответствующего
объекта, который было бы легко себе представить, поэтому оно и не может легко
порождать образ.
Величина образной представимости слов, как выяснилось, позволяет довольно точно
предсказывать эффективность памяти при выполнении разнообразных заданий. В этом
отношении она даже более существенна, чем степень осмысленности того же самого
слова. Одна из ситуаций, в которых ОП коррелирует с эффективностью, — это тесты
на узнавание. При предъявлении списков и последующей проверке методом узнавания
конкретные существительные (высокая ОП) узнаются лучше, чем абстрактные (низкая
ОП). Если же испытуемым предъявляют картинки, то эффективность узнавания оказывается
еще выше, чем в случае конкретных существительных; этого и следовало ожидать,
если вы помните приводившиеся выше отличные результаты в опытах с узнаванием
картинок (обзор см. Paivio, 1971). Сходные данные получены для свободного припоминания:
эффективность воспро.изведения списков абстрактных слов ниже, чем списков конкретных
слов. А если списки снабжены картинками (и испытуемых просят вспоминать надписи,
сопровождавшие эти картинки), то результаты получаются еще лучше, чем при запоминании
конкретных слов. Такие различия имеют место и при 5-минутных интервалах удержания,
и при более длительных интервалах, порядка недели. Подобная же градация эффективности
для картинок, конкретных слав и абстрактных слов наблюдается при запоминании
и воспроизведении последовательностей элементов (Herman а. о" 1951; Paivio а.
Csapo, 1969). Следует также отметить, что эти эффекты зависят,
по-видимому, только от образной представимости и не связаны с осмысленностью
слов, используемых в списках (см., например, Paivio а. о" 1969).
Общий вывод, который можно сделать из этих данных, состоит в том, что образная
представимость (ОП) и конкретность действительно влияют на удержание в памяти
вербальной информации. Это было истолковано как довод в ПОЛЬЗУ теории двух форм
кодирования. При этом исходили из следующих соображений. Слова, обладающие высокой
ОП, представлены в двух разных системах долговременной памяти — в системе с
вербальным кодом и в системе с каким-то образным, "изобразительным" кодом. Для
слов с низкой ОП существует только один код — вербальный. Если же предъявляются
картинки, то в памяти наряду со словесным описанием или меткой остается очень
прочный образный след. Когда приходит время проверки запоминания этих элементов-либо
методом узнавания, либо методом припоминания, — то результаты зависят от количества
сохранившейся в памяти информации. При наличии двух кодов результаты будут лучше,
чем при наличии всего лишь одного кода. В некотором смысле можно считать, что
прочность элемента в памяти представляет собой сумму его вербальной и образной
прочности.
РОЛЬ ОБРАЗОВ В ОПОСРЕДОВАНИИ
Данные в пользу гипотезы о двух формах кодирования получены также при изучении
роли образов в опосредовании. Основные результаты описаны в уже обсуждавшейся
работе Боуэра (Bower, 1972b). Этот автор установил, что, когда испытуемым в
задаче на парные ассоциации предлагали создавать подходящие мысленные образы,
эффективность припоминания необычайно возрастала. Например, при предъявлении
пары слов СОБАКА—ВЕЛОСИПЕД испытуемый мог представить себе собаку, едущую на
велосипеде. У других испытуемых, получавших обычные инструкции без какого-либо
упоминания о мысленных образах, эффективность припоминания была примерно на
/з ниже. Очевидно, образы служили хорошими опосредующими факторами. Предполагается,
что во время припоминания испытуемый использует компонент-стимул СОБАКА для
извлечения из памяти картины, созданной им ранее (собака на велосипеде). Из
этой картины он извлекает образ велосипеда, а затем воспроизводит слово "велосипед".
Боуэр исследовал роль образов в опосредовании парных ассоциаций еще более подробно.
Он установил, например, что с одним компонентом-стимулом могут ассоциироваться
несколько компонентов-реакций совершенно так же, как с ним ассоциируется одна
реакция. Так, испытуемому можно предложить для запоминания пять слов: СОБАКА,
ШЛЯПА, ВЕЛОСИПЕД, ПОЛИЦЕЙСКИЙ, ЗАБОР, ассоциируя их со словом-стимулом СИГАРА.
Испытуемый мог бы при этом создать в своем воображении картину полицейского
с сигарой в зубах, который останавливает у забора собаку (разумеется, в шляпе),
едущую на велосипеде. Может ли он извлечь из этой картины пять перечисленных
слов при предъявлении одного лишь слова СИГАРА? Как показывают результаты эксперимента
— может. Боуэр нашел, что припоминание не зависит от числа элементов, которые
следовало ассоциировать в создаваемой картине с компонентом-стимулом. Припоминание
не ухудшалось, если испытуемые ассоциировали список из 20 слов с одним компонентом-стимулом
вместо двадцати, по одному на каждое слово описка. В данном случае компонент-стимул
называют "вешалкой" — на него можно как бы навесить разнообразные реакции.
Боуэр установил также, что
образность способствует припоминанию только в тех случаях, когда
компоненты-реакции объединяются со "словом-вешалкой" в какую-то
сложную картину. Если попросить испытуемого представить себе собаку, а
затем отдельно-велосипед, для того чтобы запомнить пару
"собака-велосипед", то результаты будут гораздо хуже, чем если
попросить его представить себе картину, в которой собака и велосипед
каким-то образом взаимодействуют. Это и понятно, так как образ одного лишь
велосипеда мало поможет при извлечении из памяти образа собаки самой
по себе. Для того чтобы с помощью слова СОБАКА добраться до слова
"велосипед", мы должны иметь в памяти какую-то картину, которая могла
бы всплыть при предъявлении одного слова, но содержала бы оба объекта; она
должна объединять в себе оба элемента, чтобы можно было извлечь один
из них с помощью другого.
Опосредование через образы может оказаться полезным не только при образовании
парных ассоциаций. Например, Делин (Delin, 1969) использовал его в задачах на
запоминание последовательностей. Он объяснял испытуемым, что для хорошего запоминания
нужно представить себе каждую пару соседних элементов ряда в том или ином взаимодействии.
Он давал на это много времени, предъявляя слова медленно (11 с каждое). При
предъявлении списка, в который входила, например, последовательность СОБАКА,
ВЕЛОСИПЕД, ШЛЯПА, испытуемый мог сначала представить себе собаку на велосипеде,
затем — в виде отдельной картины шляпу, висящую на руле велосипеда, и так далее.
Такая инструкция облегчала припоминание последовательности элементов и улучшала
результаты по сравнению с результатами испытуемых, получавших обычные инструкции.
ОБРАЗЫ И ЕСТЕСТВЕННЫЙ ЯЗЫК
Идея образного опосредования оказалась также весьма плодотворной при изучении
памяти на фрагменты естественной речи. Как мы уже имели случай убедиться (см.
гл. 9), забывание таких фрагментов нередко выражается в забывании слов, которыми
они были изложены, но не смысла. Например, в одном из исследований, проведенных
Сакс (Sachs, 1967), испытуемые реагировали на перевод предложения из активной
формы в пассивную гораздо слабее, чем на изменение его смысла — скажем, переход
от утвердительной формы к отрицательной. Бегг и Пайвио (Begg a. Paivio, i969)
пошли еще дальше. Они провели такие же эксперимейты, как и Сакс, используя предложения
абстрактного и конкретного характера. Примером конкретного предложения, в состав
которого входят конкретные существительные, служит фраза "Любящая мать заботилась
о детях", а примером абстрактного — "Абсолютная вера возбуждала стойкий интерес".
Подобного рода предложения предъявляли испытуемому, включая их в короткие отрывки
текста, после чего проводили проверку на узнавание. Каждый участвовавший в проверке
элемент-дистрактор походил на одно из исходных предложений, но отличался от
него либо только по словесной форме, либо по смыслу. Например, изменяя формулировку
приведенного выше конкретного предложения, можно было получить фразу "Любящая
мать ухаживала за детьми", а при смысловом изменении-"Любящие дети заботились
о матери".
Результаты эксперимента Бегга и Пайвио представлены на рис. 12.3. Как видно
из этого рисунка, данные, полученные Сакс, подтверждаются в отношении конкретных,
но не в отношении абстрактных предложений. В случае конкретных предложений испытуемые
легче замечают смысловые изменения, чем изменения формулировок, в случае же
абстрактных предложений наблюдается обратная картина. Эти результаты можно объяснить
исходя из представлений Пайвио о роли образов в хранении информации. Пайвио
считает, что смысл конкретного предложения представлен в памяти больше в виде
образов, чем слов. Поэтому изменения слов, не затрагивающие смысла, не будут
противоречить содержащемуся в памяти образу и останутся незамеченными. Если
же предложение абстрактное, то образ не дает возможности эффективно сохранять
в памяти смысл предложения; смысл должен здесь храниться в форме слов, и поэтому
изменения в формулировке будут замечены.
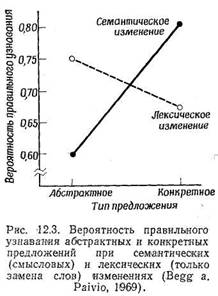
Судя по результатам этого последнего эксперимента и его интерпретации, идея
образного представления пригодна в качестве гипотезы, объясняющей понимание
языка. Такого мнения придерживается Пайвио (Paivio, 1971), который считает,
что образы играют важнейшую роль в понимании и запоминании информации, передаваемой
с помощью языка. Иначе говоря, он полагает, что мы понимаем словесные сообщения
благодаря тем образам, которые они способны вызывать, особенно если эти сообщения
конкретны. Конечно, существуют и другие теории понимания языка (речи) и его
смысла; подобных теорий так много, что рассмотреть их все в этой книге было
бы невозможно. Однако здесь следует указать, что теории семантической памяти
обсуждавшиеся в гл. 8, касаются сведений, передаваемых с помощью
языка; таким образом, они описывают понимание языка без использования
образов.
Может создаться впечатление, что мы уже располагаем вполне
убедительными данными в пользу существования в ДП представлений
"изобразительного" типа. Поэтому сейчас очень уместно будет
рассмотреть противоположные точки зрения. В сущности, споры о том, хранится
ли информация в ДП в образной форме, ведутся в психологии уже давно (обзор см. Paivio, 1971). Но в последние годы интерес к ним
возродился в
связи с появлением новых, более детализированных теорий, связывающих эту
проблему с современной когнитивной психологией.
ВОЗРАЖЕНИЯ ПРОТИВ ГИПОТЕЗЫ ОБРАЗОВ
Здравый смысл может заставить нас усомниться в правильности теории, которая
утверждает, что в долговременной памяти хранятся образы, особенно если предполагается,
что эти образы выглядят совершенно так же, как и объекты реального мира. Пылышин
(Pylyshyn, 1973) указал на ряд серьезных трудностей, с которыми сталкивается
эта теория. Прежде всего возникает вопрос о том, на что похожи эти мысленные
образы. Если они и в самом деле точно отображают воспринимаемую нами информацию,
то, очевидно, таких образов должно быть очень много. Поскольку мы можем воспринимать
с помощью зрения практически неограниченное число различных сцен, ДП должна
была бы располагать неограниченным пространством для хранения детальных копий
всех этих сцен. Неясно также, как можно использовать все эти хранящиеся в памяти
образы. Они должны каким-то путем извлекаться из памяти, а для этого необходимо
повторно воспринимать и анализировать их, чтобы "увидеть", что в них содержится.
Но если эти образы приходится снова воспринимать, то их можно было бы с тем
же успехом хранить в уже "обработанной" в процессе восприятия форме, а не просто
в виде точных копий виденных сцен. Еще один вопрос состоит в том, каким образом
слово могло бы открывать доступ к определенной картине: ведь одно и то же слово
может относиться к очень большому числу картин — как узнать, какую именно следует
извлечь из памяти? Пылышин, учитывая все эти моменты, считает, что образы-или
как бы мы их ни называли — должны храниться в памяти в виде продуктов некоего
анализа, а не в виде необработанных сенсорных данных. Но в таком случае они
не могут в точности копировать внешний мир, лежащий за пределами сенсорного
регистра, а должны быть больше похожи на описание воспринятого. Это не значит,
что у людей нет субъективных представлений "изобразительного" характера; это
лишь означает, что наличие таких представлений не говорит непременно о хранении
соответствующей информации в образной форме: такой вывод был бы ошибочным.
Андерсон и Боуэр (Anderson a. Bower, 1973) поддерживают точку зрения Пылышина.
По их мнению, те следы памяти, которые мы могли бы считать образными, не отличаются
от тех, которые мы считаем "чисто вербальными". В созданной ими модели АПЧ все
содержащиеся в долговременной памяти сведения могут быть представлены в виде
высказыванийабстрактных структур, составленных из связанных между собой понятий.
Такая модель дает возможность объяснить наличие в памяти и вербальных, и образных
кодов (в соответствии с принятыми нами терминами). То, из чего состоят высказывания
(узлы и ассоциации), — достаточно абстрактно и выходит за пределы таких понятий,
как "вербальный" или "образный". При помощи высказываний можно описывать сведения
как о словах, так и об образах.
Помимо логических возражений против существования
в памяти образов есть и экспериментальные данные в пользу единой теории
образных и вербальных процессов (т. е. в пользу того, что оба процесса в
основе своей сходны — что это не две четко разграниченные формы
представления информации). Хотя первоначальные данные Боуэра, касавшиеся
заучивания парных ассоциаций и использования образов, лучше
согласовались с гипотезой о двух формах кодирования, результаты его
последующих работ говорят в пользу единого механизма.
В одном из экспериментов (Bower a. Winzenz, 1970) было обнаружено, что, когда
испытуемым в задаче с парными ассоциациями предлагали использовать в качестве
посредников предложения, это оказывалось столь же эффективным, как и использование
образов. Такие предложения должны связывать между собой элементы пары (как в
неоднократно приводившемся примере "собака, едущая на велосипеде"). Еще более
удивительно, что если испытуемым иногда предлагают закреплять ассоциации с помощью
предложений, а иногда с помощью образов, они плохо помнят, какой из этих методов
они применяли (Bower а. о., 1972). Казалось бы, если в одном случае формируются
образы, а в другом — предложения, то испытуемые смогут сказать, каким они воспользовались
посредником для связывания парных слов. На самом же деле они не в состоянии
провести четкое различие между ними. Это заставляет думать, что "образы" ничем
не отличаются от того, что возникает при использовании предложений. По мнению
Боуэра, предлагают ли испытуемому использовать образы или предложения, его в
обоих случаях побуждают к поискам и кодированию осмысленных взаимосвязей между
заданными словами. Боуэр полагает, что именно образование смысловых связей,
а не какой-то мысленный образ облегчает запоминание парных ассоциаций; потому-то
эти два типа опосредования и дают одинаковый эффект.
Уайзмен и Нейссер (Wiseman a. Neisser, 1971) представили другие экспериментальные
данные, свидетельствующие о единстве образного и вербального кодирования. Они
показывали испытуемым серии так называемых картинок Муни, которые можно получить,
убирая часть контуров с изображений различных сцен. Разобраться, что именно
изображено на таких картинках, довольно трудно, но иногда все же удается понять
их сюжет, несмотря на искажение. Рассматривая картинки, испытуемые пытались
разгадать их смысл. Затем проводилась проверка на узнавание, в которой дистракторами
служили другие картинки того же типа. При этом Уайзмен и Нейссер установили,
что узнавание бывало успешным только в тех случаях, когда испытуемые при первом
предъявлении данной картинки давали ей какую-то интерпретацию, а при проверке
на узнавание вновь интерпретировали ее таким же образом. В других случаях (когда
картинку не удавалось интерпретировать при первом предъявлении или же при проверке)
эффективность узнавания была очень низкой. Эти результаты позволяют предполагать,
что узнавание основано не на сравнении картинок, предъявляемых при проверке,
с хранящимися в памяти образными следами. Для правильного узнавания важно, чтобы
испытуемые при проверке интерпретировали картинку так же, как при первом предъявлении.
Просто увидеть картинку, идентичную предъявленной ранее, для правильного узнавания
недостаточно. Во время 1 проверки испытуемые, по-видимому, не сравнивали подлежащие
узнаванию картинки с хранящимися в ДП сценами, не получившими интерпретации;
они, очевидно, сопоставляли свои прежние выводы относительно содержания этих
картинок со своей текущей интерпретацией. Это говорит в пользу того, что испытуемые
сохраняли информацию о результатах проведенного ими анализа данного стимула,
а не копию стимула.
Данные, полученные Нелсоном, Метцлером и Ридом (Nelson а. о., 1974), тоже свидетельствуют
против идеи о сохранении в ДП детализированных копий картинок. Эти авторы указывают,
что подобная идея часто выдвигалась для объяснения поразительной способности
испытуемых узнавать картинки, предъявлявшиеся им в прошлом (см., например, Shepard,
1967); иными словами, предполагалось, что превосходство образной памяти над
вербальной обусловлено большей детальностью сохраняемой в памяти информации
о картинках. А в таком случае узнавание любой детали должно приводить к узнаванию
всей картинки, что и дает картинкам преимущество по сравнению с относительно
скудной словесной информацией. Для проверки этой гипотезы Нелсон и его сотрудники
провели эксперименты, в которых информация об одной и той же сцене была представлена
стимулами четырех различных типов (рис. 12.4): одной фразой, рисунком, не содержащим
деталей, подробным рисунком и фотографией. Каждому испытуемому предъявляли один
из этих четырех стимулов, а затем проводили пробу на узнавание. Оказалось, что
эффективность узнавания в экспериментах с любым из трех образных стимулов была
выше, чем с вербальным стимулом. При этом результаты узнавания для всех трех
образных стимулов были одинаковыми; иначе говоря, большая детализация не облегчала
узнавания. Эти результаты означают, что превосходство памяти на картинки не
обусловленохранением в ДП их детализированных копий. Более того, возникает сомнение
в том, хранятся ли вообще образные стимулы в ДП в виде неких картин. Одинаковая
легкость узнавания недетализированных и детализированных картинок согласуется
с представлением о том, что в памяти испытуемых хранились интерпретации, а не
"изображения" стимулов. В данном случае эти интерпретации, по-видимому, были
достаточно абстрактны и потому одинаково пригодны в качестве описаний для картинок
с разной степенью детализации.
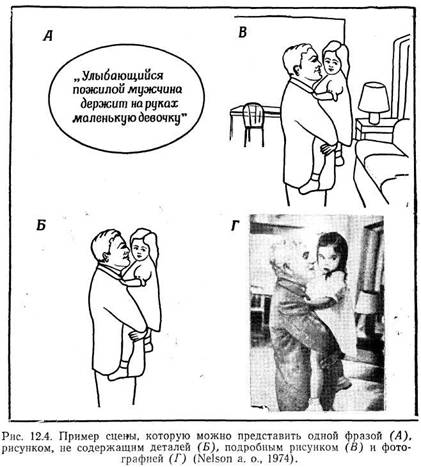
Представление о том, что в основе понимания речи лежат образы, также
вызвало возражения. Критике подверглась, в частности, гипотеза Бегга и
Пайвио (Begg a. Paivio, 1969) о том, что конкретные предложения могут быть
представлены в памяти образами, а абстрактные-словами. Прежде всего
оказалось, что результаты Бегга и Пайвио трудно воспроизводимы (см.,
например, Tieman, 1971), и была высказана мысль, что использованные ими
абстрактные и конкретные предложения различались по таким факторам, как
понятность и степень наглядности (Johnson а. о., 1972). Со своей
стороны Фрэнке и Брэнсфорд (Franks a. Bransford, 1972) подвергли
сомнению гипотезу образного кодирования. Они провели эксперимент, сходный с
их более ранним исследованием, касавшимся вербальной абстракции (см. гл.
9) (Bransford a. Franks, 1971). Как помнит читатель, в этой более
ранней работе испытуемым предъявляли группы предложений, созданных
путем различных сочетаний четырех простых фраз. При последующей проверке
узнавание предложений зависело от того, сколько в них сочеталось идей из
числа содержавшихся в четырех исходных фразах, а не от того,
предъявлялись ли эти предложения на самом деле. Из этого Фрэнке и
Брэнсфорд заключили, что испытуемый, восприняв исходную группу фраз,
интегрировал содержавшуюся в них информацию и закладывал на хранение некую
обобщенную версию; на этой последней он и основывал свое суждение при
узнавании, а поэтому чем больше исходных простых идей содержало
предложение (и тем самым — чем оно больше походило на интегрированную
форму), тем легче оно "узнавалось" как старое.
В своей ранней
работе Брэнсфорд и Фрэнке (Bransford a. Franks, 1971) использовали
конкретные предложения. Исходя из представлений Бегга и Пайвио, следовало
бы ожидать, что с абстрактными предложениями результаты будут иными;
ведь эти авторы считают, что абстрактные предложения хранятся в вербальной
форме и соответственно изменения формулировок выявляются в них легче, чем
изменения смысла. А это должно означать, что в эксперименте Фрэнкса и
Брэнсфорда эффективность узнавания в случае абстрактных предложений была
бы выше. Однако вопреки этому эксперимент с абстрактными предложениями
(Franks a. Bransford, 1972) дал такие же результаты, как и с конкретными
предложениями. Из этого вытекает, что те и другие перерабатываются в памяти сходным образом. В целом
все эти данные свидетельствуют против гипотезы о роли образов в запоминании предложений.
СУЩЕСТВУЮТ ЛИ ВСЕ-ТАКИ "ОБРАЗЫ"?
ВОЗМОЖНЫЙ ПУТЬ К РАЗРЕШЕНИЮ ПРОТИВОРЕЧИЯ
Если гипотеза образного
кодирования несостоятельна, на что, по-видимому, указывают изложенные выше
логические доводы и экспериментальные данные, то что же остается? Как
можно объяснить влияние образности на эффективность запоминания? И почему
нам часто кажется, что у нас возникают яркие мысленные образы? Один из
ответов на вопрос о том, почему инструкции, рекомендующие испытуемым создавать себе образы запоминаемых элементов, и высокие величины ОП
("образной представимости" слов) могут облегчать запоминание,
предложили Андерсон и Боуэр (Anderson a. Bower, 1973). По их мнению, в
условиях, способствующих созданию образов, информация, которая кодируется и
закладывается на хранение в ДП, более насыщенна и более детализирована в концептуальном отношении. В таком случае разница между
образной и необразной формами хранения связана с детальностью кодирования, а
не с каким-то качественным различием, подобным различию между картинами
и словами. Семантически более насыщенные "образные" коды легче
поддаются извлечению, чем и объясняется их благоприятный эффект при
заучивании слов.
Для того чтобы объяснить наши субъективные впечатления относительно мысленных картин, вернемся к концепции "рабочего
пространства" в кратковременной памяти. В гл. 7 были рассмотрены данные о
существовании в КП зрительных кодов. Эти коды могли бы возникать вслед за
предъявлением какого-либо зрительного стимула или же строиться на
основе информации, хранящейся в ДП. Если в ДП хранится не зрительный
образ, а какое-то более абстрактное описание виденной сцены, то этого все же
может быть достаточно для создания в КП кода, напоминающего картину
(аналогичные соображения высказывал Pylyshyn, 1973). Этот-то воссозданный "образ" и мог бы лежать в основе субъективного представления
о возникающих у нас мысленных картинах. Следует, однако, отметить, что,
поскольку такого рода образ создается из информации, содержащейся в ДП, он
не может быть более детальным, чем эта информация. Поэтому он в лучшем
случае представляет собой абстрагированную копию зрительно воспринятой сцены.
Воспользовавшись терминоло:гией Шепарда, мы могли бы сказать, что он
находится в отношении изоморфизма второго порядка к этой сцене. Однако
эксперименты Шепарда с мысленным поворотом (рассмотренные в гл. 7)
показывают, что образы в некоторых случаях очень сходны с теми внешними
объектами, которым оии соответствуют.
Из всего сказанного выше ясно,
что есть веские доводы как за, так и против существования образов. Это не
должно вызывать удивления: как уже отмечалось, проблема мысленных
образов-одна из наиболее старых среди спорных проблем психологии, и можно
думать, что она будет оставаться спорной еще довольно долго. Но, несмотря на
все противоречия, можно сформулировать некоторые основные положения
относительно зрительной памяти. Во-первых, нельзя считать, что внешний
мир представлен в долговременной памяти в виде картин, соответствующих
объектам во всех деталях; такую возможность, по-видимому, следует исключить,
исходя как из логических соображений, так и из экспериментальных данных. Во-вторых, надо признать, что в ДП содержится информация о
зрительно воспринимаемых сценах, поскольку такая информация необходима для
распознавания образов и припоминания вещей, виденных прежде. Остается,
однако, неясным, до какой степени содержащаяся в ДП информация или образы,
воссоздаваемые из этой информации, сходны с "мысленными"
картинами. По этому вопросу споры, безусловно, еще могут продолжаться.
Глава 13
Мнемонасты, шахматная игра и память
В предшествующих двенадцати главах этой книги мы проделали большой путь. Рассматривая
память человека, мы затронули много разнообразных тем: распознавание входных
сообщений, поступающих из внешнего мира, проблемы кратковременной памяти и сложнейшие
аспекты долговременной памяти. В этой заключительной главе мы обсудим две связанные
между собой темы. Одна из них — это мнемоника, а другая — связь между памятью
и специальными навыками и способностями. Последняя тема будет рассмотрена на
примере, довольно подробно изученном психологами, — на примере специфических
способностей, которыми обладают шахматисты. Каждая из этих тем интересна сама
по себе, однако здесь мы затронем лишь тот их аспект, который может помочь нам
собрать воедино большую часть рассмотренного в этой книге материала, ибо при
обсуждении мнемоники и шахматной игры нам придется коснуться роли процессов,
связанных с восприятием и с кратковременной и долговременной памятью.
МНЕМОНИКА И МНЕМОНИСТЫ
Как уже упоминалось в гл. 5,
"мнемоникой" называют использование специально усвоенных приемов и
стратегий, помогающих запоминанию. В предыдущих главах мы уже неоднократно имели дело с различными мнемоническими приемами. Приведем в
качестве примеров два из них: использование зрительного образа или
какого-нибудь предложения для опосредования парных ассоциаций, использование
словпосредников для кодирования бессмысленных слогов. Некоторые
другие мнемонические приемы знакомы почти каждому, как, например,
кодирование числа π словами "что я знаю о кругах" или запоминание порядка цветов в спектре с помощью фразы "Каждый охотник желает знать, где сидят
фазаны". Есть
ряд примеров, облегчающих запоминание целых списков каких-либо элементов.
Один из них — это "метод мест", старинный способ, помогающий запомнить
длинный ряд объектов: их мысленно помещают один за другим в различные
места, последовательность которых была специально заучена. Другой способ
запомнить список состоит в том, чтобы придумать рассказ, вплетая в него
названия элементов.
Еще один способ запоминания списков называется системой "слов-вешалок", или
опорных слов. Эта система позволяет запомнить списки, содержащие до 10 элементов,
число которых, впрочем, можно без труда увеличить. Прежде всего мнемонист должен
твердо заучить десять слов, например: "булка, башмак, дерево, дверь, улей, палка,
небо, ворота, линия, курица1" После этого делается примерно то же,
что и в методе мест. Допустим, вам предлагают заучить следующий список: ХЛЕБ,
ЯЙЦА, ГОРЧИЦА, СЫР, МУКА, МОЛОКО, ПОМИДОРЫ, БАНАНЫ, МАСЛО, ЛУК. Чтобы запомнить
этот список, вообразите себе каждый его элемент во взаимодействии с соответствующим
элементом списка опорных слов. Представьте себе булку, растущую из буханки хлеба,
несколько разбитых яиц в башмаке, дерево, на котором висят баночки с горчицей,
и так далее. Для того чтобы позже воспроизвести список элементов, достаточно
вспомнить опорные слова, и каждое из них воскресит в памяти соответствующий
элемент.
1В оригинале это — рифмованный список, позволяющий легко запомнить порядковый номер каждого слова:
" Oneis a bun; two is a shoe; three is a tree; four is a door; five is a hive; six are sticks; seven is heaven;
eight is a gate; nine is a line; ten is a hen." — Прим. перев.
Многим мнемоническим приемам легко научиться, другие довольно трудны; есть
даже такие, которыми могут пользоваться только особенно квалифицированные мнемонистылюди,
по той или иной причине специально занимающиеся этим делом. Боуэр (Bower, 1973)
сообщает о своих впечатлениях от встречи с группой таких мнемонистов высокого
класса. Он присутствовал на съезде мнемонистов, где каждый стремился превзойти
своих собратьев в различных мнемонических фокусах и трюках. Как пишет Боуэр,
мнемонисты оказались весьма искусными. Один из них, выслушав четыре лова, предложенные
ему из публики, мог быстро написать в перевернутом виде буквы, из которых состояло
одно слово, буквы другого — в обратном порядке, буквы третьего — перевернутыми
и в то же время в обратном порядке и четвертого — в нормальном порядке. Но это
было не все: делая такую запись, он равномерно чередовал буквы из одного слова
с буквами из других, не нарушая при этом последовательности букв в пределах
каждого отдельного слова. Однако и этого ему показалось недостаточно, так как
он еще одновременно декламировал "The Shooting of Dan McGrew". Другой мнемонист
мог, просмотрев колоду перетасованных карт, точно перечислить их по порядку.
Засвидетельствовать навыки этих удивительных мнемонистов не составляет труда.
Совсем не трудно также восторгаться их искусством. Зато очень трудно установить,
как им удается проделывать все это. Боуэр спрашивал мнемониста, который устраивал
мешанину из слов, как он это умудряется делать. Тот ответил, что в результате
очень длительной практики его руки просто сами делают все, что нужно, а ему
достаточно думать о названных ему словах. Не удивительно, что его ответ совершенно
не отражает сути дела. Но ведь мы оказались бы в столь же затруднительном положении,
если бы нас попросили объяснить словами, как мы играем какую-нибудь пьесу на
рояле, или как мы находим ответ на вопрос, сколько будет трижды два, или как
мы удерживаем равновесие при езде на велосипеде. В отношении подобного рода
навыков самонаблюдение провести довольно трудно.
Тем не менее можно изучать деятельность мнемонистов при помощи более строгих
методов. Так, удалось подробно исследовать навыки двух чрезвычайно искусных
мнемонистов: одного исследовал Лурия (1968), а другого — Хант и Лав (Hunt a.
Love, 1972). Эти два человека были во многом сходны, вплоть до того, что в детстве
они жили на расстоянии всего 55 км друг от друга. А вместе с тем их мнемонические
навыки несколько различались; например, мнемонист, которого изучал Лурия, по
его собственным словам, в гораздо большей мере пользовался образами, чем тот,
которого изучали Хант и Лав.
Мы подробно расскажем о последнем (будем называть его В. П.), так как о нем
собрано много экспериментальных данных. В жизни В. П. нет ничего из ряда вон
выходящего. Он родился в 1935 г. в Латвии и был единственным ребенком в семье.
В три с половиной года он научился читать, что свидетельствовало о раннем умственном
развитии. В детстве проявилась также его исключительная память: в пятилетнем
возрасте он запомнил план города с населением в полмиллиона, а в десять лет
выучил наизусть 150 стихотворений, что составляло часть программы какого-то
конкурса. Кроме того, в восемь лет он начал играть в шахматы. Все это позволяло
сделать вывод о высоких умственных способностях В. П., и полученные недавно
оценки его коэффициента умственного развития подтверждают такой вывод. Наиболее
высокие оценки он получил при использовании тестов, связанных с памятью. В частности,
в одном тесте, в котором важную роль играет кратковременная память, В. П. получил
оценку 95%. Он набрал также очень много очков в тесте на быстроту восприятия
— способность быстро схватывать детали. Как указывают Хант и Лав, в целом полученные
им оценки свидетельствуют о высоком умственном развитии, но не дают оснований
предсказывать наличие у него исключительной памяти.
Между тем не вызывает сомнений, что В. П. обладает в этом отношении выдающимися
способностями. Хант и Лав доказали это, проведя с ним ряд экспериментов, многие
из которых уже знакомы читателю (там, где это возможно, будет указана глава,
в которой был описан данный экспериментальный метод). Рассмотрим сначала результаты
В. П. при выполнении задач, связанных с кратковременной памятью. Одна из самых
основных задач такого рода — это задача на определение объема памяти, т. е.
числа структурных единиц, которое может вместить КП (см. гл. 5). Как известно,
объем памяти обычно находится в пределах 5-9 элементов. Вначале, когда В. П.
быстро предъявляли ряд цифр, не создавалось впечатления, что его память отличается
какой-то исключительной емкостью. Однако вскоре он нашел способ увеличить объем
памяти. Когда ему предъявляли цифры с интервалами в 1 с, он объединял их в группы
по 35 цифр, а затем ассоциировал с каждой такой группой какой-либо вербальный
код (примером группы цифр, явно удобной для кодирования, может служить 1492).
Действуя таким образом, он без труда увеличил объем своей памяти до 17 цифр.
Контрольным испытуемым, которым рассказали об этом способе кодирования, также
удалось несколько увеличить объем своей памяти, но далеко не столь значительно.
Представляют также интерес данные о забывании из КП, полученные в задаче Петерсона
и Петерсон (см. гл. 6). В этой задаче требуется удерживать в памяти три согласные,
одновременно ведя обратный счет тройками. Обычно у испытуемых наблюдается быстрое
угасание следа на протяжении 18-секундйого интервала; однако у В. П. в этот
период почти или вовсе не отмечалось забывания. Так было не только в первой
пробе (когда проактивное торможение минимально и эффективность воспроизведения
достигает максимума), но и во всех остальных пробах. Возможное объяснение таких
результатов предложил сам В. П. Он сказал, что знание нескольких языков позволяло
ему ассоциировать какое-нибудь слово почти с любой тройкой согласных, которую
ему предъявляли для запоминания, и таким образом он превращал трш буквы в одну
структурную единицу. В данном случае отсутствие забывания можно было бы предсказать
исходя из того, что известно о влиянии числа структурных единиц при вы полнении
задачи Петерсонов: в случае трех таких единиц забывание выражено гораздо сильнее,
чем в случае одной единицы. Кроме того, использование нескольких языков могло
приводить к снятию проактивного торможения (как в работе Уиккенса, см. гл. 7),
что должно было уменьшать забывание. Это обусловлено тем, что каждый язык представляет
собой как бы новый класс запоминаемых элементов, а переключение на новый класс
обычно ведет к снятию проактивного торможения.
Хант и Лав исследовали также способность В. П. к сканированию памяти, использовав
для этого задачу Стернберга (гл. 7). Напомним, что в этой задаче испытуемый
должен указать, входил ли данный стимул в набор элементов, предъявлявшихся ему
незадолго до проверки. В этих экспериментах измеряют время реакции, которое
обычно линейно возрастает с увеличением числа элементов в первоначальном наборе.
Однако в опытах с В. П. такого возрастания не наблюдалось. Он "просматривал"
в своей памяти заученный набор из шести элементов так же быстро, как и один
элемент, и для этого ему нужно было примерно столько же времени; сколько затрачивали
на один элемент другие испытуемые. Это позволяет предполагать, что в отличие
от большинства испытуемых у В. П. поиск нужного элемента в КП осуществлялся
путем параллельного обследования всех содержащихся в ней элементов.
Все эти результаты говорят о том, что объем памяти В. П. не отличается заметным
образом от обычного. Однако его КП совершенно необычна в других отношениях.
Он способен к параллельному сканированию информации, хранящейся в КП; он может
также удерживать элементы в КП в условиях, в которых другие люди их забывают;
он обладает большей способностью к структурированию, чем другие испытуемые.
По-видимому, эти свойства памяти В. П., по крайней мере частично, обусловлены
его способностью производить опосредование и перекодирование входной информации
с невероятной скоростью. А это позволяет ему быстро производить структурирование,
что в свою очередь лежит в основе способности увеличивать объем памяти и не
поддаваться влияниям интерференции в КП. Ввиду аналогичного влияния опосредования
и организации на долговременное хранение информации можно было ожидать, что
В. П. обладает такими) же исключительными способностями и в отношении длительного
запоминания. Так оно и оказалось на самом деле.
Хант и Лав изучали долговременную память В.
П. с помощью нескольких заданий. Одним из них был пересказ легенды
"Война духов", использованной в экспериментах Бартлета, которую
большинство испытуемых при воспроизведении искажало (гл. 9). В. П.
прослушал эту легенду, после чего он провел обратный счет семерками начиная
от числа 253 и до нуля. Затем он воспроизводил определенные указанные
ему части легенды по прошествии интервалов от 1 минуты до 6 недель. Во
всех случаях он удивительно хорошо припоминал легенду. Он пересказывал ее
очень близко к тексту, хотя и не мог воспроизвести дословно. При этом спустя
недель он помнил ее так же хорошо, как и через час после прослушивания.
Чем объясняются такие прекрасные результаты В. П. в экспериментах по проверке
памяти? Прежде всего оказалось, что он, по-видимому, не прибегает к зрительным
образам. Конечно, В. П. не безразличен к степени образности, поскольку и он
запоминает элементы с высокой "образной представимостью" лучше, чем с низкой
(гл. 12). По собственному признанию, он иногда прибегает к образным мнемоническим
приемам, но в основном использует вербальные приемы. На то, что В. П. нечасто
использует зрительные образы, указывают результаты выполнения им задачи Фрост
на группировку картинок (гл. 12). В. П. и контрольным испытуемым сначала предъявили
картинки, которые Фрост использовала в качестве стимулов (и которые можно сгруппировать
как по содержанию, так и по пространственной ориентации), а затем, спустя некоторое
время, провели неожиданную проверку на свободное припоминание. При этом у контрольных
испытуемых наблюдалась сильно выраженная тенденция к группировке картинок по
их ориентации, тогда как В. П. группировал их только по содержанию. Создавалось
впечатление, что стимулы хранились в его памяти не в виде зрительных образов.
В другом случае В. П. предложили запомнить две матрицы, состоявшие из 8 рядов
по 6 чисел в каждом. В одной матрице цифры были расположены ровными рядами,
а в другой ряды были неровные и расстояния между цифрами неодинаковые. После
недолгого просмотра этих матриц В. П. мог безукоризненно воспроизвести как ту,
так и другую и притом с одинаковой скоростью. Поскольку на прочтение "расшатанной"
матрицы уходит больше времени, эти результаты позволяют думать, что В. П. не
"считывал" эту матрицу "с какого-то хранящегося в памяти зрительного образа.
Действительно, сам В. П. объяснил, что он пользовался словесными мнемоническими
приемами, например закладывал в память ряд цифр, представляя его себе как какую-то
дату и запоминая, что он делал в тот день.
Итак, создается впечатление, что В. П. — мнемонист, обладающий исключительной
вербальной памятью. Он способен при предъявлении ему не связанных между собой
стимулов быстро создавать мнемонические схемы и использовать их для структурирования
и организации материала. Это и приводило к неправдоподобно высоким показателям
в экспериментах с КП и ДП. Очень помогает ему также прекрасная способность быстро
схватывать детали, благодаря которой он тотчас же находит основу для использования
какого-нибудь мнемонического приема. Возможно, что необычайные способности В.
П. связаны еще с одним фактором — с рано начавшейся тренировкой памяти. И В.
П., и мнемонист, которого исследовал Лурия, — воспитанники школ с одной и той
же системой обучения (их школы даже находились в одном и том же географическом
районе), в которой главную роль играла зубрежка. В подобных условиях учащемуся
приходится развивать свои способности к заучиванию наизусть. Так и напрашивается
вывод — хотя, конечно, в высшей степени умозрительный, — что эти приобретенные
в детском возрасте навыки могли послужить толчком, побудившим В. П, к совершенствованию
в этой области.
ПАМЯТЬ И ШАХМАТЫ
Интересно
отметить, что В. П. прекрасный шахматист. Он выступал публично, давая сеансы
одновременной игры на семи досках и притом вслепую, не глядя на доску. Кроме
того, он проводит множество партий по переписке, и при этом ему не
приходится записывать ходы, чтобы следить за развитием игры. Подобные
демонстрации памяти производят сильное впечатление и вполне соответствуют
всему тому, что нам известно о выдающихся способностях В. П. как мнемониста. Оказывается, однако, что в области шахмат проявление таких
способностей встречается довольно часто: большинство шахматных мастеров и
гроссмейстеров могут почти безошибочно воспроизвести позицию, если им
показать доску всего на 5 с (deGroot, 1965, 1966). Но они способны
делать это только в тех случаях, когда расположение фигур на шахматной
доске отражает какой-то момент реальной игры; если же расставить фигуры
случайным образом, то мастер сможет восстановить увиденную им картину
ничуть не лучше, чем какой-нибудь неважный шахматист. Это указывает на
то, что способность мастеров шахматной игры воспроизводить позицию на доске связана,
по-видимому, не с какими-то особыми возможностями их КП, а с их познаниями
в самой игре.
Способности мастеров воспроизводить "естественные"
шахматные позиции посвящен ряд работ Саймона и его сотрудников (Simon
a. Barenfeld, 1969; Chase a. Simon, 1973; Simon a. Gilmartin, 1973). Одним
из результатов этих исследований было моделирование памяти шахматиста на
вычислительной машине. Составленная этими авторами машинная программа
представляет особый интерес, так как она показывает, каким образом
процессы восприятия и функции кратковременной и долговременной памяти,
сочетаясь друг с другом, создают основу для эффективного запоминания.
Саймон и Баренфельд (Simon a. Barenfeld, 1969) начали с изучения
перцептивных аспектов воспроизведения позиций на шахматной доске. В
частности, их интересовало, как шахматисты рассматривают эту доску в
первые несколько секунд после того, как им предъявят новую группировку
фигур. Данные о запоминании ими таких группировок показывают, что
-хорошие шахматисты за эти первые несколько секунд успевают получить
удивительно много информации. Кроме того, путем регистрации движений глаз
шахматистов было установлено, что их внимание бывает сосредоточено на тех
фигурах, которые занимают наиболее важное стратегическое положение.
Саймон и Баренфельд предложили модель восприятия шахматной доски, которую они
реализовали в виде программы для вычислительной машины. В основе их программы
лежит предположение, что шахматист прежде всего фиксирует свое внимание на одной
из важных фигур, находящихся на доске. Но, сосредоточив внимание на одной фигуре,
он в то же самое время периферическим зрением собирает информацию относительно
соседних фигур. В частности, он отмечает, какие из них находятся в существенных
отношениях с главной фигурой — угрожают ей, защищают ее или находятся под ее
угрозой или защитой. Затем шахматист переводит взгляд на одну из этих фигур,
связанных с главной, концентрирует на ней свое внимание, потом переходит к третьей
и т. д. Таким образом, зрительное внимание игрока перемещается по доске, переходя
от одной важной фигуры к другой и руководствуясь осмысленными взаимосвязями
между фигурами. Основанная на этих предположениях моделирующая программа позволяла
получить приблизительно такие же движения глаз, какие совершают люди, играющие
в шахматы.
Эффективное зрительное кодирование шахматной позиции — это лишь один из аспектов
ее воспроизведения. Каким образом шахматист, восприняв расположение фигур, удерживает
его в памяти? Ведь он способен воспроизвести всю позицию, посмотрев на нее в
течение 5 секунд. Ввиду столь короткого интервала удержания можно думать, что
при этом используется емкость кратковременной памяти. Но так как емкость КП
ограничена, вся нужная информация должна храниться в виде всего лишь нескольких
структурных единиц. Поэтому для воспроизведения позиции необходимо, чтобы соответствующая
информация, после того как она будет воспринята, была структурирована и заложена
в КП.
Роль КП в воспроизведении шахматных
позиций изучали Саймон, Чейз и Джилмартин. Они исходили из гипотезы о
том, что способность мастеров шахматной игры к такому воспроизведению
объясняется их умением структурировать информацию, воспринимаемую с доски.
Согласно этой гипотезе, шахматист высокого класса, взглянув на доску,
распознает некоторые сочетания фигур как знакомые. Этим группировкам
он может приписать определенные метки или коды, чтопозволяет воспринимать
их как отдельные структурные единицы (подобно тому как сочетание трех букв
ООН превращается в одну структурную единицу). Комбинируя различныегруппировки фигур в такие единицы, шахматист может разместить их в том
объеме, которым обладает КП. Благодаря этому он получает возможность удержать в памяти
информацию о расположении фигур на доске и использовать эту информацию для воспроизведения позиции. Более слабые шахматисты,
несомненно, гораздо менее способны распознавать группировки фигур и
кодировать их в виде структурных единиц, а это означает, что их
способность к воспроизведению позиций будет ниже. Следует также указать, что
и мастера, и слабые игроки в равной мере не способны к кодированию
случайных расстановок, так как последние не могут быть распознаны как
осмысленные.
Чейз и Саймон подвергли эту гипотезу проверке, предложив шахматистам разного
уровня — от мастеров до начинающих-две задачи (рис. 13.1). В одной из них тестировалась
память: испытуемый должен был воспроизвести позицию, которую он видел всего
5 секунд. Другая задача была связана с восприятием: испытуемый должен воспроизвести
позицию, которая стояла у него на виду. Видеомагнитофон позволял регистрировать
переключение взгляда испытуемого со стимульной доски на доску для воспроизведения
и обратно.
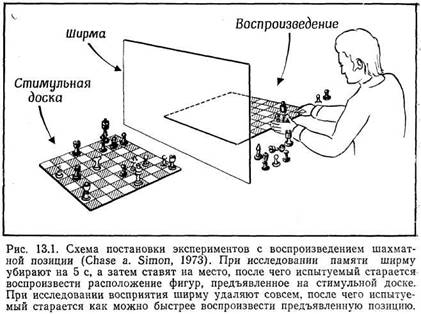
В задаче на восприятие Чейз и Саймон считали "структурной единицей" любую группу
фигур, расставляемых на доске для воспроизведения в промежутке между двумя взглядами
на стимульную доску. В задаче на запоминание "структурной единицей" считалась
совокупность фигур, расставленных с очень короткими (не более 2 с) интервалами
между ними" Если между постановкой двух фигур проходило больше двух секунд,
то их относили к разным структурным единицам. Такое определение представляется
оправданным, если допустить, что испытуемый быстро расставляет все фигуры, входящие
в одну структурную единицу, затем делает паузу, во время которой пытается декодировать
следующую единицу, быстро расставляет входящие в нее фигуры, делает паузу и
так далее. [Подобного же рода рассуждения были использованы Джонсоном при рассмотрении
вероятности переходной ошибки (см. гл. 5).] Обоснованность этих определений:
"структурной единицы" подтверждается тем, что пространств венные отношения между
фигурами, которые при этом следовало относить к одной структурной единице, оказывались
сходными в обеих задачах. Кроме того, полученные в результате структурные единицы
в обоих случаях имели примерно одинаковую величину; в задаче на восприятие такая
единица содержала (в среднем) 2,3 фигуры, а в задаче на запоминание—2,2.
Определив таким образом структурные единицы, Чейз и Саймон подсчитали среднее
число структурных единиц и число фигур на одну единицу для мастера, шахматиста-перворазрядника
и начинающего. Они нашли, что в задаче на запоминание величина структурной единицы
зависит от мастерства шахматиста: число фигур, составляющих одну единицу, уменьшается
со снижением уровня игрока. Это согласуется с гипотезой о том, что опытные игроки
способны лучше воспроизводить шахматную позицию потому, что они вмещают в одну
структурную единицу больше фигур. В задаче на восприятие выявилось другое различие
между игроками разной квалификации. Хотя величина структурной единицы была здесь
примерно такой же, как и в задаче на запоминание, она уже не зависела от мастерства
шахматиста: среднее число фигур, охватываемых одним взглядом на стимульную доску,
было приблизительно одинаковым как для новичка, так и для мастера. Однако чем
выше был класс игрока, тем меньше времени ему нужно было смотреть на доску.
Это говорит о том, что в задаче на восприятие мастер, затратив гораздо меньше
времени, собирает столько же информации, сколько и новичок. Таким образом, мы
убеждаемся, что мастера способны быстрее воспринять позицию на доске и закодировать
ее, а кроме того, они более эффективно структурируют то, что восприняли.
И наконец, Чейз и Саймон исследовали характер структурных единиц, создаваемых
шахматистами высокого класса. Число конфигураций, соответствующих отдельным
структурным единицам в задаче на запоминание, было сравнительно небольшим, и
они отражали взаимосвязи между фигурами, имеющие определенный смысл в шахматной
игре. Свыше 75% всех структурных единиц, создаваемых мастерами, относилось всего
лишь к трем классам ситуаций, и все они были весьма типичными для шахматных
позиций. А это означает, что шахматист-мастер при создании структурных единиц
использует сравнительно небольшое число группировок, хранящихся в ДП. Таким
образом, эти результаты подтверждают гипотезу, согласно которой шахматисты высокого
класса используют содержащиеся в ДП группировки для быстрого перекодирования
позиций на шахматной доске, что облегчает им кратковременное запоминание этих
позиций.
Саймон и Джилмартин (Simon a. Gilmartin, 1973) продолжили эти исследования
на шахматах, разработав моделирующую программу, в которой сочетались первоначальная
перцептивная программа с обучающейся системой. Они показали, что эта более сложная
программа может воспроизводить расположение фигур на доске так же хорошо или
даже лучше, чем шахматист-перворазрядник, если в ее память заложено примерно
1000 группировок. По их оценкам, если заложить в память около 50 тысяч, а возможно,
и меньше группировок, то машина сможет воспроизводить позиции не хуже мастера.
Кажется вполне правдоподобным, что у мастера за долгие годы игры в шахматы может
накопиться в памяти такой запас группировок (Simon a. Barenfeld, 1969).
* * *
В этом довольно подробном разборе двух ситуаций, в которых главную роль играет
память, мы еще раз затронули ряд тем, обсуждавшихся в книге. При рассмотрении
явлений, лежащих в основе специфических способностей выдающихся мнемонистов
и шахматных мастеров, нам пришлось затронуть все этапы функционирования памяти
—от приема входных сообщений до их окончательного анализа и хранения. Изложенные
в двенадцати предшествующих главах сведения о кодировании, хранении и извлечении
информации оказались полезными для анализа двух специфических способностей,
которым посвящена эта последняя глава. Представители когнитивной психологии
надеются, что эти сведения окажутся также полезными для понимания более общих
аспектов человеческой памяти и ее роли в умственной деятельности.
>Список литературы
Adams 1. А., 1967. Human Memory, New York, McGraw-Hill.
Alien M.,
1968. Rehearsal strategies and response cueing as determinants of
organization in free recall, J. of Verbal Learning and Verbal Behavior,
7,58-63.
Anderson J. R., Bonier G. H., 1972. Recognition and retrieval
processes in free recall. Psychological Review, 79, 97-123.
Anderson J. R., Bonier G. H., 1973. Human Associative Memory, Washington, D. C., V. H.
Winston and Sons.
Anderson J. R., Bonier G. H., 1974. A propositional theory
of recognition memory, Memory and Cognition, 2, 406-412.
Atkinson R. C., Juola J. F., 1973. Factors influencing speed and accuracy of
word recognition. In: S. Kornblum (ed.). Attention and Performance IV, New York,
Academic Press.
Atkinson R. C., Shiffrin R. M., 1968. Human memory: A proposed system and its
control processes. In: K. W. Sponce and J. T. Spence (eds.), The Psychology
of Learning and Motivation: Advances in Research and Theory (Vol. 2), New York,
Academic Press.
Averbach E., Conell A. S.,
1961. Short-term memory in vision, Bell System Technical J., 40, 309-328.
Averbach E., Sperling G., 1961. Short-term storage of information in vision.
In: C. Cherry (ed.), Fourth London Symposium on Information Theory,
London and Washington, D. C., Butterworth.
Baddeley A. D., 1972.
Retrieval rules and semantic coding in short-term memory, Psychological
Bulletin, 78, 379-385.
Baddeley A. D., Dale H. C. A., 1966. The effect of
semantic similarity on retroactive interference in long- and short-term
memory, J. of Verbal Learning and Verbal Behavior, 5, 417-420.
Barclay J. R., 1973. The role of comprehension in remembering sentences, Cognitive
Psychology, 4, 229-254.
Barnes J. M., Underwood B. 1., 1959. of
first-list associations in transfer theory, J. of Experimental Psychology,
58, 97-105.
Bartlett F. C., 1932. Remembering: A Study in Experimental and
Social Psychology, Cambridge, Cambridge University Press.
Battig W.
F., Montague W. E., 1969. Category norms for verbal items in 56 categories:
A replication and extension of the Connecticut category norms, J. of
Experimental Psychology Monograph, 80 (3, Pt. 2).
Begg J., Paivio A., 1969. Concreteness and imagery in sentence meaning, J.
of Verbal Learning and Verbal Behavior, 8, 821-827.
Bobrovs S. A., Bower 0. H., 1969. Comprehension
and recall of sentences, J. of Experimental Psychology, 80, 455-461.
Bousfield А. К.. Bousfield W. A., 1966. Measurement of clustering and of
sequential constancies in repeated free recall, Psychological Reports, 19,
935-942.
Bousfield W. A., 1951. Frequency and availability measures in
language behavior, Paper presented at annual meeting, American
Psychological Association, Chicago.
Bousfield W. A., 1953. The
occurrence of clustering in the recall of randomly arranged associates, J.
of General Psychology, 49, 229-240.
Bousfield W. A., Cohen В. H., 1953. The effects of reinforcement on the occurrence
of clustering in the recall of randomly arranged associates, J. of Psychology,
36, 67-81.
Bousfield W. A., Cohen B. H., Whitmarsh G. A., 1958. Associative
clustering in the recall of words of different taxonomic frequencies of
occurrence, Psychological Reports, 4, 39-44.
Bousfield W. A., Puff C. R., 1964. Clustering as a function of response dominance,
J. of Experimental Psychology, 67, 76-79.
Bower G. H., 1970. Organizational
factors in memory, Cognitive Psychology, 1,18-46.
Bower G. H., 1972a. A
selective review of organizational factors in memory.
In: E. Tulving and W.
Donaldson (eds.). Organization of Memory, New York, Academic Press.
Cower 0. H., 1972b. Mental imagery and associative learning. In: L. Gregg
(ed.), Cognition in Learning and Memory, New York, Wiley, Bower G. H.,
1973. Memory freaks I have known, Psychology Today, 7, 64-65.
Bower G.
H., dark M. C" Lesgold A. M., Winzenz D., 1969. Hierarchical retrieval
schemes in recall of categorized word lists, J. of Verbal Learning and
Verbal Behavior, 8, 323-343.
Bower G. H., Мипог R., Arnold P. G., 1972. On
distinguishing semantic and imaginal mnemonics. Unpublished manuscript.
Bower G. H., Springston F., 1970. Pauses as recoding points in latter
series, J. of Experimental Psychology, 83, 421-430.
Bower G. H., Winzenz
D., 1970. Comparison of associative learning strategies, Psychonomic
Science, 20, 119-120.
Bransford S. D., Barclay }. R., Franks f. }., 1972.
Sentence memory: A constructive versus interpretive approach, Cognitive
Psychology, 3, 193.209.
Bransford S. D., Franks }. 1., 1971. The abstraction of linguistic ideas, Cognitive
Psychology, 2,331-350.
Briggs G. E., 1954. Acquisition, extinction and recovery functions in retroactive inhibition, J. of Experimental Psychology, 47, 285-293.
Briggs G.
E., 1957. Retroactive inhibition as a function of the degree of original and
interpolated learning, J. of Experimental Psychology, 53, 60-67.
Broadbent D. E., 1958. Perception and Communication, London, Pergamon
Press.
Brown. 1. A., 1958. Some tests of the decay theory of immediate
memory, Quarterly J. of Experimental Psychology, 10, 12-21.
Brown R. W.,
McNeill D., 1966. The phenomenon, J. of Verbal Learning
and Verbal Behavior, 5, 325-337.
Bruce D., Fagan R. L., 1970. More on the
recognition and free recall of organized lists, J. of Experimental
Psychology, 85, 153-154.
Ceraso J., Henderson A., 1965. Unavailability and associative loss in Rl and
PI, J. of Experimental Psychology, 70, 300-303.
Chase W. G., Simon H. A., 1973. Perception in chess, Cognitive Psychology,
4, 55-81.
Cherry E. C., 1953. Some experiments on the recognition of speech with one
and two ears, J. of the Acoustical Society of America, 25, 975979.
Clifton C., Jr., Tash 1., 1973. Effect of syllabic word length on memorysearch
rate, J. of Experimental Psychology, 99, 231-235.
Cofer C. N., 1965. On some factors in the organizational characteristics of
free recall, American Psychologist, 20, 261-272.
Cofer C. N., Bruce D.
R., Reicher G. M., 1966. Clustering in free recall as a function of certain
methodological variations, J. of Experimental Psy. chology, 71, 858-866.
Cohen В. Н., 1966. Some-or-none characteristics of coding behavior, J. Verbal
Learning and Verbal Behavior, 5, 182-187.
Collins A. M., Quillian M. R.. 1969. Retrieval time
from semantic memory, J. of Verbal Learning and Verbal Behavior, 8, 240-247.
Collins A. M., Quillian M. R., 1970. Does category size affect
categorization time? J. of Verbal Learning and Verbal Behavior, 9, 432-438.
Conrad R., 1963. Acoustic confusions and memory span for words, Nature,197,1029-1030.
Conrad R., 1964. Acoustic confusions in immediate memory,
British J. of Psychology, 55,75-84.
Cooper L. A., Shepard R. N., 1973.
Chronometric studies of the rotation of mental images. In: W. G. Chase
(ed.). Visual Information Processing,.
New York, Academic Press.
Craik
F. 1. M., Lockhart R. S., 1972. Levels of processing: A framework for memory
research, J. of Verbal Learning and Verbal Behavior, II, 671684.
Craik
F. 1. M., Watkins M. ]., 1973. The role of rehearsal in short-term memory,
J. of Verbal Learning and Verbal Behavior, 12, 599-607.
Crossman E. R. F.
W., 1958. Discussion of Paper 7 in National Physical Laboratory Symposium.
In: Mechanisation of Thought Processes (Vol. 2),.
London, Н. M. Stationary
Office.
Grouse J. Н., 1971. Retroactive interference in reading prose
materials, J. of Educational Psychology, 62, 39-44.
Crowder R. G.,
Morion J., 1969. Precategorical acoustic storage (PAS), Perception and
Psychophysics, 5, 365-373.
D'Agostino P. R., 1969. The blocked-random effect in recall and recognition,
J. of Verbal Learning and Verbal Behavior, 8, 815-820.
Darwin С. Т., Turvey M. Т., Crowder R. 0., 1972. An auditory
?"inl"gue ofi the Sperling partial report procedure: Evidence for brief
auditory storar ge, Cognitive Psychology, 3, 255-267.
Davis R.,
Sutherland N. S., ludd B. R., 1961. Information content in recognition and
recall, J. of Experimental Psychology, 61, 422-429.
de Groot A. D., 1965.
Thought and Choice in Chess, The Hague, Mouton.
de Groot A. D., 1966.
Perception and memory versus thinking. In: B. Kleinmuntz (ed.). Problem
Solving, New York, Wiley.
Delin P. S., 1969. The learning to criterion of a
serial list with and without mnemonic instructions, Psychonomic Science, 16,
169-170.
Deutsch D., 1970. Tones and numbers: Specificity of interference in
immediate memory. Science, 168,1604-1605.
Deutsch J. A., Deutsch D.,
1963. Attention: Some theoretical considerations, Psychological Review, 70,
80-90.
Donders F. С., 1862. Die Schnelligkeit psychischer Processe, Arch. Anat.PhysioL,
657-681.
Ebbinghaus H., 1885. Ober das Gedachtnis,
Leipzig, Duncker and Humblot.
Franks J. J., Brans ford 1. D., 1971. Abstraction of visual patterns, J. of
Experimental Psychology, 90, 65-74.
Franks J. J., Bransford J. D., 1972. The acquisition of abstract ideas, J.
of Verbal Learning and Verbal Behavior, II, 311-315.
Freud S., 1940. [A
note upon the ] (J. Strachey, trans.), International J.
of Psycho-Analysis, 21, 469.
Friedman M. J., Reynolds 1. H., 1967.
Retroactive inhibition as a function of response-class similarity, J. of
Experimental Psychology, 74, 351355.
Frost N., 1972. Encoding and
retrieval in visual memory tasks, J. of Experimental Psychology,,
95,317-326.
Cardiner J. M., Craik F. 1. M.,
Birtwistle L. 1972. Retrieval cues and release from proactive inhibition, J.
of Verbal Learning and Verbal Behavior, 11, 778-783.
Gray J. A.,
Wedderburn A. A. /., 1960. Grouping strategies with simultaneous stimuli.
Quarterly J. of Experimental Psychology, 12, 180-184.
Green D. M., Svsets J. A., 1966. Signal Detection Theory and Psychophysics,
New York, Wiley.
Guttman N., iulesz B., 1963. Lower limits of auditory periodicity analysis,
J. of the Acoustical Society of America, 35, 610.
Haber R. N., 1969.
Introduction. In: R. N. Haber (ed.), Information-processing Approaches to
Visual Perception, New York, Holt.
Halle M., Stevens K. N., 1959. Analysis
by synthesis. In: W. Wathen-Dunn and L. E. Woods (eds.). Proceedings of the
Seminar on Speech Comprehension and Processing, Bedford, Mass., Air Force
Cambridge Research Laboratories.
Halle M., Stevens K. N., 1964. Speech
recognition: A model and a program for research. In: J. A. Fodor and J. J.
Katz (eds.), The Structure of Language: Readings in the Psychology of
Language, Englewood Cliffs, New Jersey, Prentice-Hall.
Hebb D. 0., 1949. The Organization of Behavior, New York, Wiley.
Hebb D. 0.. 1958. A
Textbook of Psychology, Philadelphia, W. B. Saunders.
Herman Т.,
Broussard 1. G., Todd ff. R., 1951. Intertrial interval and the rate of
learning serial order picture stimuli, J. of General Psychology, 45,
245-254.
Houston 1. P., 1966. First-list retention and time and method of
recall, J. of Experimental Psychology, 71, 839-843.
Hubel D. H., Wiesel
T. N., 1962. Receptive fields, binocular interaction and functional
architecture in the cats visual cortex, J. of Physiology, 160, 106-154.
Hunt E., Love Т., 1972. How good can memory be? In: A. W. Melton and E. Martin
(eds.). Coding Processes in Human Memory, Washington, D. C., V. H. Winston and
Sons.
Jakobson R., Fant G. G. M., Halle M., 1961. Preliminaries
to Speech Analysis: The Distinctive Features and their Correlates,
Cambridge, M. 1. T. Press.
James W., 1890. The Principles of Psychology
(Vol. 1), New York, Henry Holt and Co.
Jenkins 1. J., Mink W. D.,
Russell W. A., 1958. Associative clustering as a function of verbal
association strength, Psychological Reports, 4, 127-136.
Jenkins J. J.,
Russell W. A., 1952. Associative clustering during recall, J. of Abnormal
and Social Psychology, 47, 818-821.
Johnson M. К., Bransford 1. D., Nyberb
S. E., Cleary J. J., 1972. Comprehension factors in interpreting memory
for abstract and concrete sentences, J. of Verbal Learning and Verbal
Behavior, II, 451-454.
Johnson N. F., 1968. Sequential verbal behavior. In:
T. R. Dixon and D. L. Horton (eds.). Verbal Behavior and General Behavior
Theory, Englewood Cliffs, New Jersey, Prentice-Hall.
Rahneman D., 1973.
Attention and Effort, Englewood Cliffs, New Jersey, Prentice-Hall.
Katz
J. J., Fodor J. A., 1963. The structure of a semantic theory, Language,
39,170-210.
Keppel G., Underwood B. J., 1962. Proactive inhibition in
short-term retention of single items, J. of Verbal Learning and Verbal
Behavior, I,. 153-1.61.
Kinney О. С., Marsetta М., Showman D. 1., 1966. Studies in Display Symboli
Legibility, Part XII. The Legibility of Alphanumeric Symbols for Digitalized
Television, Bedford, Mass., The Mitre Corp., November, ESD-TR-66-117.
Kintsch W., 1967. Memory and decision aspects of recognition learning, Psychological Review, 74,496-504.
Kintsch W., 1968. Recognition and free
recall of organized lists, J. of Experimental Psychology, 78,481-487.
Kintsch W., 1970. Models for free recall and recognition. In: D. A. Norman
(ed.). Models of Human Memory, New York, Academic Press.
Klatzky R. L.,
Atkinson R. C., 1971. Specialization of the cerebral hemispheres in
scanning for information in short-term memory. Perception and Psychophysics,
10,335-338.
Koppenall R. J., 1963. Time changes in the strengths of А—В, А—С
lists; spontaneous recovery? J. of Verbal Behavior, 2, 310-319.
Lachman
R., Tuttle A. V., 1965. Approximation to English and short-term memory:
Construction or storage? J. of Experimental Psychology, 70, 386-393.
Landauer Т. К., 1962. Rate of implicit speech, Perceptual and Motor Skills,
15, 646.
Landauer Т. К., Freedman J. L., 1968. Information-retrieval
from long-term memory: Category size and recognition time, J. of Verbal
Learning and Verbal Behavior, 7, 291-295.
Landauer Т. К., Meyer D. E.,
1972. Category size and semantic-memory retrieval, J. of Verbal Learning and
Verbal Behavior, II, 539-549.
Lettvin J. Y., Matiurana H. R.. McCulloch W.
S., Pitts W. H., 1959. What thfrogs eye tells the frogs brain, Proceedings
of the IRE, 47, i9401951.
Lewis М. Q., 1972. Cue effectiveness in cued
recall. Paper presented at theannual meeting of the Psychonomic Society,
St. Louis.
Lindsay P. H., Norman D. A., 1972. Human Information Processing,
NewYork, Academic Press (П. Линдсей, Д. Норман, Переработка информации у человека, изд-во "Мир", М., 1974).
Лурия A. P., 1968. The
Mind of a Mnemonist, New York, Basic Books.
Mandler 0., 1972. Organization
and recognition. In: E. Tulving and W. Donaldson (eds.), Organization of
Memory, New York, Academic Press.
Mandler 0., Pearlstone Z., 1966. Free and
constrained concept learning and subsequent recall, J. of Verbal Learning
and Verbal Behavior, 5, 126131.
Mandler 0., Pearlstone Z., Koopmans H.
S., 1969. Effects of organization and semantic similarity on recall and
recognition, J. of Verbal Learning and Verbal Behavior, 8, 410-423.
Massaro D. W., 1972. Preperceptual images, processing time and perceptual
units in auditory perception, Psychological Review, 79, 124-145.
Mayhem
A. i., 1967. Interlist changes in subjective organization during freerecall learning, J. of Experimental Psychology, 74, 425-430.
McDougall
R., 1904. Recognition and recall, J. of Philosophical and Scientific
Methods, 1,229-233.
McOeoch J. A., 1942. The Psychology of Human Learning,
New York, Longmans Green and Co, Melton A. W., lrwin J. М., 1940. The
influence of degree of interpolated) learning on retroactive inhibition and
the overt transfer of specific responses, American J. of Psychology, 53,
173-203.
Meyer D. E., 1970. On the representation and retrieval of stored
semantic information, Cognitive Psychology, 1, 242-300.
Miller 0. A., 1956. The magical number seven, plus or minus two: Some limits
on our capacity for processing information, Psychological Review, 63,81-97.
Miller О. А., 1962. Some psychological studies
of grammar, American Psychologist, 17,748-762.
Miller 0. A., 1972.
English verbs of motion: A case study in semantics and lexical memory. In:
A. W. Melton and E. Martin (eds.). Coding Processes in Human Memory,
Washington, D. C., V. H. Winston and Sons.
Miller 0. A., Heise G. A.,
Lichten W., 1951. The intelligibility of speech as a function of the context
of the test materials, J. of Experimental Psychology, 41,329-335.
Miller 0. A., Selfridge J. A., 1950. Verbal context and the recall of
meaningful material, American J. of Psychology, 63, 176-187.
Milner
В., 1959. The memory defect in bilateral hippocampal lesions, Psychiatric
Research Reports, II, 43-58.
Montague W. E., Adams J. A., Kiess H. 0., 1966.
Forgetting and natural language mediation, J. of Experimental Psychology,
72, 829-833.
Moray N., 1959. Attention in dichotic listening: Affective cues
and the influence of instructions. Quarterly J. of Experimental Psychology,
II, 56-60.
Moray N., Bates A., Barnett Т., 1965. Experiments on the
four-eared man,J. of the Acoustical Society of America, 38, 196-201.
Morion i., 1970. A functional model for memory. In: D. A. Norman (ed.),
Models of Human Memory, New York, Academic Press.
Morion J., Crowder R.
G., Prussin H. A., 1971. Experiments with the stimulus suffix effect, J.
of Experimental Psychology Monograph, 91, 169190.
Murdoch В. В., Jr.,
1961. The retention of individual items, J. of Experimental Psychology,
62,618-625.
Murdoch В. В., Jr., 1962. The serial position effect of free
recall, J. of Experimental Psychology, 64,482-488.
Murdoch В. В., Jr.,
Walker К. D., 1969. Modality effects in free recall, J. of Verbal Learning
and Verbal Behavior, 8, 665-676.
Neisser U., 1964. Visual search, Scientific
American, 210, 94-102.
Neisser U., 1967. Cognitive Psychology, New York,
Appleton-CenturyCrofts.
Neisser U., Novick R., Lazar R., 1963.
Searching for ten targets simultaneously, Perceptual and Motor Skills, 17,
955-961.
Nelson Т. 0., Metzler }., Reed D. A., 1974. Role of details in the
long-term recognition of pictures and verbal descriptions, J. of
Experimental Psychology, 102,184-186.
Nickerson R. S., 1972.
Binary-classification reaction time: A review of some studies of human
information-processing capabilities, Psychonomic Monograph Supplements, 4,
275-318.
Noble C. E., 1961. Measurements of association value (a), rated
associations (a) and scaled meaningfulness (m) for the 2100 CVC combinations
of the English alphabet, Psychological Reports, 8, 487-521.
Norman D.
A., 1969. Memory and Attention, New York, John Wiley and" Sons.
Osgood C. E., 1952. The nature and measurement of meaning, Psychological
Bulletin, 49,197-237.
Paivio A., 1963. Learning of adjective-noun
paired-associates as a functionof adjective-noun word order and noun
abstractness, Canadian J. of Psychology, 17,370-379.
Paivio A., 1965.
Abstractness, imagery and meaningfulness in paired-associate learning, J.
of Verbal Learning and Verbal Behavior, 4, 32-38.
Paivio A., 1969. Mental
imagery in associative learning and memory, Psychological Review,
76,241-263.
Paivio A., 1971. Imagery and Verbal Processes, New York, Holt,
Rinehart and Winston.
Paivio A., Csapo К.,
1969. Concrete-image and verbal memory codes, J. of Experimental Psychology,
80, 279-285.
Paivio A., Yiiille 1. С., Rogers Т. В., 1969. Noun imagery and meaningfulness
in free and serial recall, J. of Experimental Psychology, 79, 509514.
Penfield W., 1959. The interpretive cortex, Science, 129,
1719-1725.
Peterson L. R., Peterson M. J., 1959. Short-term retention of
individual verbal items, J. of .Experimental Psychology, 58, 193-198.
Pollack I., 1959. Message uncertainty and message reception, J. of the Acoustical
Society of America, 31, 1500-1508.
Posner M.I., 1969. Abstraction and the process of recognition. In: J. T. Spence
and G. H. Bower (eds.), Advances in Learning and Motivation (Vol. 3), New York,
Academic Press.
Posner M. I.. Boies S. }., Eichelman W. H., Taylor R. L., 1969. Retention of
visual and name codes of single letters, J. of Experimental Psychology, 79 (I,
Pt. 2).
Posner M. I.. Goldsmith R., Welton K. E., IT., 1967. Perceived distance and
the classification of distorted patterns, J. of Experimental Psychology, 73,
28-38.
Posner M. I., Keele S. W., 1968. On the genesis of abstract ideas, J. of Experimental
Psychology, 77,353-363.
Posner M. I., Konick A. F., 1966. On the role of interference in short-term
retention, J. of Experimental Psychology, 72, 221-231.
Posner M. I., Mitchell R. F., 1967. Chronometric analysis of classification,
Psychological Review, 74, 392-409.
Posner M. I., Rossman E., 1965. Effect of size and location of informational
transforms upon short-term retention, J. of Experimental Psychology, 70,496-505.
Postman L., 1972. A pragmatic view of organization theory.
In: E. Tulving and M. Donaldson (eds.). Organization of Memory, New York,
Academic Press.
Postman L., Keppel G., Stark K., 1965. Unlearning as a
function of the relationship between successive response classes, J. of
Experimental Psy. chology,69,lll-118.
Postman L., Phillips L., 1965.
Short-term temporal changes in free recall, Quarterly J. of Experimental
Psychology, 17, 132-138.
Postman L., Rail L., 1957. Retention as a function of the method of measurement,
University of California Publications in Psychology, Berkeley, 8,217-270.
(Postman L., Stark K.., 1969. Role of
response availability in transfer and interference, J. of Experimental
Psychology, 79, 168-177.
Postman L., Stark K., Fraser J., 1968. Temporal
changes in interference, J. of Verbal Learning and Verbal Behavior, 7,
672-694.
Postman L., Stark K., Henschel D., 1969. Conditions of recovery after unlearning,
J. of Experimental Psychology Monograph, 82 (I, Pt. 2).
Postman L., Underwood B. 1., 1973. Critical issues in interference theory,
Memory and Cognition, 1, 19-40.
Prytulak L. S., 1971. Natural language mediation, Cognitive Psychology, 2,
1-56.
Pylyshyn Z. W., 1973. What the
minds eye tells the minds brain: A critique of mental imagery, Psychological
Bulletin, 80, I-24.
QuilUan M. R., 1969. The teachable language
comprehender: A simulation program and theory of language, Communications of
the Association for Computing Machinery, 12, 459-476.
Reicher G. M.,
1969. Perceptual recognition as a function of meaningfulness of stimulus
material, J. of Experimental Psychology, 81, 275-280.
Reitman J. S., 1971. Mechanisms of forgetting in short-term memory. Cognitive Psychology, 2, 185-195.
Reitman ]. S., 1974. Without
surreptitious rehearsal, information in shortterm memory decays, J. of
Verbal Learning and Verbal Behavior, 13, 365-377.
Rips L. L, Shoben E.
J., Smith E. E., 1973. Semantic distance and the verification of semantic
relations, J. of Verbal Learning and Verbal Behavior, 12,1-20.
Rohwer
W. D., ]r., 1966. Verbal and visual elaboration in paired associate
learning. Project Literacy Reports, Cornell University, No. 7, 18-28.
Rosch E., 1973. On the internal structure of perceptual and semantic categories. In: T. E. Moore (ed.). Cognitive Development and Acquisition of
Language, New York, Academic Press.
Rumelhart D. E., 1971. A
multicomponent theory of perception of briefly exposed visual displays, J.
of Mathematical Psychology, 91, 326-332.
Rumelhart D. E., Lindsay P. H.,
Norman D. A., 1972. A process model for long-term memory. In: E. Tulving and
W. Donaldson (eds.), Organization of Memory, New York, Academic Press.
Rundus D., 1971. Analysis of rehearsal processes in free recall, J. of Experimental Psychology, 89,63-77.
Rundus D., Atkinson R. C., 1970.
Rehearsal processes in free recall: A procedure for direct observation, J.
of Verbal Learning and Verbal Behavior, 9,99-105.
Sac/is /. D. S.,
1967. Recognition memory for syntactic and semantic aspects of connected
discourse. Perception and Psychophysics, 2, 437-442.
Salzinger K., Portnoy
S., Feldman R. S., 1962. The effect of order of approximation to the
statistical structure of English on the emission of verbal responses, J. of
Experimental Psychology, 64, 52-57.
Schwartz M., 1969. Instructions to use
verbal mediators in paired-associate learning, J. of Experimental
Psychology, 79, I-5.
Selfridge 0. G., 1959. Pandemonium: A paradigm for
learning. In: The Mechanisation of Thought Processes, London, H. M.
Stationery Office.
Shepard R. N., 1966. Learning and recall as
organization and search, J. of Verbal Learning and Verbal Behavior, 5,
201-204.
Shepard R. N., 1967. Recognition memory for words, sentences and
pictures, J. of Verbal Learning and Verbal Behavior, 6, 156-163.
Shepard
R. N., 1968. Cognitive psychology: A review of the book by U. Neisser,
American J. of Psychology, 81, 285-289.
Shepard R. N., Chipman S., 1970.
Second-order isomorphism of internal representations: Shapes of states,
Cognitive Psychology, I, I-17.
Shepard R. N., Metzler }., 1971. Mental
rotation of three-dimensional objects, Science, 171,701-703.
Shepard R.
N., Teghtsoonian M., 1961. Retention of information under conditions
approaching a steady state, J. of Experimental Psychology, 62, 302-309.
Shiffrin R. М-, 1970. Memory search. In: D. A. Norman (ed.). Models of
Human Memory, New York, Academic Press.
Shiffrin R. M., 1973.
Information persistence in short-term memory, J. of Experimental Psychology,
100, 39-49.
Shulman H. G., 1971. Similarity effects in short-term memory.
Psychological Bulletin, 75, 399-415.
Shulman H. G., 1972. Semantic
confusion errors in short-term memory, J. of Verbal Learning and Verbal
Behavior, II, 221-227.
Simon H. A.. 1974. How big is a chunk? Science, 183,
482-488.
Simon H. A., Barenfeld M., 1969. Information-processing analysis of
perceptual processes in problem solving, Psychological Review, 76, 473483.
Simon Н. A., Gilmartin К.., 1973. A
simulation of memory for chess positions, Cognitive Psychology, 5, 29-46.
Slamecka N. 1., 1960a. Retroactive inhibition of connected discourse as
a function of practice level, J. of Experimental Psychology, 59, 104108.
Slamecka N. }., 1960b. Retroactive inhibition of connected
discourse as a function of similarity of topic, J. of Experimental
Psychology, 60, 245-249.
Slamecka N. }., 1966. Differentiation versus
unlearning of verbal associations, J. of Experimental Psychology, 71,
822-828.
Slamecka N. J., 1968. An examination of trace storage in free
recall, J. of Experimental Psychology, 76, 504-513.
Slamecka N. J., 1969. Testing for associative storage in multitrial recall,
J. of Experimental Psychology, 81, 557-560.
Smith E. E., 1967. Effects of
familiarity on stimulus recognition and categorization, J. of Experimental
Psychology, 74, 324-332.
Smith E. E., Shoben E. J., Rips L. J., 1974. Structure and process in semantic
memory: A featural model for semantic decision, Psychological Review, 81,214-241.
Smith E. E., Spoehr K..
R.., 1974. The perception of printed English: A theoretical perspective.
In: B. Н. Kantowitz (ed.), Human Information Processing: Tutorials in
Performance and Cognition, Potomac, Md., Eribaum Press.
Sperling 0.,
1960. The information available in brief visual presentations, Psychological
Monographs, 74 (Whole No. 498).
Sperling G., 1967. Successive approximations
to a model for short-term memory, Acta Psychologica, 27, 285-292.
Sperling G., Speelman R. G., 1970. Acoustic similarity and auditory shortterm memory: Experiments and a model. In: D. A. Norman (ed.), Models
of Human Memory, New York, Academic Press.
Standing L., Conezio J., Haber R.
N., 1970. Perception and memory for pictures: Single-trial learning of
2560 visual stimuli, Psychonomic Science, 19, 73-74.
Sternberg S., 1966.
High-speed scanning in human memory. Science, 153, 652-654.
Sternberg
S., 1967. Two operations in character recognition: Some evidence from RT
measurement. Perception and Psychophysics, 2, 45-53.
Sternberg S., 1969.
Memory-scanning: Mental processes revealed by reactiontime experiments,
American Scientist, 57, 421-457.
Tejirian E., 1968. Syntactic and semantic
structure in the recall of orders of approximation to English, J. of Verbal
Learning and Verbal Behavior, 7,1010-1015.
Theios }., Smith P. G.,
Haviland S. E., Traupmann }., Moy M. C., 1973. Memory scanning as a serial
self-terminating process, J. of Experimental Psychology, 97,323-336.
Thomson D. №.., Tulving E., 1970. Associative encoding and retrieval:
Weak and strong cues, J. of Experimental Psychology, 86, 255262.
Thorndike E. L., Large /., 1944. The Teachers Word Book of 30,000 Words,
New York, Teachers College Press, Columbia University.
Tieman D. G"
1971. Recognition memory for comparative sentences, Unpublished doctoral
dissertation, Stanford University.
Townsend }. Т.. 1972. Some results
concerning the identifiability of parallel and serial processes, British J.
of Mathematical and Statistical Psychology, 25,168-199.
Treisman A.
M., 1960. Contextual cues in selective listening, Quarterly J. of
Experimental Psychology, 12, 242-248.
Treisman А. M., 1964. Verbal cues, language and meaning in selective
attention, American J. of Psychology, 77, 206-219.
Tulving E., 1962.
Subjective organization in free recall of words,.
Psychological
Review, 69, 344-354.
Tulving E., 1964. Intratrial and intertrial retention:
Notes towards a theory of free recall verbal learning. Psychological Review,
71, 219-237.
Tulving E., 1972. Episodic and semantic memory. In; E. Tulving
and W. Donaldson (eds.). Organization of Memory, New York, Academic
Press.
Tulving E., Osier S., 1968. Effectiveness of retrieval cues in
memory for words, J. of Experimental Psychology, 77, 593-601.
Tulving E., Patkau S. E., 1962. Concurrent effects of contextual constraint
and
word frequency on immediate recall and learning of verbal material,
Canadian J. of Psychology, 16, 83-95.
Tulving E., Pearlstone Z., 1966.
Availability versus accessibility of information in memory for words, J.
of Verbal Learning and Verbal Behavior, 5, 381-391.
Tulving E., Thompson
D. M., 1973. Encoding specificity and retrieval processes in episodic
memory. Psychological Review, 80, 352-373.
Underwood В. J., 1948a. Retroactive and proactive inhibition after five andi
forty-eight hours, J. of Experimental Psychology, 38, 29-38.
Underwood В. J., 1948b. recovery of verbal associations, J. of
Experimental Psychology, 38, 429-439.
Underwood В. J., 1949. Proactive inhibition as a function of time and degree
of prior learning, J. of Experimental Psychology, 39, 24-34.
Underwood. В. J., 1965. False recognition produced by implicit verbal
responses, J. of Experimental Psychology, 70, 122-129.
Underwood В.
J., Ekstrand В. R., 1966. An analysis of some shortcomings.
in the
interference theory of forgetting. Psychological Review, 73, 540549.
Underwood В. J., Freund J. S., 1968. Errors in recognition learning and
retention, J. of Experimental Psychology, 78, 55-63.
Underwood В. J.,
Freund }. S., 1970. Word frequency and short-term recognition memory,
American J. of Psychology, 83, 343-351.
Underwood В. J., Postman L., 1960.
Extraexperiroental sources of interference in forgetting, Psychological
Review, 67, 73-95.
Wanner Н. E., 1968. On remembering, forgetting and
understanding sentences: A study of the deep structure hypothesis.
Unpublished doctoral dissertation, Harvard University.
Watkins M. J.,
Watkins О. С., 1973. The postcategorical status of the modality effect in
serial recall, J. of Experimental Psychology, 99, 226230.
Watkins M.
J., Watkins О. С., Craik F. 1. M., Mazuryk G., 1973. Effect of nonverbal
distraction on short-term storage, J. of Experimental Psychology,
101,296-300.
Waugh N. С., Norman D. A., 1965. Primary memory, Psychological Review, 72,89-104.
Waugh N. С., Norman D. A., 1968. The measurement of
interference in primary memory, J. of Verbal Learning and Verbal Behavior,
7, 617626.
Weber D. J., Castleman J., 1970. The time it takes to imagine, Perception and
Psychophysics, 8, 165-168.
Wheeler D. D., 1970.
Processes in word rei:ignition, Cognitive Psychology, 1, 59-85.
Wickelgren W. A., 1965. Acoustic similarity and retroactive interference in
short-term memory, J. of Verbal Learning and Verbal Behavior, 4, 53-61.
Wickelgren W. А., 1966. Distinctive features and errors In short-term memory
for English consonants, J. of the Acoustical Society of America, 39, 388-398.
Wickelgren W. A., 1973. The
long and the short of memory, Psychological Bulletin, 80,425-438.
Wickens D. D., 1972. Characteristics of word encoding. In: A. W. Melton
and E. Martin (eds.), Coding Processes in Human Memory, New York, V. H.
Winston and Sons.
Wickens D. D., Born D. G.. Alien C. K., 1963. Proactive
inhibition and item similarity in short-term memory, J. of Verbal Learning
and Verbal Behavior, 2,440-445.
Wilkins A., 1971. Conjoint frequency,
category size and categorization time, J. of Verbal Learning and Verbal
Behavior, 10, 382-385.
Winograd E., 1968. List differentiation as a function
of frequency and retention interval, J. of Experimental Psychology, 76 (2,
Pt. 2.).
Wiseman G., Neisser U., 1971. Perceptual organization as a
determinant of visual recognition memory. Paper presented at meeting of the
Eastern Psychological Assn.
Wood G., 1972, Organizational processes and
free recall. In: E. Tulving and W. Donaldson (eds.). Organization of Memory,
New York, Academic Press.
Wood G., Underwood B. J., 1967. Implicit
responses and conceptual similarity, J. of Verbal Learning and Verbal
Behavior, 6, I-10.
Woodward A. E., }r., Bjork R. A., longevnard R. H., lr.,
1973. Recall and recognition as a function of primary rehearsal, J. of
Verbal Learning and Verbal Behavior, 12, 608-617.
Zlusne L., 1970. Visual Perception of Form, New York, Academic Press.
|
